Linear Regression and Gradient Descent
随着所学算法的增多,加之使用次数的增多,不时对之前所学的算法有新的理解。这篇博文是在2018年4月17日再次编辑,将之前的3篇博文合并为一篇。
1.Problem and Loss Function
首先,Linear Regression是一种Supervised Learning,有input X,有输出label y。X可以是一维数据,也可以数多维的,因为我们用矩阵来计算,所以对公式和算法都没有影响。我们期望X经过一个算法hθ(X)=θTX后,得到的结果尽可能接近label y。但在初始状态下,不可能的,所以我们需要Traning Set去训练这个hθ(X)函数。而因为函数的形式是确定的,是线性函数,所以我们通过训练去学习的,其实是参数值θ。
而怎么通过Training Set去学习呢?这里就要引入Cost Function了,其概念是预测值与真实值到底差多少?公式是:
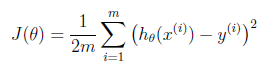
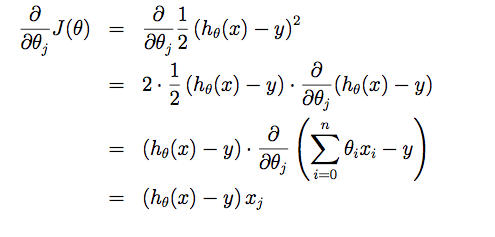

Linear Regression and Gradient Descent的更多相关文章
- Linear Regression Using Gradient Descent 代码实现
参考吴恩达<机器学习>, 进行 Octave, Python(Numpy), C++(Eigen) 的原理实现, 同时用 scikit-learn, TensorFlow, dlib 进行 ...
- 线性回归、梯度下降(Linear Regression、Gradient Descent)
转载请注明出自BYRans博客:http://www.cnblogs.com/BYRans/ 实例 首先举个例子,假设我们有一个二手房交易记录的数据集,已知房屋面积.卧室数量和房屋的交易价格,如下表: ...
- 斯坦福机器学习视频笔记 Week1 Linear Regression and Gradient Descent
最近开始学习Coursera上的斯坦福机器学习视频,我是刚刚接触机器学习,对此比较感兴趣:准备将我的学习笔记写下来, 作为我每天学习的签到吧,也希望和各位朋友交流学习. 这一系列的博客,我会不定期的更 ...
- 斯坦福机器学习视频笔记 Week1 线性回归和梯度下降 Linear Regression and Gradient Descent
最近开始学习Coursera上的斯坦福机器学习视频,我是刚刚接触机器学习,对此比较感兴趣:准备将我的学习笔记写下来, 作为我每天学习的签到吧,也希望和各位朋友交流学习. 这一系列的博客,我会不定期的更 ...
- Linear Regression and Gradient Descent (English version)
1.Problem and Loss Function Linear Regression is a Supervised Learning Algorithm with input matrix ...
- Logistic Regression and Gradient Descent
Logistic Regression and Gradient Descent Logistic regression is an excellent tool to know for classi ...
- Logistic Regression Using Gradient Descent -- Binary Classification 代码实现
1. 原理 Cost function Theta 2. Python # -*- coding:utf8 -*- import numpy as np import matplotlib.pyplo ...
- flink 批量梯度下降算法线性回归参数求解(Linear Regression with BGD(batch gradient descent) )
1.线性回归 假设线性函数如下: 假设我们有10个样本x1,y1),(x2,y2).....(x10,y10),求解目标就是根据多个样本求解theta0和theta1的最优值. 什么样的θ最好的呢?最 ...
- machine learning (7)---normal equation相对于gradient descent而言求解linear regression问题的另一种方式
Normal equation: 一种用来linear regression问题的求解Θ的方法,另一种可以是gradient descent 仅适用于linear regression问题的求解,对其 ...
随机推荐
- linux内核的gpiolib详解
#include <linux/init.h> // __init __exit #include <linux/module.h> // module_init module ...
- 2019牛客暑期多校训练营(第七场) - C - Governing sand - 平衡树
5 1 1 1 2 2 2 3 3 3 4 4 4 5 5 5 感觉该出14才对,取前k小写成了取前k大. 5 1 5 4 2 5 3 3 5 2 4 5 1 6 5 5 suf=55 res=0 a ...
- Sublime Text插件安装方法和常用插件
插件安装方法: 1.打开Sublime Text,按下Ctrl+Shift+P调出命令面板 ; 2.输入install 调出 Install Package Control选项并回车; 3.再次按下C ...
- <s:iterator>标签迭代数据不显示
<s:iterator>标签迭代数据不显示 <s:iterator value="#request.voteOptionList" var="voteO ...
- 后台PDF返回Base64,前台接收预览
读取已存在的PDF文件,path为绝对路径 string base64String = "";byte[] buffer=null; using (FileStream fs = ...
- Tensorflow学习笔记3:卷积神经网络实现手写字符识别
# -*- coding:utf-8 -*- import tensorflow as tf from tensorflow.examples.tutorials.mnist import input ...
- wenzhang
作者:周公子链接:https://zhuanlan.zhihu.com/p/94960418来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出处. 2006年2月9日,首都经济 ...
- 有关shell中冒号的特殊用法
有关shell中冒号的特殊用法,供朋友们参考. : ${VAR:=DEFAULT} 当变量VAR没有声明或者为NULL时,将VAR设置为默认值DEFAULT.如果不在前面加上:命令,那么就会把${VA ...
- bzoj3589 动态树 树链剖分+容斥
题目传送门 https://lydsy.com/JudgeOnline/problem.php?id=3589 题解 事件 \(0\) 不需要说,直接做就可以了. 事件 \(1\) 的话,考虑如果直接 ...
- 关于VS调试
环境配置始终是我的弱项,碰到关于环境配置的问题就各种束手无策.但是这种事情,不能总凑合着,尤其你进不去环境或者没法调试的时候,代码写的多漂亮都没用.下面就来说一下最近关于调试的了解. 首先我们现在的项 ...