python爬虫:抓取下载视频文件,合并ts文件为完整视频
1.获取m3u8文件
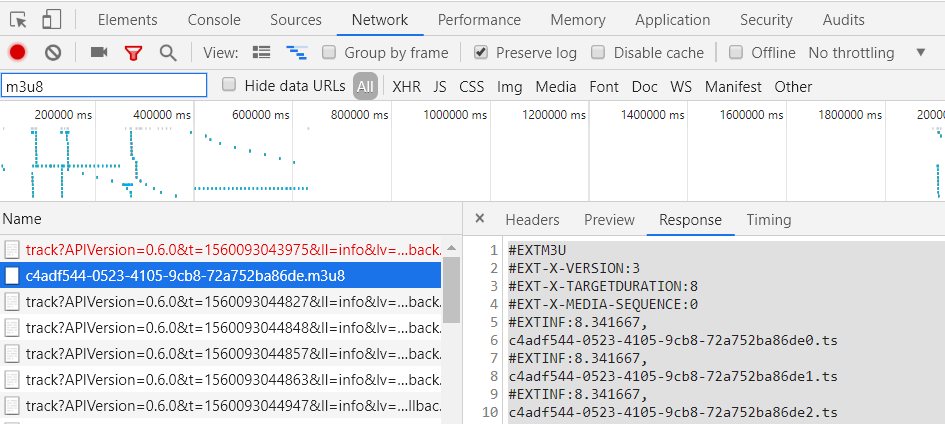
2.代码
"""
@author :Eric-chen
@contact :sygcrjgx@163.com
@time :2019/6/16 15:32
@desc :
"""
import requests
import threading
import datetime
import os count = 0; def Handler(start, end, url, filename):
headers = {'Origin': 'https://xdzy.andisk.com','Referer':'https://xdzy.andisk.com/andisk/app/videoviewFrame.html',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'} for i in filename[start:end]:
global count r = requests.get("https://bk.andisk.com/data/3048aa1f-b2fb-4fb7-b452-3ebc96c76374/res/" + i.replace("\n", ""),
headers=headers,
stream=True) with open("C:\\Users\\chen\\Desktop\\downloadfiles/" + i.replace("\n", ""), "wb") as code:
code.write(r.content)
count = count + 1
print("下载进度:%.2f" % (count / len(filename))) def download_file(url, num_thread=100):
cwd = os.getcwd() # 获取当前目录即dir目录下
print("------------------------current working directory------------------" + cwd)
f = open('index.m3u8', 'r', encoding='utf-8')
text_list = f.readlines()
s_list = []
for i in text_list:
if i.find('#EX') == -1:
s_list.append(i) f.close()
file_size = len(s_list) # 启动多线程写文件
part = file_size // num_thread # 如果不能整除,最后一块应该多几个字节
for i in range(num_thread):
start = part * i
if i == num_thread - 1: # 最后一块
end = file_size
else:
end = start + part t = threading.Thread(target=Handler, kwargs={'start': start, 'end': end, 'url': url, 'filename': s_list})
t.setDaemon(True)
t.start() # 等待所有线程下载完成
main_thread = threading.current_thread()
for t in threading.enumerate():
if t is main_thread:
continue
t.join() def before_merge():
cwd = os.getcwd() # 获取当前目录即dir目录下
print("------------------------current working directory------------------" + cwd)
f = open('index.m3u8', 'r', encoding='utf-8')
text_list = f.readlines()
files = []
for i in text_list:
if i.find('#EX') == -1:
files.append(i)
f.close()
tmp = []
for file in files[0:568]:
tmp.append(file.replace("\n", ""))
# 合并ts文件
# os.chdir("ts/")
shell_str = '+'.join(tmp)
# print(shell_str)
shell_str = 'copy /b ' + shell_str + ' 5.mp4'+'\n'+'del *.ts'
return shell_str
def wite_to_file(cmdString):
cwd = os.getcwd() # 获取当前目录即dir目录下
print("------------------------current working directory------------------"+cwd)
f = open("combined.cmd", 'w')
f.write(cmdString)
f.close() if __name__ == '__main__':
url = "https://bk.andisk.com/data/3048aa1f-b2fb-4fb7-b452-3ebc96c76374/res/";
# 下载:开始下载
start = datetime.datetime.now().replace(microsecond=0)
download_file(url)
end = datetime.datetime.now().replace(microsecond=0)
print(end - start)
# 结束下载
#合并小文件
cmd=before_merge();
#把合并命令写到文件中
wite_to_file(cmd);
3.把bat文件复制到下载的文件路径,执行
python爬虫:抓取下载视频文件,合并ts文件为完整视频的更多相关文章
- python 爬虫抓取心得
quanwei9958 转自 python 爬虫抓取心得分享 urllib.quote('要编码的字符串') 如果你要在url请求里面放入中文,对相应的中文进行编码的话,可以用: urllib.quo ...
- Python爬虫抓取东方财富网股票数据并实现MySQL数据库存储
Python爬虫可以说是好玩又好用了.现想利用Python爬取网页股票数据保存到本地csv数据文件中,同时想把股票数据保存到MySQL数据库中.需求有了,剩下的就是实现了. 在开始之前,保证已经安装好 ...
- Python爬虫----抓取豆瓣电影Top250
有了上次利用python爬虫抓取糗事百科的经验,这次自己动手写了个爬虫抓取豆瓣电影Top250的简要信息. 1.观察url 首先观察一下网址的结构 http://movie.douban.com/to ...
- python爬虫抓取哈尔滨天气信息(静态爬虫)
python 爬虫 爬取哈尔滨天气信息 - http://www.weather.com.cn/weather/101050101.shtml 环境: windows7 python3.4(pip i ...
- Python爬虫抓取某音乐网站MP3(下载歌曲、存入Sqlite)
最近右胳膊受伤,打了石膏在家休息.为了实现之前的想法,就用左手打字.写代码,查资料完成了这个资源小爬虫.网页爬虫, 最主要的是协议分析(必须要弄清楚自己的目的),另外就是要考虑对爬取的数据归类,存储. ...
- Python爬虫抓取糗百的图片,并存储在本地文件夹
思路: 1.观察网页,找到img标签 2.通过requests和BS库来提取网页中的img标签 3.抓取img标签后,再把里面的src给提取出来,接下来就可以下载图片了 4.通过urllib的urll ...
- Python 爬虫-抓取中小企业股份转让系统公司公告的链接并下载
系统运行系统:MAC 用到的python库:selenium.phantomjs等 由于中小企业股份转让系统网页使用了javasvript,无法用传统的requests.BeautifulSoup库获 ...
- Python爬虫 -- 抓取电影天堂8分以上电影
看了几天的python语法,还是应该写个东西练练手.刚好假期里面看电影,找不到很好的影片,于是有个想法,何不搞个爬虫把电影天堂里面8分以上的电影爬出来.做完花了两三个小时,撸了这么一个程序.反正蛮简单 ...
- Python爬虫抓取 python tutorial中文版,保存为word
看到了中文版的python tutorial,发现是网页版的,刚好最近在学习爬虫,想着不如抓取到本地 首先是网页的内容 查看网页源码后发现可以使用BeautifulSoup来获取文档的标题和内容,并保 ...
- python爬虫-抓取acg12动漫壁纸排行设置为桌面壁纸
ACG-wallpaper 初学python,之前想抓取P站的一些图片来着,然后发现acg12这里有专门的壁纸榜单,就写了个抓取壁纸作为mac桌面壁纸玩玩. 功能:抓取acg12壁纸榜单的动漫壁纸,并 ...
随机推荐
- idea返回git上历史版本
1.首先找到之前想要返回得版本号 2.直接下载此版本号即可 在这里填入1步骤得版本号即可检出,其实这个检出利时版本和检出其他分支是同一个道理
- spring boot 开静态资源访问,配置视图解析器
配置视图解析器spring.mvc.view.prefix=/pages/spring.mvc.view.suffiix= spring boot 开静态资源访问application.proerti ...
- Docker Toolbox 学习教程【转载】
最近在研究虚拟化,容器和大数据,所以从Docker入手,下面介绍一下在Windows下怎么玩转Docker.Docker本身在Windows下有两个软件,一个就是Docker,另一个是Docker T ...
- python之_init_()方法浅析
在python的类中,我们会经常看到一个类中的一个方法_init_(self) ,比如下面的一个例子: class Student(object): def __init__(self,name,we ...
- (转)pycharm autopep8配置
转:https://blog.csdn.net/BobYuan888/article/details/81943808 1.pip下载安装: 在命令行下输入以下命令安装autopep8 pip ins ...
- ZOJ 3329 One Person Game(概率DP,求期望)
http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemId=3754 题目大意: 有三个骰子,分别有K1,K2,K3个面,一次投掷可以得到三个 ...
- Mac下用命令行压缩和解压rar文件的方法
废话不多说,直接进入主题 第一步:下载RAR工具包,根据自己需要下载相对应的版本 第二步:解压对应的压在的压缩包rarosx-5.4.0.tar.gz(我下载的是5.4.0版本) 第三步:从终端进入到 ...
- Node.js - 使用 Express 和 http-proxy 进行反向代理
安装 Express 和 http-proxy npm install --save express http-proxy 反向代理代码 proxy.js var express = require( ...
- 拒绝从入门到放弃_《Python 核心编程 (第二版)》必读目录
目录 目录 关于这本书 必看知识点 最后 关于这本书 <Python 核心编程 (第二版)>是一本 Python 编程的入门书,分为 Python 核心(其实并不核心,应该叫基础) 和 高 ...
- Minimum Cost 【POJ - 2516】【网络流最小费用最大流】
题目链接 题意: 有N个商家它们需要货物源,还有M个货物供应商,N个商家需要K种物品,每种物品都有对应的需求量,M个商家每种物品都是对应的存货,然后再是K个N*M的矩阵表示了K个物品从供货商运送到商家 ...