Spark 中的宽依赖和窄依赖
Spark中RDD的高效与DAG图有着莫大的关系,在DAG调度中需要对计算过程划分stage,而划分依据就是RDD之间的依赖关系。针对不同的转换函数,RDD之间的依赖关系分类窄依赖(narrow dependency)和宽依赖(wide dependency, 也称 shuffle dependency).
宽依赖与窄依赖
- 窄依赖是指父RDD的每个分区只被子RDD的一个分区所使用,子RDD分区通常对应常数个父RDD分区(O(1),与数据规模无关)
- 相应的,宽依赖是指父RDD的每个分区都可能被多个子RDD分区所使用,子RDD分区通常对应所有的父RDD分区(O(n),与数据规模有关)
宽依赖和窄依赖如下图所示:
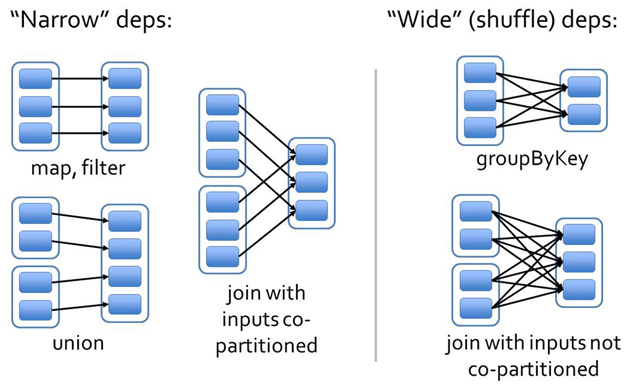
相比于宽依赖,窄依赖对优化很有利 ,主要基于以下两点:
宽依赖往往对应着shuffle操作,需要在运行过程中将同一个父RDD的分区传入到不同的子RDD分区中,中间可能涉及多个节点之间的数据传输;而窄依赖的每个父RDD的分区只会传入到一个子RDD分区中,通常可以在一个节点内完成转换。
当RDD分区丢失时(某个节点故障),spark会对数据进行重算。
- 对于窄依赖,由于父RDD的一个分区只对应一个子RDD分区,这样只需要重算和子RDD分区对应的父RDD分区即可,所以这个重算对数据的利用率是100%的;
- 对于宽依赖,重算的父RDD分区对应多个子RDD分区,这样实际上父RDD 中只有一部分的数据是被用于恢复这个丢失的子RDD分区的,另一部分对应子RDD的其它未丢失分区,这就造成了多余的计算;更一般的,宽依赖中子RDD分区通常来自多个父RDD分区,极端情况下,所有的父RDD分区都要进行重新计算。
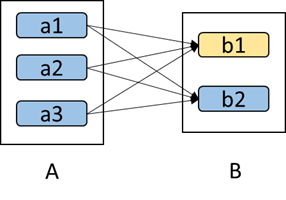
如下图所示,b1分区丢失,则需要重新计算a1,a2和a3,这就产生了冗余计算(a1,a2,a3中对应b2的数据)。
以下是文章 RDD:基于内存的集群计算容错抽象 中对宽依赖和窄依赖的对比。
区分这两种依赖很有用。首先,窄依赖允许在一个集群节点上以流水线的方式(pipeline)计算所有父分区。例如,逐个元素地执行map、然后filter操作;而宽依赖则需要首先计算好所有父分区数据,然后在节点之间进行Shuffle,这与MapReduce类似。第二,窄依赖能够更有效地进行失效节点的恢复,即只需重新计算丢失RDD分区的父分区,而且不同节点之间可以并行计算;而对于一个宽依赖关系的Lineage图,单个节点失效可能导致这个RDD的所有祖先丢失部分分区,因而需要整体重新计算。
【误解】之前一直理解错了,以为窄依赖中每个子RDD可能对应多个父RDD,当子RDD丢失时会导致多个父RDD进行重新计算,所以窄依赖不如宽依赖有优势。而实际上应该深入到分区级别去看待这个问题,而且重算的效用也不在于算的多少,而在于有多少是冗余的计算。窄依赖中需要重算的都是必须的,所以重算不冗余。
窄依赖的函数有:map, filter, union, join(父RDD是hash-partitioned ), mapPartitions, mapValues
宽依赖的函数有:groupByKey, join(父RDD不是hash-partitioned ), partitionBy
参考:
RDD:基于内存的集群计算容错抽象
Spark技术内幕:Stage划分及提交源码分析
Spark分布式计算和RDD模型研究
SPARK 阔依赖 和窄依赖 transfer action lazy策略之间的关系
Spark 中的宽依赖和窄依赖的更多相关文章
- Spark --【宽依赖和窄依赖】
前言 Spark中RDD的高效与DAG图有着莫大的关系,在DAG调度中需要对计算过程划分stage,暴力的理解就是stage的划分是按照有没有涉及到shuffle来划分的,没涉及的shuffle的都划 ...
- Spark宽依赖、窄依赖
在Spark中,RDD(弹性分布式数据集)存在依赖关系,宽依赖和窄依赖. 宽依赖和窄依赖的区别是RDD之间是否存在shuffle操作. 窄依赖 窄依赖指父RDD的每一个分区最多被一个子RDD的分区所用 ...
- Spark剖析-宽依赖与窄依赖、基于yarn的两种提交模式、sparkcontext原理剖析
Spark剖析-宽依赖与窄依赖.基于yarn的两种提交模式.sparkcontext原理剖析 一.宽依赖与窄依赖 二.基于yarn的两种提交模式深度剖析 2.1 Standalne-client 2. ...
- 大数据开发-从cogroup的实现来看join是宽依赖还是窄依赖
前面一篇文章提到大数据开发-Spark Join原理详解,本文从源码角度来看cogroup 的join实现 1.分析下面的代码 import org.apache.spark.rdd.RDD impo ...
- Spark RDD概念学习系列之RDD的依赖关系(宽依赖和窄依赖)(三)
RDD的依赖关系? RDD和它依赖的parent RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency). 1)窄依赖指的是每 ...
- 030 RDD Join中宽依赖与窄依赖的判断
1.规律 如果JoinAPI之前被调用的RDD API是宽依赖(存在shuffle), 而且两个join的RDD的分区数量一致,join结果的rdd分区数量也一样,这个时候join api是窄依赖 除 ...
- 小记--------spark的宽依赖与窄依赖分析
窄依赖: Narrow Dependency : 一个RDD对它的父RDD,只有简单的一对一的依赖关系.RDD的每个partition仅仅依赖于父RDD中的一个partition,父RDD和子RDD的 ...
- spark-宽依赖和窄依赖
一.窄依赖(Narrow Dependency,) 即一个RDD,对它的父RDD,只有简单的一对一的依赖关系.也就是说, RDD的每个partition ,仅仅依赖于父RDD中的一个partition ...
- spark 划分stage Wide vs Narrow Dependencies 窄依赖 宽依赖 解析 作业 job stage 阶段 RDD有向无环图拆分 任务 Task 网络传输和计算开销 任务集 taskset
每个job被划分为多个stage.划分stage的一个主要依据是当前计算因子的输入是否是确定的,如果是则将其分在同一个stage,从而避免多个stage之间的消息传递开销. http://spark. ...
随机推荐
- Object-c 中的数据类型
导航: 基本类型 ID 对象类型常见的有 对象类型 -NSLog -NSNumber -NSString和NSMutableString -NSArray和NSMutableArray -NSSe ...
- 【ExtJS】关于标准模块化封装组件
在此之前,自己封装自定义控件用的是这样的方式: Ext.define('My.XXX',{ extend: 'Ext.YYY', xtype: 'ZZZ', . . . items:[ ... ] } ...
- pycurl安装问题
pycurl安装问题 之前人写的代码中依赖pycurl,所以准备在ubuntu14.04.4 LTS系统上安装一下.发现了不少问题. Could not run curl-config 最开始遇到问题 ...
- hdu 1460 完数
注意:num1和num2的大小未知,需比较! 有两种方法: 法一:素数打印+素数分解(求因数和公式) #include<iostream> #include<cstring> ...
- javah找不到类文件
这样即可,在src目录下寻找类,类要写全,即包名.类名
- springboot定时任务,去掉指定日期
今天用springboot写到一个需求:每周定时发送任务,但是要避开法定节假日. 网上找了些博客看,主要参考了https://www.cnblogs.com/lic309/p/4089633.html ...
- 前端(五):JavaScript面向对象之内建对象
一.数据类型 js中数据类型分为两种,原始数据累次能够和引用数据类型. 1.原始数据类型 Undefined.Null.Boolean.Number.String是js中五种原始数据类型(primit ...
- DataTables添加额外的查询参数和删除columns等无用参数
//1.定义全局变量 var iStart = 0, searchParams={}; //2.配置datatable的ajax配置项 "ajax": { "url&qu ...
- js表单快速取值/赋值 快速生成下拉框
1.表单取值/赋值公共方法 //表单序列化:文本框的name字段和数据源一致<form id="myForm" onsubmit="return false;&qu ...
- Django—XSS及CSRF
一.XSS 跨站脚本攻击(Cross Site Scripting),为不和层叠样式表(Cascading Style Sheets, CSS)的缩写混淆,故将跨站脚本攻击缩写为XSS.恶意攻击者往W ...