mapreduce分区
本次分区是采用项目垃圾分类的csv文件,按照小于4的分为一个文件,大于等于4的分为一个文件
源代码:
PartitionMapper.java:
package cn.idcast.partition; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException;
/*
K1:行偏移量 LongWritable
v1:行文本数据 Text k2:行文本数据 Text
v2:NullWritable
*/ public class PartitionMapper extends Mapper<LongWritable,Text, Text, NullWritable> {
//map方法将v1和k1转为k2和v2
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
context.write(value,NullWritable.get());
}
}
PartitionerReducer.java:
package cn.idcast.partition; import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException; /*
k2: Text
v2: NullWritable k3: Text
v3: NullWritable
*/
public class PartitionerReducer extends Reducer<Text, NullWritable,Text, NullWritable> {
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key,NullWritable.get());
}
}
MyPartitioner.java:
package cn.idcast.partition; import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner; public class MyPartitioner extends Partitioner<Text, NullWritable> {
/*
1:定义分区规则
2:返回对应的分区编号 */
@Override
public int getPartition(Text text, NullWritable nullWritable, int numPartitions) {
//1:拆分行文本数据(k2),获取垃圾分类数据的值
String[] split = text.toString().split(",");
String numStr=split[1]; //2:判断字段与15的关系,然后返回对应的分区编号
if(Integer.parseInt(numStr)>=4){
return 1;
}
else{
return 0;
}
}
}
JobMain.java:
package cn.idcast.partition; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; import java.net.URI; public class JobMain extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
//1:创建Job任务对象
Job job = Job.getInstance(super.getConf(), "partition_mapreduce");
//如果打包运行出错,则需要加该配置
job.setJarByClass(cn.idcast.mapreduce.JobMain.class);
//2:对Job任务进行配置(八个步骤)
//第一步:设置输入类和输入的路径
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("hdfs://node1:8020/input"));
//第二部:设置Mapper类和数据类型(k2和v2)
job.setMapperClass(PartitionMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
//第三步:指定分区类
job.setPartitionerClass(MyPartitioner.class);
//第四、五、六步
//第七步:指定Reducer类和数据类型(k3和v3)
job.setReducerClass(PartitionerReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//设置ReduceTask的个数
job.setNumReduceTasks(2);
//第八步:指定输出类和输出路径
job.setOutputFormatClass(TextOutputFormat.class);
Path path=new Path("hdfs://node1:8020/out/partition_out");
TextOutputFormat.setOutputPath(job,path);
//获取FileSystem
FileSystem fs = FileSystem.get(new URI("hdfs://node1:8020/partition_out"),new Configuration());
//判断目录是否存在
if (fs.exists(path)) {
fs.delete(path, true);
System.out.println("存在此输出路径,已删除!!!");
}
//3:等待任务结束
boolean bl = job.waitForCompletion(true);
return bl?0:1;
} public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
//启动一个job任务
int run = ToolRunner.run(configuration, new JobMain(), args);
System.exit(run);
}
}
在hadoop或者本地运行结果:
1.均为4-16的文件
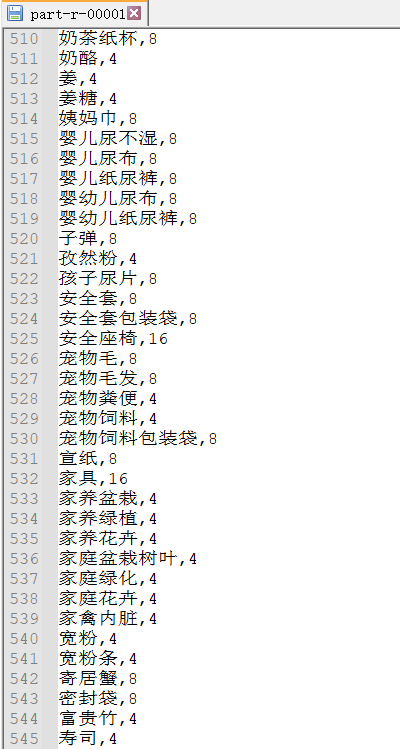
2.均为1-3的文件
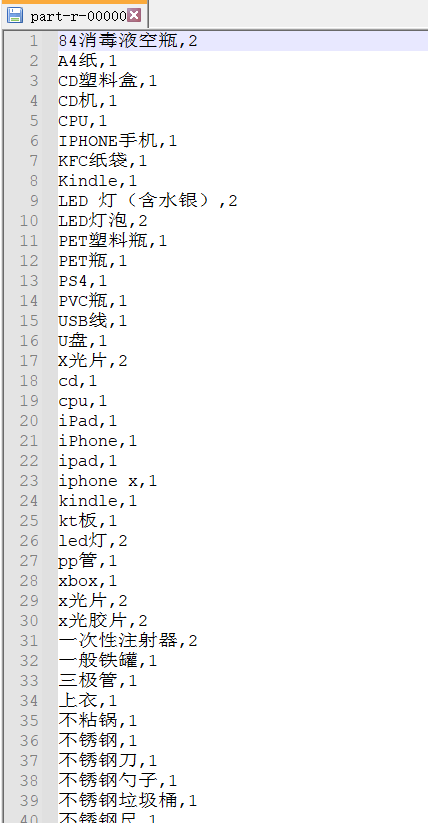
mapreduce分区的更多相关文章
- Hadoop Mapreduce分区、分组、二次排序过程详解[转]
原文地址:Hadoop Mapreduce分区.分组.二次排序过程详解[转]作者: 徐海蛟 教学用途 1.MapReduce中数据流动 (1)最简单的过程: map - reduce (2) ...
- hadoop2.2.0 MapReduce分区
package com.my.hadoop.mapreduce.partition; import java.util.HashMap;import java.util.Map; import org ...
- Hadoop Mapreduce分区、分组、二次排序
1.MapReduce中数据流动 (1)最简单的过程: map - reduce (2)定制了partitioner以将map的结果送往指定reducer的过程: map - partiti ...
- MapReduce分区和排序
一.排序 排序: 需求:根据用户每月使用的流量按照使用的流量多少排序 接口-->WritableCompareable 排序操作在hadoop中属于默认的行为.默认按照字典殊勋排序. 排序的分类 ...
- MapReduce分区的使用(Partition)
MapReduce中的分区默认是哈希分区,根据map输出key的哈希值做模运算,如下 int result = key.hashCode()%numReduceTask; 如果我们需要根据业务需求来将 ...
- Hadoop Mapreduce分区、分组、二次排序过程详解
转载:http://blog.tianya.cn/m/post.jsp?postId=53271442 1.MapReduce中数据流动 (1)最简单的过程: map - reduce (2)定制了 ...
- MapReduce分区数据倾斜
什么是数据倾斜? 数据不可避免的出现离群值,并导致数据倾斜,数据倾斜会显著的拖慢MR的执行速度 常见数据倾斜有以下几类 1.数据频率倾斜 某一个区域的数据量要远远大于其他区域 2.数据大小倾斜 ...
- YARN集群的mapreduce测试(五)
将user表计算后的结果分区存储 测试准备: 首先同步时间,然后master先开启hdfs集群,再开启yarn集群:用jps查看: master上: 先有NameNode.SecondaryNameN ...
- spark shuffle:分区原理及相关的疑问
一.分区原理 1.为什么要分区?(这个借用别人的一段话来阐述.) 为了减少网络传输,需要增加cpu计算负载.数据分区,在分布式集群里,网络通信的代价很大,减少网络传输可以极大提升性能.mapreduc ...
随机推荐
- QUIC协议详解
声明 本文可以自由转载但需注明原始链接.本文为本人原创,作者LightningStar,原文发表在博客园.本文主体内容参考论文[1]完成. 介绍 QUIC,发音同quick,是"Quick ...
- LeetCode-005-最长回文子串
最长回文子串 题目描述:给你一个字符串 s,找到 s 中最长的回文子串. 示例说明请见LeetCode官网. 来源:力扣(LeetCode) 链接:https://leetcode-cn.com/pr ...
- tp6 的安装步骤 及简易命令
1:https://www.kancloud.cn/manual/thinkphp6_0/1037481 官网下载 composer create-project topthink/think tp6 ...
- HBase海量数据高效入仓解决方案
一.方案背景 现阶段部分业务数据存储在HBase中,这部分数据体量较大,达到数十亿.大数据需要增量同步这部分业务数据到数据仓库中,进行离线分析,目前主要的同步方式是通过HBase的hive映射表来实现 ...
- ubuntu 16.04和18.04 忘记登录密码的解决办法
1:开机按Shift键,出现如下界面.(手速要快,Shift键要按时间久一点)选择第二项 2:按回车键进入如下界面,然后选中有recovery mode的选项(第三项) 3:按e进入如下界面,并找到图 ...
- Git 常见错误 之 error:error: src refspec main does not match any/ error: failed to push some refs to 简单解决
错误产生的原因:Github 工程默认名为了 main 由于受到"Black Lives Matter"运动的影响,GitHub 从今年 10 月 1 日起,在该平台上创建的所有新 ...
- vue路由-router
VueRouter基础 vue路由的注册 导入 <script src="https://unpkg.com/vue-router/dist/vue-router.js"&g ...
- python+pytest接口自动化(10)-session会话保持
在接口测试的过程中,经常会遇到有些接口需要在登录的状态下才能请求,否则会提示请登录,那么怎样解决呢? 上一篇文章我们介绍了Cookie绕过登录,其实这就是保持登录状态的方法之一. 另外一种方式则是通过 ...
- C#: .net序列化及反序列化 [XmlElement(“节点名称”)] [XmlAttribute(“节点属性”)] (上篇)
.net序列化及反序列化 序列化是指一个对象的实例可以被保存,保存成一个二进制串,当然,一旦被保存成二进制串,那么也可以保存成文本串了.比如,一个计数器,数值为2,我们可以用字符串"2&qu ...
- 安装docker-compose 报错解决