Storm消费Kafka提交集群运行
1.创建拓扑,配置KafkaSpout、Bolt
KafkaTopologyBasic.java:
package org.mort.storm.kafka; import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.kafka.spout.*;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.kafka.spout.KafkaSpoutRetryExponentialBackoff.TimeInterval;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values; import java.util.List;
import java.util.concurrent.TimeUnit; import static org.apache.storm.kafka.spout.KafkaSpoutConfig.FirstPollOffsetStrategy.LATEST; /**
* 使用Storm消费Kafka数据,构建Storm拓扑(使用TopologyBuilder)
* 实现SentenceBolt、PrinterBolt
*/
public class KafkaTopologyBasic { /**
* JUST_VALUE_FUNC为kafka消息翻译函数
* 此处简单的将其输出
*/
private static Func<ConsumerRecord<String, String>, List<Object>> JUST_VALUE_FUNC = new Func<ConsumerRecord<String, String>, List<Object>>() {
@Override
public List<Object> apply(ConsumerRecord<String, String> record) {
return new Values(record.value());
}
}; /**
* KafkaSpout重试策略
* @return
*/
protected KafkaSpoutRetryService newRetryService() {
return new KafkaSpoutRetryExponentialBackoff(new TimeInterval(500L, TimeUnit.MICROSECONDS), TimeInterval.milliSeconds(2),
Integer.MAX_VALUE, TimeInterval.seconds(10));
} /**
* KafkaSpout配置
* 新版本的KafkaSpout通过KafkaSpoutConfig类进行配置,KafkaSpoutConfig定义了kafka相关的环境、主题、重试策略、消费的初始偏移量等等参数。
* @return
*/
protected KafkaSpoutConfig<String, String> newKafkaSpoutConfig() {
return KafkaSpoutConfig.builder("192.168.1.201:9092", "first").setProp(ConsumerConfig.GROUP_ID_CONFIG, "kafkaSpoutTestGroup")
.setProp(ConsumerConfig.MAX_PARTITION_FETCH_BYTES_CONFIG, 200).setRecordTranslator(JUST_VALUE_FUNC, new Fields("str"))
.setRetry(newRetryService()).setOffsetCommitPeriodMs(10000).setFirstPollOffsetStrategy(LATEST)
.setMaxUncommittedOffsets(250).build();
} /**
* 将上述bolt和spout以及配置类组合,配置topology
* 构建Storm拓扑(使用TopologyBuilder)
* @return
*/
public StormTopology buildTopology() {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("KafkaSpout", new KafkaSpout<String, String>(newKafkaSpoutConfig()), 1);
builder.setBolt("SentenceBolt", new SentenceBolt(), 1).globalGrouping("KafkaSpout");
builder.setBolt("PrinterBolt", new PrinterBolt(), 1).globalGrouping("SentenceBolt");
return builder.createTopology();
} public final static boolean isCluster = true; public static void main(String[] args) {
// 1 创建拓扑
KafkaTopologyBasic kb = new KafkaTopologyBasic();
StormTopology topology = kb.buildTopology(); // 2 创建配置信息对象
Config conf = new Config();
// 配置Worker开启个数
conf.setNumWorkers(4); // 3 提交程序
if(isCluster){
try {
// 分布式提交
StormSubmitter.submitTopology("SentenceTopology", conf, topology);
}catch (Exception e){
e.printStackTrace();
}
}else {
// 本地提交
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("KafkaToplogy", conf, topology);
try {
// Wait for some time before exiting
System.out.println("Waiting to consume from kafka");
Thread.sleep(300000);
} catch (Exception exception) {
System.out.println("Thread interrupted exception : " + exception);
}
// kill the KafkaTopology
cluster.killTopology("KafkaToplogy");
// shut down the storm test cluster
cluster.shutdown();
}
}
}
PrinterBolt.java:
package org.mort.storm.kafka; import org.apache.storm.topology.BasicOutputCollector;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseBasicBolt;
import org.apache.storm.tuple.Tuple;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory; /**
* 用于打印输出Sentence的Bolt
*/
public class PrinterBolt extends BaseBasicBolt { private static final long serialVersionUID = 1L; private static final Logger logger = LoggerFactory.getLogger(PrinterBolt.class); @Override
public void execute(Tuple input, BasicOutputCollector collector) {
// get the sentence from the tuple and print it
String sentence = input.getString(0);
logger.info("Received Sentence: " + sentence);
System.out.println("Received Sentence: " + sentence);
} @Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// we don't emit anything
}
}
SentenceBolt.java
package org.mort.storm.kafka; import java.util.ArrayList;
import java.util.List; import org.apache.commons.lang.StringUtils;
import org.apache.storm.topology.BasicOutputCollector;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseBasicBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory; /**
* 写一组将输入的单词拼成一句话的bolt类,每行输入一个单词,当输入符号“.”时,视为一句话结束。
*/
public class SentenceBolt extends BaseBasicBolt { private static final long serialVersionUID = 1L; private static final Logger logger = LoggerFactory.getLogger(SentenceBolt.class); private List<String> words = new ArrayList<String>(); @Override
public void execute(Tuple input, BasicOutputCollector collector) {
// Get the word from the tuple
String word = input.getString(0);
if (StringUtils.isBlank(word)) {
// ignore blank lines
return;
}
logger.info("Received Word:" + word);
System.out.println("Received Word:" + word);
// add word to current list of words
words.add(word);
if (word.endsWith(".")) {
// word ends with '.' which means this is the end
// the SentenceBolt publishes a sentence tuple
collector.emit(new Values(StringUtils.join(words, ' ')));
// and reset the words list.
words.clear();
}
} @Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("sentence"));
} }
2.pom.xml设置
1)设置利用maven-assembly-plugin生成jar包方式
<build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>org.mort.storm.kafka.KafkaTopologyBasic</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
2)依赖包添加
注意storm-core依赖为了防止执行时冲突需要添加<scope>provided</scope>(本地运行时去掉、打包时加上)
<dependencies>
<dependency> <!-- 桥接:告诉Slf4j使用Log4j2 -->
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>26.0-jre</version>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>1.2.3</version>
<scope>provided</scope>
</dependency>
<!-- storm-kafka连接客户端 -->
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-kafka-client</artifactId>
<version>1.2.3</version>
</dependency>
<!-- kafka连接客户端 -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.0.1</version>
</dependency>
</dependencies>
3.执行assembly:assembly生成jar包
4.复制jar包到集群,执行命令
bin/storm jar /opt/run/storm-demo-1.0-SNAPSHOT-jar-with-dependencies.jar org.mort.storm.kafka.KafkaTopologyBasic
bin/storm jar [jar包路径] [main所在类名]
执行效果:
[root@hadoop201 apache-storm-1.2.]# bin/storm jar /opt/run/storm-demo-1.0-SNAPSHOT-jar-with-dependencies.jar org.mort.storm.kafka.KafkaTopologyBasic
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/apache-storm-1.2./lib/log4j-slf4j-impl-2.8..jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/run/storm-demo-1.0-SNAPSHOT-jar-with-dependencies.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Running: /opt/module/jdk1..0_144/bin/java -client -Ddaemon.name= -Dstorm.options= -Dstorm.home=/opt/module/apache-storm-1.2. -Dstorm.log.dir=/opt/module/apache-storm-1.2./logs -Djava.library.path=/usr/local/lib:/opt/local/lib:/usr/lib -Dstorm.conf.file= -cp /opt/module/apache-storm-1.2./*:/opt/module/apache-storm-1.2.3/lib/*:/opt/module/apache-storm-1.2.3/extlib/*:/opt/run/storm-demo-1.0-SNAPSHOT-jar-with-dependencies.jar:/opt/module/apache-storm-1.2.3/conf:/opt/module/apache-storm-1.2.3/bin -Dstorm.jar=/opt/run/storm-demo-1.0-SNAPSHOT-jar-with-dependencies.jar -Dstorm.dependency.jars= -Dstorm.dependency.artifacts={} org.mort.storm.kafka.KafkaTopologyBasic
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/apache-storm-1.2.3/lib/log4j-slf4j-impl-2.8.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/run/storm-demo-1.0-SNAPSHOT-jar-with-dependencies.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
5481 [main] INFO o.a.s.k.s.KafkaSpoutConfig - Setting Kafka consumer property 'auto.offset.reset' to 'earliest' to ensure at-least-once processing
5564 [main] INFO o.a.s.k.s.KafkaSpoutConfig - Setting Kafka consumer property 'enable.auto.commit' to 'false', because the spout does not support auto-commit
7441 [main] WARN o.a.s.u.Utils - STORM-VERSION new 1.2.3 old null
7658 [main] INFO o.a.s.StormSubmitter - Generated ZooKeeper secret payload for MD5-digest: -8420262939352556619:-8011743779888436007
8316 [main] INFO o.a.s.u.NimbusClient - Found leader nimbus : hadoop201.com:6627
8388 [main] INFO o.a.s.s.a.AuthUtils - Got AutoCreds []
8426 [main] INFO o.a.s.u.NimbusClient - Found leader nimbus : hadoop201.com:6627
8661 [main] INFO o.a.s.StormSubmitter - Uploading dependencies - jars...
8661 [main] INFO o.a.s.StormSubmitter - Uploading dependencies - artifacts...
8662 [main] INFO o.a.s.StormSubmitter - Dependency Blob keys - jars : [] / artifacts : []
8751 [main] INFO o.a.s.StormSubmitter - Uploading topology jar /opt/run/storm-demo-1.0-SNAPSHOT-jar-with-dependencies.jar to assigned location: /opt/module/apache-storm-1.2.3/data/nimbus/inbox/stormjar-c0d5b00a-b07e-48f1-ac4d-871c5b3f635d.jar
9815 [main] INFO o.a.s.StormSubmitter - Successfully uploaded topology jar to assigned location: /opt/module/apache-storm-1.2.3/data/nimbus/inbox/stormjar-c0d5b00a-b07e-48f1-ac4d-871c5b3f635d.jar
9815 [main] INFO o.a.s.StormSubmitter - Submitting topology SentenceTopology in distributed mode with conf {"topology.workers":4,"storm.zookeeper.topology.auth.scheme":"digest","storm.zookeeper.topology.auth.payload":"-8420262939352556619:-8011743779888436007"}
9815 [main] WARN o.a.s.u.Utils - STORM-VERSION new 1.2.3 old 1.2.3
11935 [main] INFO o.a.s.StormSubmitter - Finished submitting topology: SentenceTopology
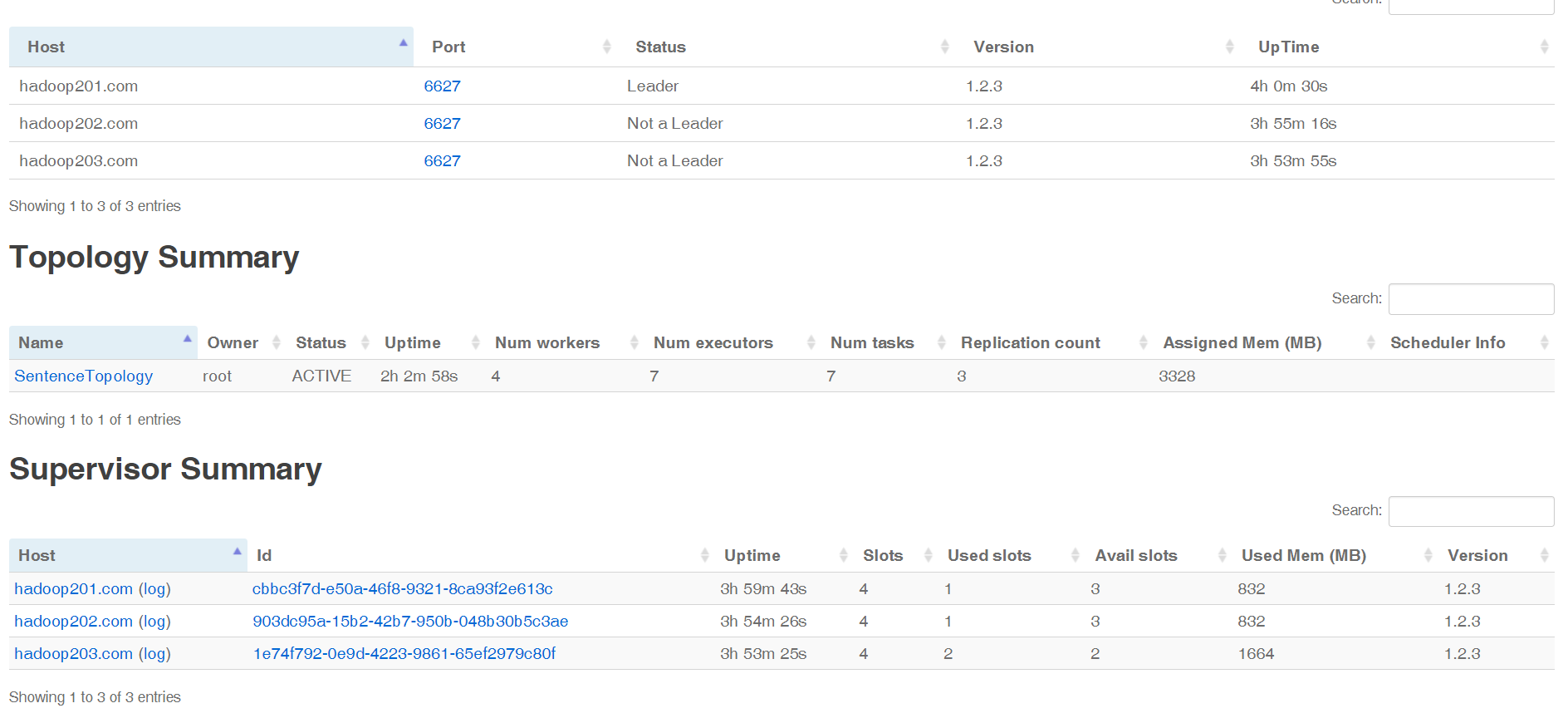
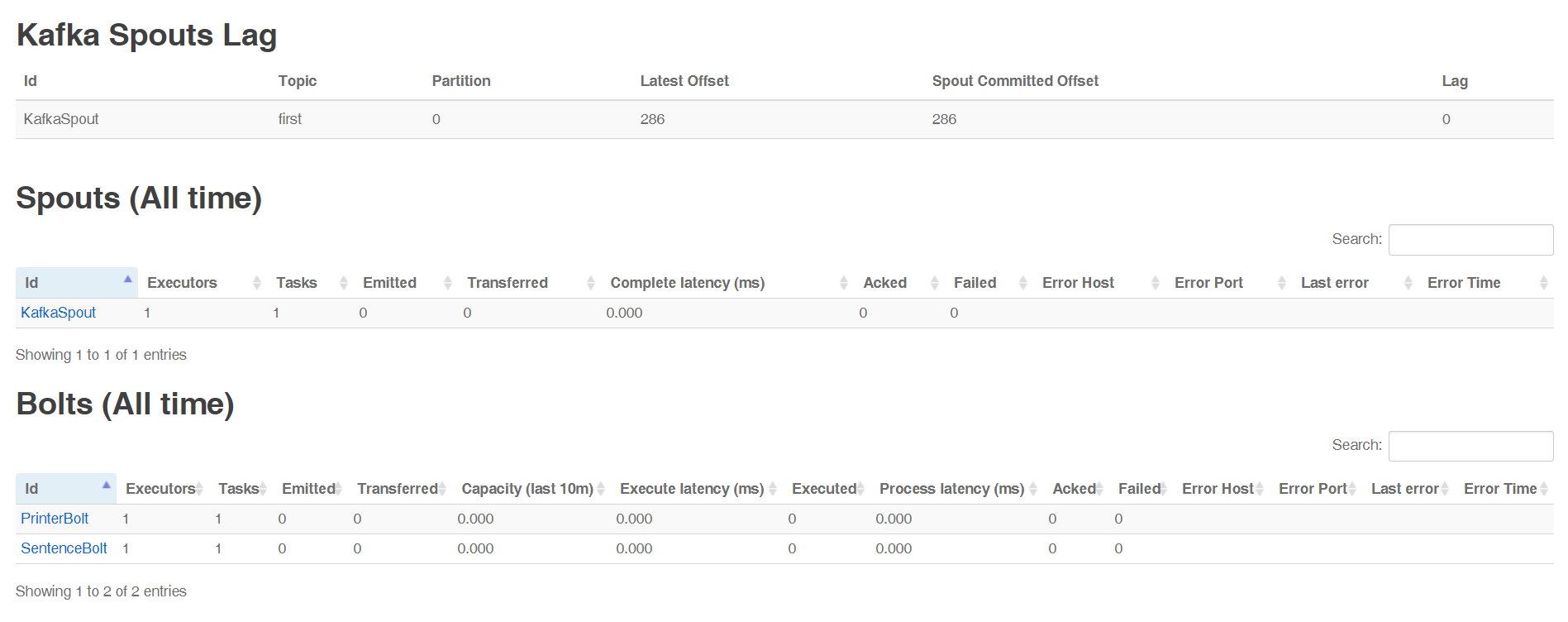
5.通过UI查看执行情况
Storm消费Kafka提交集群运行的更多相关文章
- 2 weekend110的mapreduce介绍及wordcount + wordcount的编写和提交集群运行 + mr程序的本地运行模式
把我们的简单运算逻辑,很方便地扩展到海量数据的场景下,分布式运算. Map作一些,数据的局部处理和打散工作. Reduce作一些,数据的汇总工作. 这是之前的,weekend110的hdfs输入流之源 ...
- storm消费kafka实现实时计算
大致架构 * 每个应用实例部署一个日志agent * agent实时将日志发送到kafka * storm实时计算日志 * storm计算结果保存到hbase storm消费kafka 创建实时计算项 ...
- Storm消费Kafka值得注意的坑
问题描述: kafka是之前早就搭建好的,新建的storm集群要消费kafka的主题,由于kafka中已经记录了很多消息,storm消费时从最开始消费问题解决: 下面是摘自官网的一段话:How Kaf ...
- spark学习之IDEA配置spark并wordcount提交集群
这篇文章包括以下内容 (1)IDEA中scala的安装 (2)hdfs简单的使用,没有写它的部署 (3) 使用scala编写简单的wordcount,输入文件和输出文件使用参数传递 (4)IDEA打包 ...
- storm单机运行与集群运行问题
使用trident接口时,storm读取kafka数据会将kafka消费记录保存起来,将消费记录的位置保存在tridentTopology.newStream()的第一个参数里, 如果设置成从头开始消 ...
- 第1节 storm日志告警:1、 - 5、日志监控告警业务需求、代码、集群运行、总结
如何解决短信或者邮件频繁发送的问题:每次发送的时候都先查询数据库记录,看一下有没有给这个人发送消息,上一次发送消息的时间是什么时候,如果发送时间间隔小于半个小时,就不要再发了 ============ ...
- Storm累计求和进群运行代码
打成jar包放在主节点上去运行. import java.util.Map; import backtype.storm.Config; import backtype.storm.StormSubm ...
- Storm集成Kafka应用的开发
我们知道storm的作用主要是进行流式计算,对于源源不断的均匀数据流流入处理是非常有效的,而现实生活中大部分场景并不是均匀的数据流,而是时而多时而少的数据流入,这种情况下显然用批量处理是不合适的,如果 ...
- Spark本地运行成功,集群运行空指针异。
一个很久之前写的Spark作业,当时运行在local模式下.最近又开始处理这方面数据了,就打包提交集群,结果频频空指针.最开始以为是程序中有null调用了,经过排除发现是继承App导致集群运行时候无法 ...
随机推荐
- Centos 7自定义屏幕分辨率
$ xrandrScreen 0: minimum 1 x 1, current 1680 x 900, maximum 8192 x 8192Virtual1 connected primary 1 ...
- jQuery事件之绑定事件
语法: $(selector).bind(eventType[, eventData], handler(eventObject)); 参数解释: eventType(String): 一个包含一个或 ...
- PHP-windows下安装
下载 Apache下载地址:http://httpd.apache.org/download.cgi PHP下载地址:http://php.net/downloads.php 解压 解压到安装路径下H ...
- OkHttp3 拦截器源码分析
OkHttp 拦截器流程源码分析 在这篇博客 OkHttp3 拦截器(Interceptor) ,我们已经介绍了拦截器的作用,拦截器是 OkHttp 提供的对 Http 请求和响应进行统一处理的强大机 ...
- python接口自动化:python3.6中import Crypto.Hash报错的解决方案
一:问题 python3.6中算法加密引入包Crypto报错,即便安装了: pip install crypto pip install pycrypto pip install pycryptodo ...
- 微信小程序支持windows PC版了
微信 PC 版新版本中,支持打开聊天中分享的小程序,开发者可下载安装微信 PC 版内测版本进行体验和适配.最新版微信开发者工具新增支持在微信 PC 版中预览小程序 查看详情 微信 PC 版内测版下载地 ...
- Error:java: 错误: 不支持发行版本 5
本文链接:https://blog.csdn.net/wo541075754/article/details/70154604 在Intellij idea中新建了一个Maven项目,运行时报错如下: ...
- SRS之RTMP的TCP线程(即监听线程)
本文分析的是 SRS 针对 rtmp 的端口建立的 tcp 线程.具体建立过程: SRS之监听端口的管理:RTMP RTMP 的 TCP 线程中各个类之间 handler 的关系图 1. RTMP之T ...
- 在Ubuntu 16.04配置VNC Server (灰屏问题解决)
使用命令安装 sudo apt install xfce4 xfce4-goodies tightvncserver 编辑vnc启动文件,安全期间最好备份一下 mv ~/.vnc/xstartup ...
- HearthBuddy卡牌无法识别
界面上无法识别,提示是 [Unidentified card ID :DAL_010][Unidentified card ID :DAL_415] Unidentified card ID :HER ...