mapreduce分区
本次分区是采用项目垃圾分类的csv文件,按照小于4的分为一个文件,大于等于4的分为一个文件
源代码:
PartitionMapper.java:
package cn.idcast.partition; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException;
/*
K1:行偏移量 LongWritable
v1:行文本数据 Text k2:行文本数据 Text
v2:NullWritable
*/ public class PartitionMapper extends Mapper<LongWritable,Text, Text, NullWritable> {
//map方法将v1和k1转为k2和v2
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
context.write(value,NullWritable.get());
}
}
PartitionerReducer.java:
package cn.idcast.partition; import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException; /*
k2: Text
v2: NullWritable k3: Text
v3: NullWritable
*/
public class PartitionerReducer extends Reducer<Text, NullWritable,Text, NullWritable> {
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key,NullWritable.get());
}
}
MyPartitioner.java:
package cn.idcast.partition; import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner; public class MyPartitioner extends Partitioner<Text, NullWritable> {
/*
1:定义分区规则
2:返回对应的分区编号 */
@Override
public int getPartition(Text text, NullWritable nullWritable, int numPartitions) {
//1:拆分行文本数据(k2),获取垃圾分类数据的值
String[] split = text.toString().split(",");
String numStr=split[1]; //2:判断字段与15的关系,然后返回对应的分区编号
if(Integer.parseInt(numStr)>=4){
return 1;
}
else{
return 0;
}
}
}
JobMain.java:
package cn.idcast.partition; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; import java.net.URI; public class JobMain extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
//1:创建Job任务对象
Job job = Job.getInstance(super.getConf(), "partition_mapreduce");
//如果打包运行出错,则需要加该配置
job.setJarByClass(cn.idcast.mapreduce.JobMain.class);
//2:对Job任务进行配置(八个步骤)
//第一步:设置输入类和输入的路径
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("hdfs://node1:8020/input"));
//第二部:设置Mapper类和数据类型(k2和v2)
job.setMapperClass(PartitionMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
//第三步:指定分区类
job.setPartitionerClass(MyPartitioner.class);
//第四、五、六步
//第七步:指定Reducer类和数据类型(k3和v3)
job.setReducerClass(PartitionerReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//设置ReduceTask的个数
job.setNumReduceTasks(2);
//第八步:指定输出类和输出路径
job.setOutputFormatClass(TextOutputFormat.class);
Path path=new Path("hdfs://node1:8020/out/partition_out");
TextOutputFormat.setOutputPath(job,path);
//获取FileSystem
FileSystem fs = FileSystem.get(new URI("hdfs://node1:8020/partition_out"),new Configuration());
//判断目录是否存在
if (fs.exists(path)) {
fs.delete(path, true);
System.out.println("存在此输出路径,已删除!!!");
}
//3:等待任务结束
boolean bl = job.waitForCompletion(true);
return bl?0:1;
} public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
//启动一个job任务
int run = ToolRunner.run(configuration, new JobMain(), args);
System.exit(run);
}
}
在hadoop或者本地运行结果:
1.均为4-16的文件
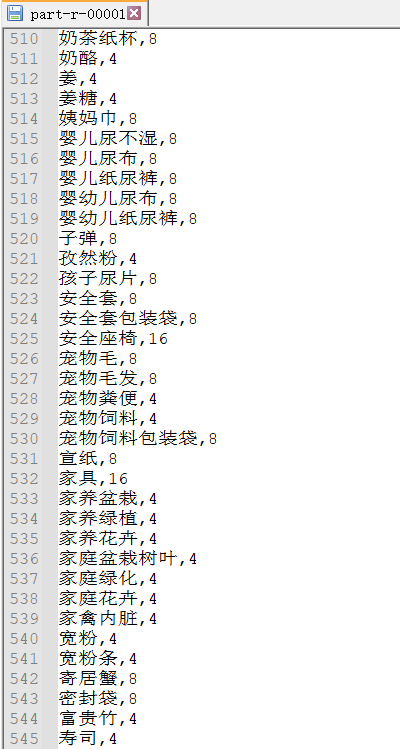
2.均为1-3的文件
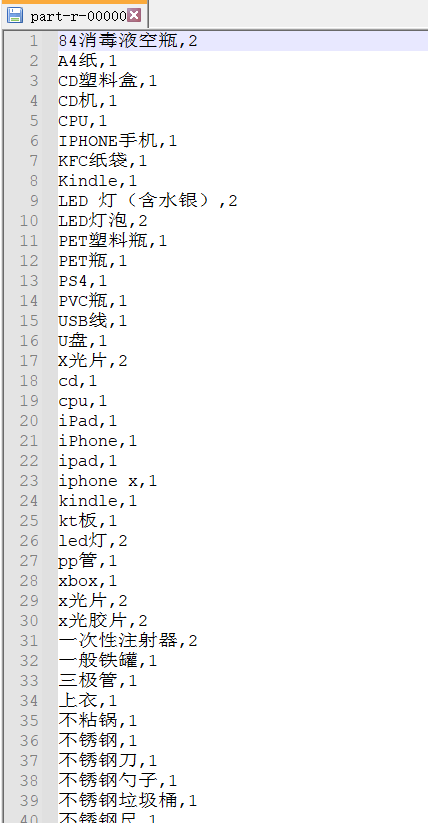
mapreduce分区的更多相关文章
- Hadoop Mapreduce分区、分组、二次排序过程详解[转]
原文地址:Hadoop Mapreduce分区.分组.二次排序过程详解[转]作者: 徐海蛟 教学用途 1.MapReduce中数据流动 (1)最简单的过程: map - reduce (2) ...
- hadoop2.2.0 MapReduce分区
package com.my.hadoop.mapreduce.partition; import java.util.HashMap;import java.util.Map; import org ...
- Hadoop Mapreduce分区、分组、二次排序
1.MapReduce中数据流动 (1)最简单的过程: map - reduce (2)定制了partitioner以将map的结果送往指定reducer的过程: map - partiti ...
- MapReduce分区和排序
一.排序 排序: 需求:根据用户每月使用的流量按照使用的流量多少排序 接口-->WritableCompareable 排序操作在hadoop中属于默认的行为.默认按照字典殊勋排序. 排序的分类 ...
- MapReduce分区的使用(Partition)
MapReduce中的分区默认是哈希分区,根据map输出key的哈希值做模运算,如下 int result = key.hashCode()%numReduceTask; 如果我们需要根据业务需求来将 ...
- Hadoop Mapreduce分区、分组、二次排序过程详解
转载:http://blog.tianya.cn/m/post.jsp?postId=53271442 1.MapReduce中数据流动 (1)最简单的过程: map - reduce (2)定制了 ...
- MapReduce分区数据倾斜
什么是数据倾斜? 数据不可避免的出现离群值,并导致数据倾斜,数据倾斜会显著的拖慢MR的执行速度 常见数据倾斜有以下几类 1.数据频率倾斜 某一个区域的数据量要远远大于其他区域 2.数据大小倾斜 ...
- YARN集群的mapreduce测试(五)
将user表计算后的结果分区存储 测试准备: 首先同步时间,然后master先开启hdfs集群,再开启yarn集群:用jps查看: master上: 先有NameNode.SecondaryNameN ...
- spark shuffle:分区原理及相关的疑问
一.分区原理 1.为什么要分区?(这个借用别人的一段话来阐述.) 为了减少网络传输,需要增加cpu计算负载.数据分区,在分布式集群里,网络通信的代价很大,减少网络传输可以极大提升性能.mapreduc ...
随机推荐
- sprintf的用法总结
大概知道sprintf的用法,今天在CSDN上看到一篇关于sprintf比较好的总结,现在抄下来,emmmmmmm....... srpintf()函数的功能非常强大:效率比一些字符串操作函数要高:而 ...
- JZ-025-复杂链表的复制
复杂链表的复制 题目描述 输入一个复杂链表(每个节点中有节点值,以及两个指针,一个指向下一个节点,另一个特殊指针random指向一个随机节点),请对此链表进行深拷贝, 并返回拷贝后的头结点.(注意,输 ...
- 我的hacker标杆
前言:我为什么用"标杆"而不是用偶像来做题目呢?因为在我的心中,值得我学习的黑客绝不是仅仅值得成为我个人的偶像,更应该成为业界的标杆. 国外篇: 丹尼斯·里奇 评价:克尼汉评价道: ...
- 重磅 | 腾讯云服务网格开源项目 Aeraki Mesh 加入 CNCF 云原生全景图
作者 赵化冰,腾讯云工程师,Aeraki Mesh 创始人,Istio member,Envoy contributor,目前负责 Tencent Cloud Mesh 研发工作. 摘要 近日,腾讯云 ...
- think php 上下架修改+jq静态批量删除+ajax删除+全选
视图代码: <!doctype html> <html lang="en"> <head> <meta charset="UTF ...
- JS类型判断&原型链
JS类型检测主要有四种 1.typeof Obj 2.L instanceof R 3.Object.prototype.toString.call/apply(); 4.Obj.constructo ...
- typora 使用Markdown语法编辑文本
MarkDown语法 标题 一级标题# 二级标题## ============= 三级标题### 四级标题 依此类推 Markdown 段落格式 Markdown 段落没有特殊的格式,直接编写文字,段 ...
- jdbc model 代码示例
package com.gylhaut.model; import java.util.Date; public class Goddess { @Override public String toS ...
- Java案例——字符串中的数据排序
需求:有一个字符串"9 1 2 7 4 6 3 8 5 0",请编写程序实现从小到大数据排序 分析:最重要的部分是如何将字符串中的数据取出来 1.定义一个字符串为"9 1 ...
- 【Linux】apt软件管理和远程登录
镜像下载.域名解析.时间同步请点击 阿里云开源镜像站 1. apt 介绍 apt 是 Advanced Packaging Tool 的简称,是一款安装包管理工具.在 Ubuntu 下,可以使用 ap ...