bert系列一:《Attention is all you need》论文解读
论文创新点:
- 多头注意力
- transformer模型
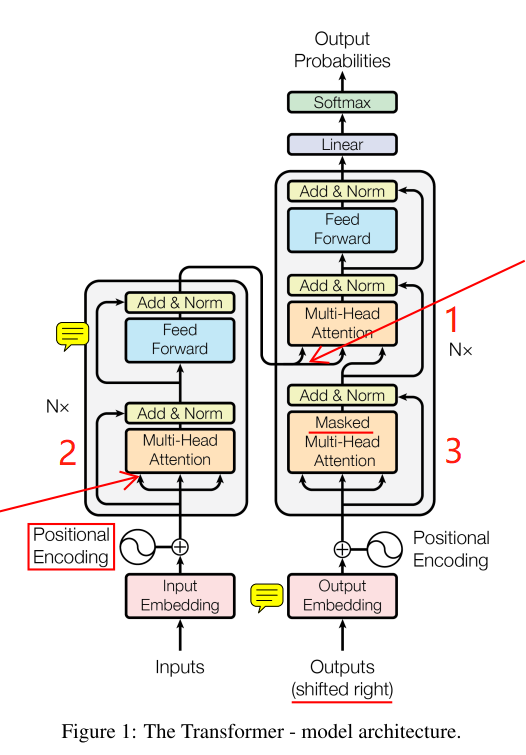
Transformer模型
上图为模型结构,左边为encoder,右边为decoder,各有N=6个相同的堆叠。
encoder
先对inputs进行Embedding,再将位置信息编码进去(cancat方式),位置编码如下:
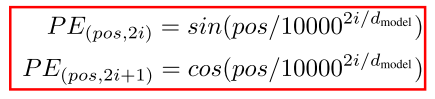
然后经过多头注意力模块后,与残余连接cancat后进行一个Norm操作,多头注意力模块如下:
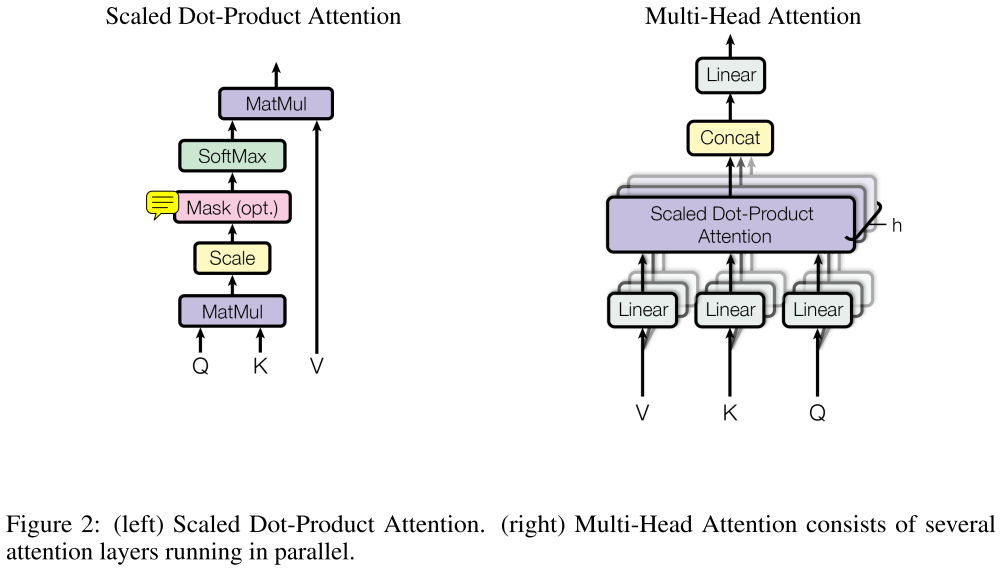
左图:缩放点乘注意力,这就是个平常的注意力机制,只不过多了scale和mask(仅对于decoder下面橙色框部分),使用的是dot-product attention,原文还提到另一种additive attention。
右图:多头注意力实现。每个Q,K,V都经过h个(不同)线性结构,以捕获不同子空间的信息,经过左图结构后,对h个dot-product attention进行concat后,再经过一个线性层。
之后,再通过一个有残余连接的前向网络。
decoder
同样先经过Embedding和位置编码,输入outputs右移了(因为每一个当前输出基于之前的输出)。
下面的橙色框:
之后也经过一个多头的self-attention,不同的是,它多了个mask操作。
这个mask操作是什么意思呢?注意我们的self-attention是一句话中每个词向量都与句子中所有词向量有关,对于encoder这没问题,而对于decoder,我们是根据之前的输出预测下一个输出。
举个例子,在BiLSTM中(当然这里是Transformer模型),假设我们decode时输入为A-B-C-D序列,在B处解码下一个输出时,我们根据之前的输出进行预测,但是这是双向模型,
即我们存在这样的一个之前的输出C-B-A-B,那么这个之前的输出里居然包含了我们下一个需要正确预测的C!这就是“自己看见自己”问题。
所以,mask操作是掩盖掉之后的位置(原文leftward,即向左流动的信息)的影响,原文是置为负无穷。这个橙色框我觉得可以称为half-self-attention。
最上面的橙色框:
它就不能叫self-attention结构了,因为它的K和V来自encoder的输出,Q是下面橙色框的输出。到这步为止,我们的输入inputs是完整的self-attention了,我们的输出outputs也是half-self-attention了。
好了,前戏准备完毕,开始短兵相接了。
这里的K和V一般相同,表示经过self-attention的隐藏语义向量,Q为经过half-self-attention的上一个输出,此处即为解码操作。经过一个有残余连接的前向网络,一个线性层,再softmax得到输出概率分布。
至此,Transformer模型描述完毕。
我们再看看self-attention模块,我之前一直不明白这些Q,K,V是啥东东。此处也是我个人推断。
在self-attention中,K,V表示当前位置的词向量,Q表示所有位置的词向量,用Q中每一个词向量与K进行操作(类似上面缩放点乘注意力截止到softmax),得到L个(L为句子单词数)权重向量。
此时应该有2种操作,一种是对L个权重向量相加,一种是取平均。得到的结果权重向量与V点乘,即为有self-attention后的词向量。
其余的实验及结果部分不再讲述,没什么难点。
这里再提下另一篇论文《End-To-End Memory Networks》中的一个模型结构。因为这篇论文被上面论文提到,对于理解上面论文有所帮助。
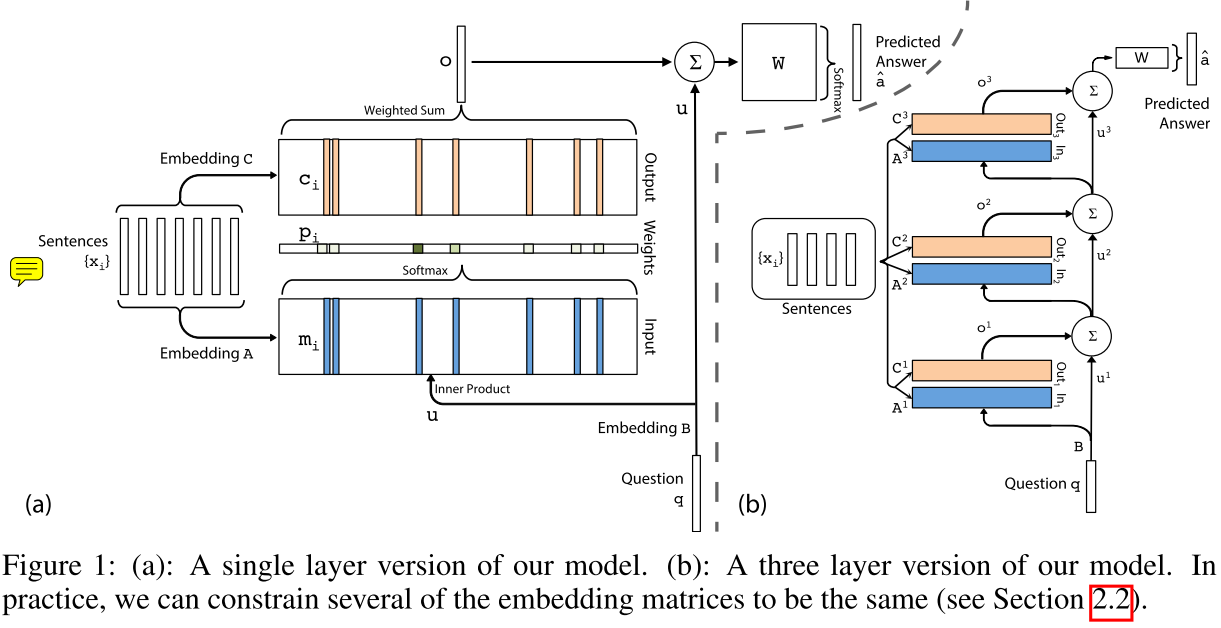
上图左边为单层,右边为多层版本。
单层的输出为:

Embedding B和C用于将输入x和问题q转化为嵌入向量,Embedding A用另一套参数将输出x转化为嵌入向量,与问题q共同决定注意力权重。
因为右图涉及到众多参数,为了简化模型,作者提出2种方案,这里直接上图:

这篇论文的创新点在于右图的多层版本类似RNNs,运算复杂度也比拟RNNs,避免了RNNs存在的一些问题。在QA问题上取得不错的成绩。
bert系列一:《Attention is all you need》论文解读的更多相关文章
- Bert系列 源码解读 四 篇章
Bert系列(一)——demo运行 Bert系列(二)——模型主体源码解读 Bert系列(三)——源码解读之Pre-trainBert系列(四)——源码解读之Fine-tune 转载自: https: ...
- Bert系列(三)——源码解读之Pre-train
https://www.jianshu.com/p/22e462f01d8c pre-train是迁移学习的基础,虽然Google已经发布了各种预训练好的模型,而且因为资源消耗巨大,自己再预训练也不现 ...
- bert系列二:《BERT》论文解读
论文<BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding> 以下陆续介绍ber ...
- Bert系列(二)——源码解读之模型主体
本篇文章主要是解读模型主体代码modeling.py.在阅读这篇文章之前希望读者们对bert的相关理论有一定的了解,尤其是transformer的结构原理,网上的资料很多,本文内容对原理部分就不做过多 ...
- nlp任务中的传统分词器和Bert系列伴生的新分词器tokenizers介绍
layout: blog title: Bert系列伴生的新分词器 date: 2020-04-29 09:31:52 tags: 5 categories: nlp mathjax: true ty ...
- Java容器--2021面试题系列教程(附答案解析)--大白话解读--JavaPub版本
Java容器--2021面试题系列教程(附答案解析)--大白话解读--JavaPub版本 前言 序言 再高大上的框架,也需要扎实的基础才能玩转,高频面试问题更是基础中的高频实战要点. 适合阅读人群 J ...
- 论文解读(FedGAT)《Federated Graph Attention Network for Rumor Detection》
论文信息 论文标题:Federated Graph Attention Network for Rumor Detection论文作者:Huidong Wang, Chuanzheng Bai, Ji ...
- BERT论文解读
本文尽量贴合BERT的原论文,但考虑到要易于理解,所以并非逐句翻译,而是根据笔者的个人理解进行翻译,其中有一些论文没有解释清楚或者笔者未能深入理解的地方,都有放出原文,如有不当之处,请各位多多包含,并 ...
- [Attention Is All You Need]论文笔记
主流的序列到序列模型都是基于含有encoder和decoder的复杂的循环或者卷积网络.而性能最好的模型在encoder和decoder之间加了attentnion机制.本文提出一种新的网络结构,摒弃 ...
随机推荐
- BZOJ 1406: [AHOI2007]密码箱 exgcd+唯一分解定理
推出来了一个解法,但是感觉复杂度十分玄学,没想到秒过~ Code: #include <bits/stdc++.h> #define ll long long #define N 5000 ...
- Dijkstra算法和Floyd算法的正确性证明
说明: 本文仅提供关于两个算法的正确性的证明,不涉及对算法的过程描述和实现细节 本人算法菜鸟一枚,提供的证明仅是自己的思路,不保证正确,仅供参考,若有错误,欢迎拍砖指正 ------------- ...
- centos后台运行python程序
在服务器上,为了退出终端,程序依然能够运行,需要设置程序在后台运行. 关键的命令:nohup *基本用法:进入要运行的py文件目录前 nohup python -u test.py > tes ...
- kubernetes集群搭建
工作环境: 主机名 IP 系统 master 192.168.199.6 rhel7.4 node1 192.168.199.7 rhel7.4 node2 192.168.199.8 rhel7.4 ...
- HNOI2012矿场搭建
做完Mining Your Own Business后觉得这个题没什么意思了,数据范围小的连边数不清空都能A. 题解直接看这篇吧.做题的经历也挺……对吧. #include<iostream&g ...
- 【面试】SSH 框架原理
SSH 框架原理: 1.通过 Configuration().configure();读取并解析 hibernate.cfg.xml 配置文件2.由 hibernate.cfg.xml中的<ma ...
- JVM 监控工具——jps
[参考文章]:[Linux运维入门]Jstatd方式远程监控Linux下 JVM运行情况 1. jps简介 显示系统内所有的HotSpot虚拟机进程. 且只能查看当前用户下的Java进程信息: 2. ...
- LeetCode 109. 有序链表转换二叉搜索树(Convert Sorted List to Binary Search Tree)
题目描述 给定一个单链表,其中的元素按升序排序,将其转换为高度平衡的二叉搜索树. 本题中,一个高度平衡二叉树是指一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1. 示例: 给定的有序链表: ...
- python--nolocal
Compare this, without using nonlocal: x = 0def outer(): x = 1 def inner(): x = 2 print("inner:& ...
- PMML辅助机器学习算法上线
在机器学习用于产品的时候,我们经常会遇到跨平台的问题.比如我们用Python基于一系列的机器学习库训练了一个模型,但是有时候其他的产品和项目想把这个模型集成进去,但是这些产品很多只支持某些特定的生产环 ...