python 爬取豆瓣电影评论,并进行词云展示及出现的问题解决办法
本文旨在提供爬取豆瓣电影《我不是药神》评论和词云展示的代码样例
1、分析URL
2、爬取前10页评论
3、进行词云展示
1、分析URL
我不是药神 短评
第一页url
https://movie.douban.com/subject/26752088/comments?start=0&limit=20&sort=new_score&status=P
第二页url
https://movie.douban.com/subject/26752088/comments?start=20&limit=20&sort=new_score&status=P
…
…
…
第十页url
https://movie.douban.com/subject/26752088/comments?start=180&limit=20&sort=new_score&status=P
分析发现每次变化的只是…strat=后面的数字,其他内容不变,可以以此遍历每一页的评论。
2、爬取前10页评论
代码:
import urllib.request
from bs4 import BeautifulSoup
def getHtml(url):
"""获取url页面"""
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'}
req = urllib.request.Request(url,headers=headers)
req = urllib.request.urlopen(req)
content = req.read().decode('utf-8')
return content
def getComment(url):
"""解析HTML页面"""
#html = getHtml(url)
response = urllib.request.urlopen(url)
html = response.read()
html = html.decode('utf-8','ignore')
soupComment = BeautifulSoup(html, 'html.parser')
comments = soupComment.findAll('span', 'short')
onePageComments = []
for comment in comments:
# print(comment.getText()+'\n')
onePageComments.append(comment.getText()+'\n')
return onePageComments
if __name__ == '__main__':
f = open('我不是药神page10.txt', 'w', encoding='utf-8')
for page in range(10): #爬取10页的评论
url = 'https://movie.douban.com/subject/26752088/comments?start=' + str(20*page) + '&limit=20&sort=new_score&status=P'
print('第%s页的评论:' % (page+1))
print(url + '\n')
for i in getComment(url):
f.write(i)
print(i)
print('\n')
★★问题出现:
(1)当IDLE Python3.5运行时出现下面问题:

运行结果的文件“我不是药神page10.txt”是空白的
(2)在cmd下运行出现:
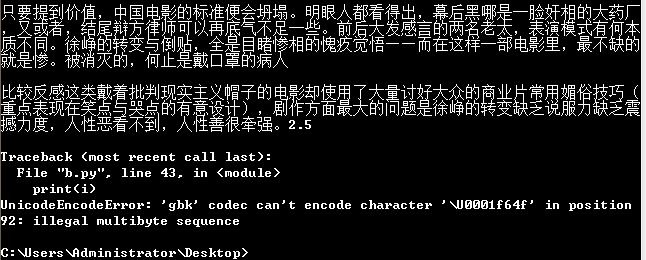
运行结果的文件“我不是药神page10.txt”是只有一小部分
★★★★完美解决办法:
修改控制台编码:
命令行输入 chcp
输出显示:活动代码页: 936
表示当前的编码是默认的gbk
修改编码:
命令行输入 chcp 65001
表示转换成utf8
然后在cmd运行python a.py(文件名)就可以成功print爬取的中文文章
★★★★★★★★常见编码:
utf8 所有语言
gbk 简体中文
gb2312 简体中文
gb18030 简体中文
big5 繁体中文
big5hkscs 繁体中文
3、进行词云展示
代码:
import matplotlib.pyplot as plt
from wordcloud import WordCloud
from scipy.misc import imread
import jieba
text = open("我不是药神page20.txt","rb").read()
#结巴分词
wordlist = jieba.cut(text,cut_all=True)
wl = " ".join(wordlist)
#print(wl)#输出分词之后的txt
#把分词后的txt写入文本文件
fenciTxt = open("fenciHou.txt","w+")
fenciTxt.writelines(wl)
fenciTxt.close()
#设置词云
wc = WordCloud(background_color = "white", #设置背景颜色
mask = imread('hai.jpg'), #找张图片设置背景图片
max_words = 2000, #设置最大显示的字数
stopwords = ["的", "这种", "这样", "还是", "就是", "这个"], #设置停用词
font_path = "C:\Windows\Fonts\simkai.ttf", # 设置为楷体 常规
#设置中文字体,使得词云可以显示(词云默认字体是“DroidSansMono.ttf字体库”,不支持中文)
max_font_size = 60, #设置字体最大值
random_state = 30, #设置有多少种随机生成状态,即有多少种配色方案
)
myword = wc.generate(wl)#生成词云
wc.to_file('result.jpg')
#展示词云图
plt.imshow(myword)
plt.axis("off")
plt.show()
结果:

python 爬取豆瓣电影评论,并进行词云展示及出现的问题解决办法的更多相关文章
- scrapy-redis爬取豆瓣电影短评,使用词云wordcloud展示
1.数据是使用scrapy-redis爬取的,存放在redis里面,爬取的是最近大热电影<海王> 2.使用了jieba中文分词解析库 3.使用了停用词stopwords,过滤掉一些无意义的 ...
- python爬取豆瓣流浪地球影评,生成词云
代码很简单,一看就懂. (没有模拟点击,所以都是未展开的) 地址: https://movie.douban.com/subject/26266893/reviews?rating=&star ...
- 利用Python爬取豆瓣电影
目标:使用Python爬取豆瓣电影并保存MongoDB数据库中 我们先来看一下通过浏览器的方式来筛选某些特定的电影: 我们把URL来复制出来分析分析: https://movie.douban.com ...
- 爬虫系列(十一) 用requests和xpath爬取豆瓣电影评论
这篇文章,我们继续利用 requests 和 xpath 爬取豆瓣电影的短评,下面还是先贴上效果图: 1.网页分析 (1)翻页 我们还是使用 Chrome 浏览器打开豆瓣电影中某一部电影的评论进行分析 ...
- Python爬取豆瓣电影top
Python爬取豆瓣电影top250 下面以四种方法去解析数据,前面三种以插件库来解析,第四种以正则表达式去解析. xpath pyquery beaufifulsoup re 爬取信息:名称 评分 ...
- python 爬取豆瓣电影短评并wordcloud生成词云图
最近学到数据可视化到了词云图,正好学到爬虫,各种爬网站 [实验名称] 爬取豆瓣电影<千与千寻>的评论并生成词云 1. 利用爬虫获得电影评论的文本数据 2. 处理文本数据生成词云图 第一步, ...
- python爬取豆瓣电影信息数据
题外话+ 大家好啊,最近自己在做一个属于自己的博客网站(准备辞职回家养老了,明年再战)在家里 琐事也很多, 加上自己 一回到家就懒了(主要是家里冷啊! 广东十几度,老家几度,躲在被窝瑟瑟发抖,) 由于 ...
- 零基础爬虫----python爬取豆瓣电影top250的信息(转)
今天利用xpath写了一个小爬虫,比较适合一些爬虫新手来学习.话不多说,开始今天的正题,我会利用一个案例来介绍下xpath如何对网页进行解析的,以及如何对信息进行提取的. python环境:pytho ...
- python爬取豆瓣电影Top250(附完整源代码)
初学爬虫,学习一下三方库的使用以及简单静态网页的分析.就跟着视频写了一个爬取豆瓣Top250排行榜的爬虫. 网页分析 我个人感觉写爬虫最重要的就是分析网页,找到网页的规律,找到自己需要内容所在的地方, ...
随机推荐
- golang开发:类库篇(一) Zap高性能日志类库的使用
为什么要用zap来写日志 原来是写PHP的,一直用的error_log,第一次写Go项目的时候,还真不知道该怎么写日志,后来就按照PHP的写法自己不成规范的捣鼓写.去了新公司之后,发现用的是zap.后 ...
- prometheus-operator监控Kubernetes
Operator Operator是由CoreOS公司开发的,用来扩展 Kubernetes API,特定的应用程序控制器,它用来创建.配置和管理复杂的有状态应用,如数据库.缓存和监控系统.Opera ...
- kuberbetes基础概念
部署了一大堆,来了解一下K8S一些基本的概念. 1.Node Node作为集群中的工作节点,运行真正的应用程序,在Node上Kubernetes管理的最小运行单元是Pod.Node上运行着Kubern ...
- QDomDocument 读取和编辑xml文件
Qt中几种操作xml的方式 流方式 sax方式 dom方式 初学时,我常常采用流方式读取xml,该方式简单直观,容易理解.之后遇到了需要修改xml并重新写回的情况,流方式就显得捉襟见肘了. sax方式 ...
- 漫谈Redis分布式锁实现
在Redis上,可以通过对key值的独占来实现分布式锁,表面上看,Redis可以简单快捷通过set key这一独占的方式来实现分布式锁,也有许多重复性轮子,但实际情况并非如此.总得来说,Redis实现 ...
- Spring 入门程序
1.0 导包的时候要注意: 以上的第一个是.class文件 以上的第二个是文件的解释性页面. 以上的第三个是.java文件 2.0 配置文件需要导入依赖(有dtd 依赖,也有xsd依赖) ² 从be ...
- 《Python 3.5从零开始学》笔记-第8章 面向对象编程
前几章包括开启python之旅.列表和元组.字符串.字典.条件和循环等语句.函数等基本操作.主要对后面几章比较深入的内容记录笔记. 第8章 面向对象编程 8.3深入类 #!/usr/local/bin ...
- c++ 函数知识点汇总
c++ 函数知识点汇总 swap函数 交换两个数组元素 比如 swap(a[i],a[j]); 就是交换a[i] 和 a[j] 的值 strcpy() 复制一个数组元素的值到另一个数组元素里 strc ...
- JsonUtil(基于Jackson的实现)
JsonUtil(基于Jackson的实现) 前言: 其实,我一直想写一个有关Util的系列. 其中有四个原因: Util包作为项目的重要组成,是几乎每个项目不可或缺的一部分.并且Util包的Util ...
- 数据结构-双向链表(Python实现)
数据结构在编程世界中一直是非常重要的一环,不管是开发还是算法,哪怕是单纯为了面试,数据结构都是必修课,今天我们介绍链表中的一种--双向链表的代码实现. 好了,话不多说直接上代码. 双向链表 首先,我们 ...