Spark RDD理解-总结
1.spark是什么
快速、通用、可扩展的分布式计算引擎。
2. 弹性分布式数据集RDD
RDD(Resilient Distributed Dataset),是Spark中最基本的数据抽象结构,表示一个不可变、可分区、里面元素可以并行计算的集合。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
RDD的属性
- 一组分片(Partition),即数据集的基本组成单位。对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Core的数目。
- 一个计算每个分区的函数。Spark中RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。
- RDD之间的依赖关系。RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
- 一个Partitioner,即RDD的分片函数。当前Spark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。
- 一个列表,存储存取每个Partition的优先位置(preferred location)。对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置。
创建RDD的两种方式
1、由一个已经存在的Scala集合创建。
val rdd1 = sc.parallelize(Array(1,2,3,4,5,6,7,8))
2、由外部存储系统的数据集创建,包括本地的文件系统,还有所有Hadoop支持的数据集,比如HDFS、Cassandra、HBase等
val rdd2 = sc.textFile("hdfs://node1.itcast.cn:9000/words.txt")
3. Spark的算子
RDD中的所有转换都是延迟加载的,也就是说,它们并不会直接计算结果。相反的,它们只是记住这些应用到基础数据集(例如一个文件)上的转换动作。只有当发生一个要求返回结果给Driver的动作时,这些转换才会真正运行。这种设计让Spark更加有效率地运行。
- Transformation
- Action
4. RDD的依赖关系
RDD和它依赖的父RDD(s)的关系有两种不同的类型,即宽依赖(wide depedency)和窄依赖(narrow dependency)。
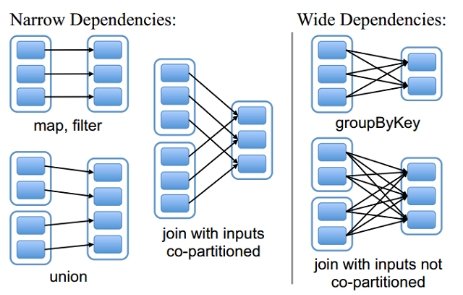
Spark官方的推荐是,给集群中的每个cpu core设置2~3个task。
比如说,spark-submit设置了executor数量是10个,每个executor要求分配2个core,那么application总共会有20个core。此时可以设置new SparkConf().set("spark.default.parallelism", "60")
来设置合理的并行度,从而充分利用资源。
参考:
Spark原理小总结
Spark分区数,task数目,core数,worker节点个数,excutor数量梳理
如何确定Kafka的分区数、key和consumer线程数
Spark Core性能优化总结
spark内核揭秘-14-Spark性能优化的10大问题及其解决方案
Spark RDD理解-总结的更多相关文章
- Spark RDD理解
目录 ----RDD简介 ----RDD操作类别 ----RDD分区 ----宽依赖和窄依赖作用 ----RDD分区划分器 ----RDD到调度 返回顶部 RDD简介 RDD是弹性分布式数据集(Res ...
- [bigdata] Spark RDD整理
1. RDD是什么RDD:Spark的核心概念是RDD (resilient distributed dataset),指的是一个只读的,可分区的弹性分布式数据集,这个数据集的全部或部分可以缓存在内存 ...
- Spark RDD aggregateByKey
aggregateByKey 这个RDD有点繁琐,整理一下使用示例,供参考 直接上代码 import org.apache.spark.rdd.RDD import org.apache.spark. ...
- Spark RDD概念学习系列之RDD的转换(十)
RDD的转换 Spark会根据用户提交的计算逻辑中的RDD的转换和动作来生成RDD之间的依赖关系,同时这个计算链也就生成了逻辑上的DAG.接下来以“Word Count”为例,详细描述这个DAG生成的 ...
- Spark RDD概念学习系列之RDD的checkpoint(九)
RDD的检查点 首先,要清楚.为什么spark要引入检查点机制?引入RDD的检查点? 答:如果缓存丢失了,则需要重新计算.如果计算特别复杂或者计算耗时特别多,那么缓存丢失对于整个Job的影响是不容 ...
- Spark RDD概念学习系列之RDD的依赖关系(宽依赖和窄依赖)(三)
RDD的依赖关系? RDD和它依赖的parent RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency). 1)窄依赖指的是每 ...
- Spark RDD整理
参考资料: Spark和RDD模型研究:http://itindex.net/detail/51871-spark-rdd-模型 理解Spark的核心RDD:http://www.infoq.com/ ...
- Spark RDD概念学习系列之rdd持久化、广播、累加器(十八)
1.rdd持久化 2.广播 3.累加器 1.rdd持久化 通过spark-shell,可以快速的验证我们的想法和操作! 启动hdfs集群 spark@SparkSingleNode:/usr/loca ...
- Spark RDD概念学习系列之rdd的依赖关系彻底解密(十九)
本期内容: 1.RDD依赖关系的本质内幕 2.依赖关系下的数据流视图 3.经典的RDD依赖关系解析 4.RDD依赖关系源码内幕 1.RDD依赖关系的本质内幕 由于RDD是粗粒度的操作数据集,每个Tra ...
随机推荐
- sh_03_列表的数据统计
sh_03_列表的数据统计 name_list = ["张三", "李四", "王五", "王小二", "张三 ...
- Android_(菜单)选项菜单
Android系统中菜单分为Options Menu.Context Menu.Sub Men三种 Options Menu和Context Menu属于一级菜单 Sub Menu属于Options ...
- [CSP-S模拟测试]:蛇(DP+构造+哈希)
题目传送门(内部题140) 输入格式 前两行有两个长度相同的字符串,描述林先森花园上的字母. 第三行一个字符串$S$. 输出格式 输出一行一个整数,表示有多少种可能的蛇,对$10^9+7$取模. 样例 ...
- Golang Singleton
package example import ( "fmt" "sync") var m *singletonvar once sync.Once func G ...
- Hibernate持久化类规则
注意事项: 提供无参的构造方法,因为在hibernate需要使用反射生成类的实例 提供私有属性,并对这些属性提供公共的setting和getting方法,因为在hibernate底层会将查询到的数据进 ...
- 一款兼容性较强的H5播放器-Mediaelementjs
特别提示:本人博客部分有参考网络其他博客,但均是本人亲手编写过并验证通过.如发现博客有错误,请及时提出以免误导其他人,谢谢!欢迎转载,但记得标明文章出处:http://www.cnblogs.com/ ...
- oracle存储过程及sql优化-(一)
本篇主要介绍存储过程的结构 先简单介绍下: oracle存储过程与函数不同,oracle函数和存储过程都可以有多个输入,但是函数一般只有一个输出,而oracle可以有多个输出且与输入 ...
- 如何下载github项目中的某一部分
如何下载github项目中的某一部分 一.总结 一句话总结: 通过 DownGit 下载:原地址失败的话直接百度DownGit,一大堆可用的 通过 Chrome 插件 GitZip 进行下载(推荐) ...
- [Java]使用正则表达式实现分词
手工分词稍嫌麻烦,不好维护,而利用正则表达式就利索多了.Java提供了java.util.regex.Matcher,java.util.regex.Pattern类来帮助我们实现此功能. 例一:以下 ...
- NOIP2010提高组真题部分整理(没有关押罪犯)
目录 \(NOIP2010\)提高组真题部分整理 \(T1\)机器翻译: 题目背景: 题目描述: 输入输出格式: 输入输出样例: 说明: 题解: 代码: \(T2\)乌龟棋 题目背景: 题目描述: 输 ...