scrapy框架之进阶
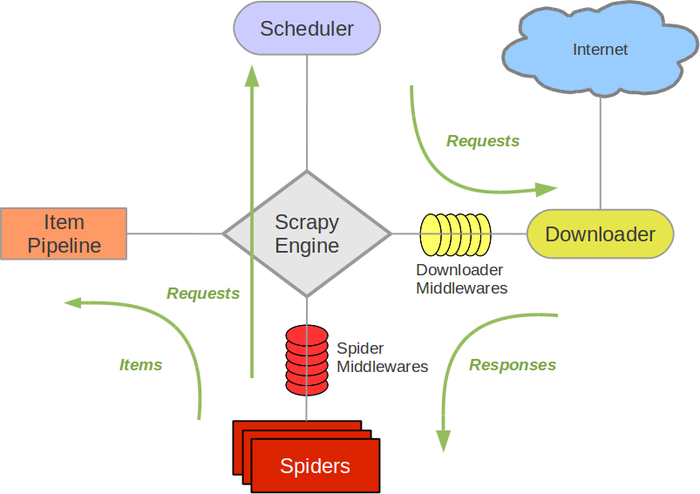
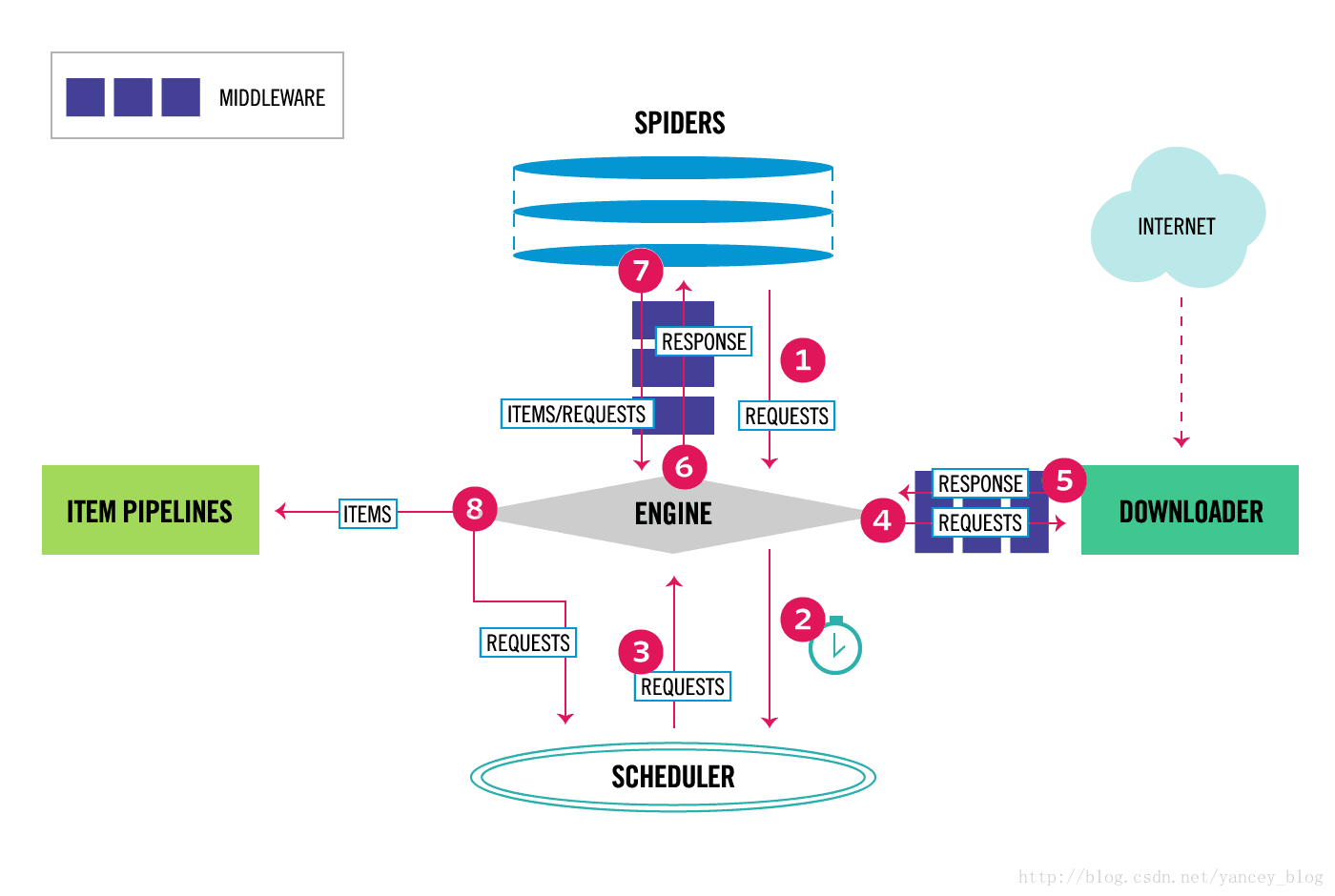
五大核心组件
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心)
- 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
- 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
- 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
- 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
scrapy工作原理
旧版
新版
如何提升scrapy爬取数据的效率
增加并发:
默认scrapy开启的并发线程为32个,可以适当进行增加。在settings配置文件中修改CONCURRENT_REQUESTS = 100值为100,并发设置成了为100。 降低日志级别:
在运行scrapy时,会有大量日志信息的输出,为了减少CPU的使用率。可以设置log输出信息为INFO或者ERROR即可。在配置文件中编写:LOG_LEVEL = ‘INFO’ 禁止cookie:
如果不是真的需要cookie,则在scrapy爬取数据时可以禁止cookie从而减少CPU的使用率,提升爬取效率。在配置文件中编写:COOKIES_ENABLED = False 禁止重试:
对失败的HTTP进行重新请求(重试)会减慢爬取速度,因此可以禁止重试。在配置文件中编写:RETRY_ENABLED = False 减少下载超时:
如果对一个非常慢的链接进行爬取,减少下载超时可以能让卡住的链接快速被放弃,从而提升效率。在配置文件中进行编写:DOWNLOAD_TIMEOUT = 10 超时时间为10s
全站抓取数据
# get请求
yield scrapy.Request(url,callback) # post请求
yield scrapy.FormRequest(url,formdata,callback)
示例代码
get请求抓取所有页码数据
# -*- coding: utf-8 -*-
import scrapy
from quanzhanzhuaqu.items import QuanzhanzhuaquItem class QzzqSpider(scrapy.Spider):
name = 'qzzq'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://www.zhipin.com/job_detail/?query=python&city=101010100&industry=&position='] # 通用url模板
url = "https://www.zhipin.com/c101010100/?query=python&page=%d"
page = 1
def parse(self, response):
print('正在爬取第{}页的数据'.format(self.page))
job_title = response.xpath('//div[@class="job-title"]/text()').extract()
red = response.xpath('//span[@class="red"]/text()').extract() for i in range(len(job_title)):
item = QuanzhanzhuaquItem()
item["job_title"] = job_title[i]
item["red"] = red[i]
yield item # 爬取页码
if self.page<5:
# 对其他页码进行手动请求
new_url = format(self.url%self.page)
self.page+=1 # 手动请求
# callback进行数据解析
yield scrapy.Request(url=new_url,callback=self.parse)
深度抓取
scrapy.Request(url=detail_url,callback=self.parse_detail,meta={'item':item})
# 这里用到meta参数可以将item对象传给回调函数,使其parse和parse_detail共享一个item对象
# -*- coding: utf-8 -*-
import scrapy
from bossDeepPro.items import BossdeepproItem class BossSpider(scrapy.Spider):
name = 'boss'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://www.zhipin.com/job_detail/?query=python%E5%BC%80%E5%8F%91&city=101010100&industry=&position='] # 通用的url模板(不可变)
url = 'https://www.zhipin.com/c101010100/?query=python开发&page=%d'
page = 2 def parse(self, response):
print('正在爬取第{}页的数据'.format(self.page)) # 这里的xpath写了两种,因为每页的匹配规则不一样
li_list = response.xpath('//*[@id="main"]/div/div[3]/ul/li | //*[@id="main"]/div/div[2]/ul/li')
for li in li_list:
job_title = li.xpath('.//div[@class="info-primary"]/h3/a/div[1]/text()').extract_first()
salary = li.xpath('.//div[@class="info-primary"]/h3/a/span/text()').extract_first()
#实例化item对象:对象必须要让parse和parse_detail共享
item = BossdeepproItem()
item['job_title'] = job_title
item['salary'] = salary detail_url = 'https://www.zhipin.com'+li.xpath('.//div[@class="info-primary"]/h3/a/@href').extract_first() #对详情页的url发起手动请求,并将item对象传给回调函数
yield scrapy.Request(url=detail_url,callback=self.parse_detail,meta={'item':item}) if self.page <= 5:
# 对其他页码进行手动请求的发送
new_url = format(self.url % self.page)
print(new_url)
self.page += 1
# 手动请求发送
# callback进行数据解析
yield scrapy.Request(url=new_url, callback=self.parse) #解析岗位描述
def parse_detail(self,response):
item = response.meta['item']
job_desc = response.xpath('//*[@id="main"]/div[3]/div/div[2]/div[2]/div[1]/div//text()').extract()
job_desc = ''.join(job_desc) item['job_desc'] = job_desc yield item
scrapy框架之进阶的更多相关文章
- Python爬虫进阶三之Scrapy框架安装配置
初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此整理如下. Windows 平台: 我的系统是 ...
- Python爬虫进阶之Scrapy框架安装配置
Python爬虫进阶之Scrapy框架安装配置 初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此 ...
- Python爬虫进阶(Scrapy框架爬虫)
准备工作: 配置环境问题什么的我昨天已经写了,那么今天直接安装三个库 首先第一步: ...
- Scrapy 框架进阶笔记
上一篇简单了解了scrapy各个模块的功能:Scrapy框架初探 -- Dapianzi卡夫卡 在这篇通过一些实例来深入理解 scrapy 的各个对象以及它们是怎么相互协作的 settings.py ...
- 爬虫写法进阶:普通函数--->函数类--->Scrapy框架
本文转载自以下网站: 从 Class 类到 Scrapy https://www.makcyun.top/web_scraping_withpython12.html 普通函数爬虫: https:// ...
- Python爬虫Scrapy框架入门(2)
本文是跟着大神博客,尝试从网站上爬一堆东西,一堆你懂得的东西 附上原创链接: http://www.cnblogs.com/qiyeboy/p/5428240.html 基本思路是,查看网页元素,填写 ...
- Python爬虫Scrapy框架入门(1)
也许是很少接触python的原因,我觉得是Scrapy框架和以往Java框架很不一样:它真的是个框架. 从表层来看,与Java框架引入jar包.配置xml或.property文件不同,Scrapy的模 ...
- Scrapy框架使用—quotesbot 项目(学习记录一)
一.Scrapy框架的安装及相关理论知识的学习可以参考:http://www.yiibai.com/scrapy/scrapy_environment.html 二.重点记录我学习使用scrapy框架 ...
- Python爬虫从入门到放弃(十一)之 Scrapy框架整体的一个了解
这里是通过爬取伯乐在线的全部文章为例子,让自己先对scrapy进行一个整理的理解 该例子中的详细代码会放到我的github地址:https://github.com/pythonsite/spider ...
随机推荐
- javascript 数组去重的方法
前言:这是笔者学习之后自己的理解与整理.如果有错误或者疑问的地方,请大家指正,我会持续更新! 方法一 //注意有一个元素是空的 var test1 = [0, 0, 1, 1, 2, 'sss', 2 ...
- JSQI网站大事表 | Website Landmark
2016-07-01 网站前身jsqi.50vip.com上线.2016-07-12 购买jsqi.org域名,替代之前的二级域名.2016-12-12 申请ChinaDMOZ收录,瞬间申请通过.20 ...
- 1 Refused to display ‘url’ in a frame because it set 'X-Frame-Options' to 'sameorigin' 怎么解决?
进在开发公司的文件中心组件,提供各个子系统的附件上传下载.预览.版本更新等功能,前端在今天突然给我发一张图,说预览缩略图遇到问题了,然后发了个截图给我: 这很明显是一个跨域问题, X-Frame-Op ...
- sql语句分页多种方式
sql语句分页多种方式ROW_NUMBER()OVER sql语句分页多种方式ROW_NUMBER()OVER 2009年12月04日 星期五 14:36 方式一 select top @pageSi ...
- puml 用于代码注释
notebook 笔记本 @startuml rectangle sql_decode.py{ object SQLDataset object Name SQLDataset : meta = &q ...
- secureCRT 在本地和远程传输文件方式
securecrt 按下ALT+P就开启新的会话 进行ftp操作.输入:help命令,显示该FTP提供所有的命令 pwd: 查询linux主机所在目录(也就是远程主机目录) ...
- nodejs实现邮件发送
需要安装的node模块 nodemailer 新建项目目录 mail-test 进入这个项目里使用终端初始化package.json(npm init) 安装express和nodemailer并保存 ...
- stm32 SysTick系统定时器
它是一个24位向下递减的定时器,每计数一次所需时间为1/SYSTICK,SYSTICK是系统定时器时钟,它可以直接取自系统时钟,还可以通过系统时钟8分频后获取 当定时器计数到0时,将从LOAD 寄存器 ...
- iOS开发 iOS10推送必看(基础篇)-转
iOS10更新之后,推送也是做了一些小小的修改,下面我就给大家仔细说说.希望看完我的这篇文章,对大家有所帮助. 一.简单入门篇---看完就可以简单适配完了 相对简单的推送证书以及环境的问题,我就不在这 ...
- keil 选项卡设置
*1.optimization : level2. *2. 2)硬件目标设置选项卡(Target),见图6所示. 图6 1:选择硬件目标设置选项卡 2:指定用于的晶振频率 3:在应用中可以选择实时操 ...