用python爬取豆瓣电影Top 250
首先,打开豆瓣电影Top 250,然后进行网页分析。找到它的Host和User-agent,并保存下来。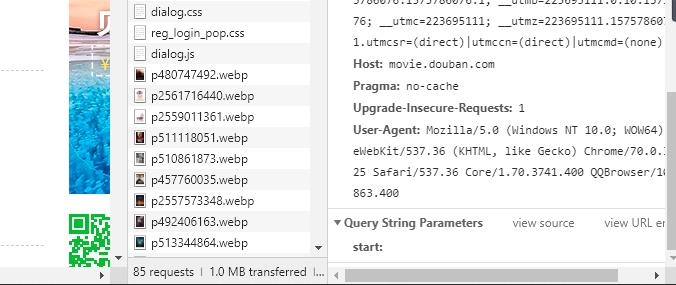 然后,我们通过翻页,查看各页面的url,发现规律:
然后,我们通过翻页,查看各页面的url,发现规律:
第一页:https://movie.douban.com/top250?start=0&filter=
第二页:https://movie.douban.com/top250?start=25&filter=
第三页:https://movie.douban.com/top250?start=50&filter=
第四页:https://movie.douban.com/top250?start=75&filter=
我们发现,每个页面的url都是https://movie.douban.com/top250?start= +25+ &filter=的规律。如此,就可以开始写代码:
import requests
from bs4 import BeautifulSoup
def get_movie():
headers={
'Host': 'movie.douban.com',
'User-Agent': 'Mozilla / 5.0(Windows NT 6.1;WOW64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 45.0.2454.101Safari / 537.36'
} #防止反扒措施
movie_list=[]
for i in range(10):
url='https://movie.douban.com/top250?start='+str(i*25) #各页面url
response=requests.get(url,headers=headers,timeout=10)
soup=BeautifulSoup(response.text,'lxml')
div_list=soup.find_all('div',class_='hd')
for each in div_list:
movie=each.a.span.text.strip()
movie_list.append(movie)
for j in movie_list:
print(j) #按格式输出电影名称
get_movie()
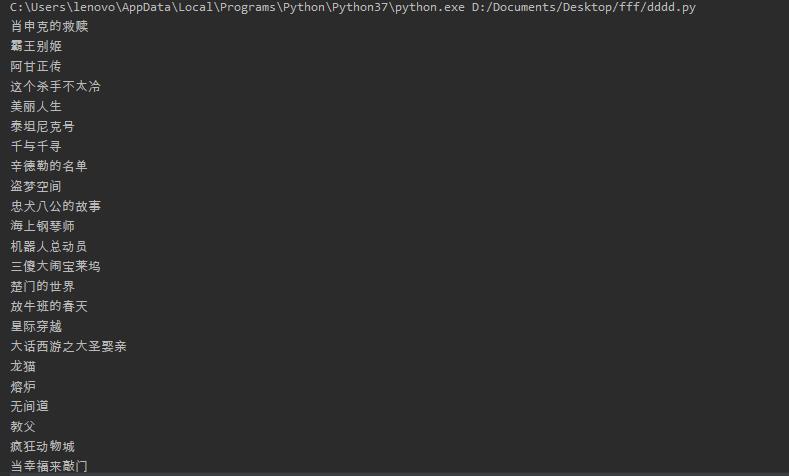
下面给出运行结果:
用python爬取豆瓣电影Top 250的更多相关文章
- 爬取豆瓣电影TOP 250的电影存储到mongodb中
爬取豆瓣电影TOP 250的电影存储到mongodb中 1.创建项目sp1 PS D:\scrapy> scrapy.exe startproject douban 2.创建一个爬虫 PS D: ...
- Python爬取豆瓣电影top
Python爬取豆瓣电影top250 下面以四种方法去解析数据,前面三种以插件库来解析,第四种以正则表达式去解析. xpath pyquery beaufifulsoup re 爬取信息:名称 评分 ...
- Python开发爬虫之静态网页抓取篇:爬取“豆瓣电影 Top 250”电影数据
所谓静态页面是指纯粹的HTML格式的页面,这样的页面在浏览器中展示的内容都在HTML源码中. 目标:爬取豆瓣电影TOP250的所有电影名称,网址为:https://movie.douban.com/t ...
- 爬虫——正则表达式爬取豆瓣电影TOP前250的中英文名
正则表达式爬取豆瓣电影TOP前250的中英文名 1.首先要实现网页的数据的爬取.新建test.py文件 test.py 1 import requests 2 3 def get_Html_text( ...
- 爬虫系列1:Requests+Xpath 爬取豆瓣电影TOP
爬虫1:Requests+Xpath 爬取豆瓣电影TOP [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]: ...
- 利用Python爬取豆瓣电影
目标:使用Python爬取豆瓣电影并保存MongoDB数据库中 我们先来看一下通过浏览器的方式来筛选某些特定的电影: 我们把URL来复制出来分析分析: https://movie.douban.com ...
- python 爬取豆瓣电影评论,并进行词云展示及出现的问题解决办法
本文旨在提供爬取豆瓣电影<我不是药神>评论和词云展示的代码样例 1.分析URL 2.爬取前10页评论 3.进行词云展示 1.分析URL 我不是药神 短评 第一页url https://mo ...
- python爬取豆瓣电影信息数据
题外话+ 大家好啊,最近自己在做一个属于自己的博客网站(准备辞职回家养老了,明年再战)在家里 琐事也很多, 加上自己 一回到家就懒了(主要是家里冷啊! 广东十几度,老家几度,躲在被窝瑟瑟发抖,) 由于 ...
- python 爬取豆瓣电影短评并wordcloud生成词云图
最近学到数据可视化到了词云图,正好学到爬虫,各种爬网站 [实验名称] 爬取豆瓣电影<千与千寻>的评论并生成词云 1. 利用爬虫获得电影评论的文本数据 2. 处理文本数据生成词云图 第一步, ...
随机推荐
- springboot mybatis的pagehelper分页
maven repositary里,分页组件常用的有两个 com.github.pagehelper » pagehelper-spring-boot-starter com.github.page ...
- 方法不会等待Task执行完才返回数据
- 反射load,loadfile,LoadFrom区别
反射加载数据用法 Load Assembly assembly = Assembly.Load("Ruanmou.DB.MySql");//dll名称无后缀 从当前目录加载dll ...
- 在gitlab新建分支,IDEA切换时找不到的解决办法
VCS——>Git——>Fetch
- Ubuntu与Window双系统安装的注意事项
UBUNTU与WINDOW双系统安装的注意事项 Ubuntu与Window双系统安装的注意事项 由 匿名 (未验证) 提交于 2019-05-18 10:07:41 登录 发表评论 29 次浏览 ...
- 为做个程序员英语字典,我处理了StackOverflow和HackerNews10年5千万条数据
有点标题党,不过都说都真实的.英语技能对开发员人员至关重要.所有人都不喜欢背单词,但更惨的是背住的单词发现没怎么用,又慢慢地忘记了.本来计划给自己做个开发人员常用单词表,感觉可能对其它人也有用,所以就 ...
- Swoole练习 TCP
TCP <?php $serv = new swoole_server("127.0.0.1", 9501); //监听连接进入事件 $serv->on('connec ...
- 01. xadmin表单的自定义排版
xadmin表单的自定义布局(重写 get_form_layout()) apps.courses.adminx.py class NewCoursesAdmin(object): list_disp ...
- 《ucore lab4》实验报告
资源 ucore在线实验指导书 我的ucore实验代码 练习1:分配并初始化一个进程控制块 题目 alloc_proc函数(位于kern/process/proc.c中) 负责分配并返回一个新的str ...
- Ribbon学习笔记
微服务的概念: Ribbon默认的是轮询的算法: @LoadBalanced @EnableEurekaClient Irule是根据 Ribbon默认(轮询)的7中负载均衡的算法: 修改默认的R ...