用python爬取豆瓣电影Top 250
首先,打开豆瓣电影Top 250,然后进行网页分析。找到它的Host和User-agent,并保存下来。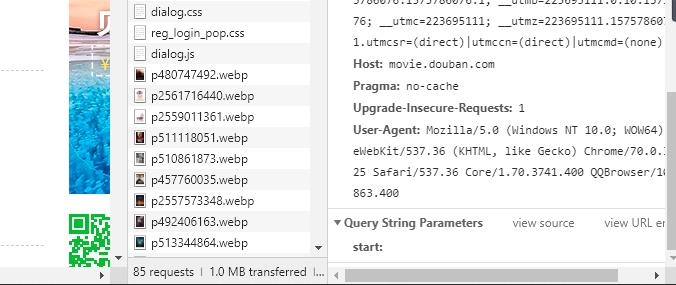 然后,我们通过翻页,查看各页面的url,发现规律:
然后,我们通过翻页,查看各页面的url,发现规律:
第一页:https://movie.douban.com/top250?start=0&filter=
第二页:https://movie.douban.com/top250?start=25&filter=
第三页:https://movie.douban.com/top250?start=50&filter=
第四页:https://movie.douban.com/top250?start=75&filter=
我们发现,每个页面的url都是https://movie.douban.com/top250?start= +25+ &filter=的规律。如此,就可以开始写代码:
import requests
from bs4 import BeautifulSoup
def get_movie():
headers={
'Host': 'movie.douban.com',
'User-Agent': 'Mozilla / 5.0(Windows NT 6.1;WOW64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 45.0.2454.101Safari / 537.36'
} #防止反扒措施
movie_list=[]
for i in range(10):
url='https://movie.douban.com/top250?start='+str(i*25) #各页面url
response=requests.get(url,headers=headers,timeout=10)
soup=BeautifulSoup(response.text,'lxml')
div_list=soup.find_all('div',class_='hd')
for each in div_list:
movie=each.a.span.text.strip()
movie_list.append(movie)
for j in movie_list:
print(j) #按格式输出电影名称
get_movie()
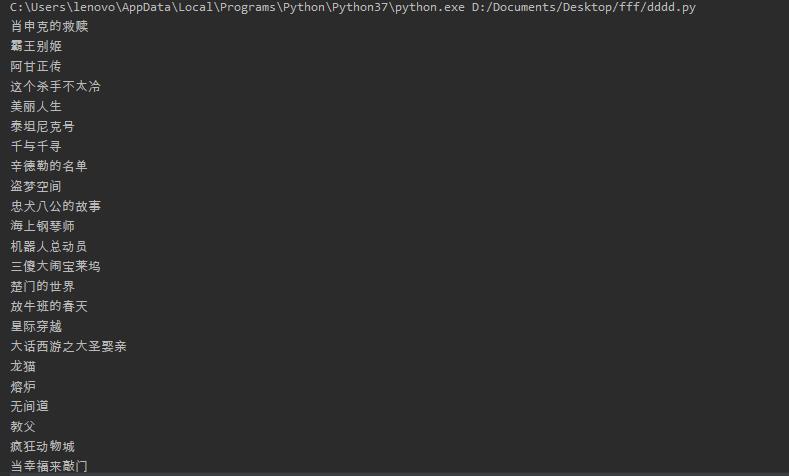
下面给出运行结果:
用python爬取豆瓣电影Top 250的更多相关文章
- 爬取豆瓣电影TOP 250的电影存储到mongodb中
爬取豆瓣电影TOP 250的电影存储到mongodb中 1.创建项目sp1 PS D:\scrapy> scrapy.exe startproject douban 2.创建一个爬虫 PS D: ...
- Python爬取豆瓣电影top
Python爬取豆瓣电影top250 下面以四种方法去解析数据,前面三种以插件库来解析,第四种以正则表达式去解析. xpath pyquery beaufifulsoup re 爬取信息:名称 评分 ...
- Python开发爬虫之静态网页抓取篇:爬取“豆瓣电影 Top 250”电影数据
所谓静态页面是指纯粹的HTML格式的页面,这样的页面在浏览器中展示的内容都在HTML源码中. 目标:爬取豆瓣电影TOP250的所有电影名称,网址为:https://movie.douban.com/t ...
- 爬虫——正则表达式爬取豆瓣电影TOP前250的中英文名
正则表达式爬取豆瓣电影TOP前250的中英文名 1.首先要实现网页的数据的爬取.新建test.py文件 test.py 1 import requests 2 3 def get_Html_text( ...
- 爬虫系列1:Requests+Xpath 爬取豆瓣电影TOP
爬虫1:Requests+Xpath 爬取豆瓣电影TOP [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]: ...
- 利用Python爬取豆瓣电影
目标:使用Python爬取豆瓣电影并保存MongoDB数据库中 我们先来看一下通过浏览器的方式来筛选某些特定的电影: 我们把URL来复制出来分析分析: https://movie.douban.com ...
- python 爬取豆瓣电影评论,并进行词云展示及出现的问题解决办法
本文旨在提供爬取豆瓣电影<我不是药神>评论和词云展示的代码样例 1.分析URL 2.爬取前10页评论 3.进行词云展示 1.分析URL 我不是药神 短评 第一页url https://mo ...
- python爬取豆瓣电影信息数据
题外话+ 大家好啊,最近自己在做一个属于自己的博客网站(准备辞职回家养老了,明年再战)在家里 琐事也很多, 加上自己 一回到家就懒了(主要是家里冷啊! 广东十几度,老家几度,躲在被窝瑟瑟发抖,) 由于 ...
- python 爬取豆瓣电影短评并wordcloud生成词云图
最近学到数据可视化到了词云图,正好学到爬虫,各种爬网站 [实验名称] 爬取豆瓣电影<千与千寻>的评论并生成词云 1. 利用爬虫获得电影评论的文本数据 2. 处理文本数据生成词云图 第一步, ...
随机推荐
- xss payload大全
刚好刚才在fuzz一个站的时候用到,就从笔记里抛出来了. code: (1)普通的XSS JavaScript注入 <SCRIPT SRC=http://3w.org/XSS/xss.js> ...
- shell编程系列24--shell操作数据库实战之利用shell脚本将文本数据导入到mysql中
shell编程系列24--shell操作数据库实战之利用shell脚本将文本数据导入到mysql中 利用shell脚本将文本数据导入到mysql中 需求1:处理文本中的数据,将文本中的数据插入到mys ...
- 【转载】 导入GoogleClusterData到MySQL
原文地址: https://www.cnblogs.com/instant7/p/4159022.html ---------------------------------------------- ...
- ISO/IEC 9899:2011 条款6.8.6——跳转语句
6.8.6 跳转语句 语法 1.jump-statement: goto identifier ; continue ; break ; return expressio ...
- ISO/IEC 9899:2011 条款6.5.10——按位与操作符
6.5.10 按位与操作符 语法 1.AND-expression: equality-expression AND-expression equality-expression 约束 2.这些 ...
- 为何windows自带的文件搜索这么慢,而Everything的这么快
为何windows自带的文件搜索这么慢,而Everything的这么快 摘自:http://blog.sina.com.cn/s/blog_9f0cf4ed0102wvkq.html (2016-07 ...
- SpringBoot学习笔记:读取配置文件
SpringBoot学习笔记:读取配置文件 配置文件 在以往的项目中,我们主要通过XML文件进行框架配置,业务的相关配置会放在属性文件中,然后通过一个属性读取的工具类来读取配置信息.在SpringBo ...
- git的使用学习(五)git的分支管理
分支管理 分支就是科幻电影里面的平行宇宙,当你正在电脑前努力学习Git的时候,另一个你正在另一个平行宇宙里努力学习SVN. 如果两个平行宇宙互不干扰,那对现在的你也没啥影响.不过,在某个时间点,两个平 ...
- 【计算机视觉】基于局部二值相似性模式(LBSP)的运动目标检测算法
基于局部二值相似性模式(LBSP)的运动目标检测算法 kezunhai@gmail.com http://blog.csdn.net/kezunhai 本文根据论文:Improving backgro ...
- 一次性清除页面上的所有setInterval
参考链接:https://www.cnblogs.com/liujinyu/p/3668575.html