(十三)SpringBoot之Spring-Data-Jpa(二)CRUD实现以及添加自定义方法
一、jpa中添加自定义方法
- http://blog.csdn.net/qq_23660243/article/details/43194465
二、案例
1.3 引入jpa依赖
<dependencies>
<!-- 除去logback支持 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-logging</artifactId>
</exclusion>
</exclusions>
</dependency> <dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- 使用log4j2,该包paren标签中已经依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-log4j2</artifactId>
</dependency> <dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
</dependency> <!-- 引入freemarker包 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-freemarker</artifactId>
</dependency> <dependency>
<groupId>org.apache.tomcat.embed</groupId>
<artifactId>tomcat-embed-jasper</artifactId>
<scope>provided</scope>
</dependency> <dependency>
<groupId>javax.servlet</groupId>
<artifactId>jstl</artifactId>
</dependency> <!-- 数据库 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
</dependencies>
1.2 编写application.properties
#主配置文件,配置了这个会优先读取里面的属性覆盖主配置文件的属性
spring.profiles.active=dev
server.port=8888 logging.config=classpath:log4j2-dev.xml
spring.mvc.view.prefix: /WEB-INF/templates/
spring.mvc.view.suffix: .jsp #数据库连接配置
spring.datasource.url=jdbc:mysql://localhost/db_boot?useUnicode=true&characterEncoding=utf-8
spring.datasource.username=root
spring.datasource.password=
spring.datasource.driver-class-name=com.mysql.jdbc.Driver spring.jpa.generate-ddl=true
spring.jpa.show-sql=true
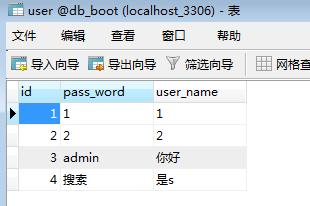
1.3 生成表数据
package com.shyroke.entity; import java.io.Serializable; import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.Id;
import javax.persistence.Table; @Entity
@Table(name="user")
public class UserBean implements Serializable { @Id
@GeneratedValue
private Integer id;
@Column
private String userName;
@Column
private String passWord; public Integer getId() {
return id;
} public void setId(Integer id) {
this.id = id;
} public String getUserName() {
return userName;
} public void setUserName(String userName) {
this.userName = userName;
} public String getPassWord() {
return passWord;
} public void setPassWord(String passWord) {
this.passWord = passWord;
} @Override
public String toString() {
return "UserBean [id=" + id + ", userName=" + userName + ", passWord=" + passWord + "]";
}
}
- 执行下面代码,就会在数据库中生成相应的表结构,然后插入一些测试数据。
package com.shyroke; import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.boot.web.servlet.ServletListenerRegistrationBean;
import org.springframework.boot.web.servlet.ServletRegistrationBean;
import org.springframework.context.annotation.Bean; import util.MyFilter;
import util.MyListener;
import util.MyServlet; @SpringBootApplication
public class Springboot01Application { public static void main(String[] args) {
SpringApplication.run(Springboot01Application.class, args);
}
}
1.4 编写控制器
package com.shyroke.controller; import java.util.List; import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody; import com.shyroke.dao.UserMapper;
import com.shyroke.entity.UserBean; @Controller
@RequestMapping(value = "/")
public class IndexController { @Autowired
private UserMapper userMapper; @RequestMapping(value="index")
public String index() {
return "index";
} @RequestMapping()
public String index2() {
return "index";
} @ResponseBody
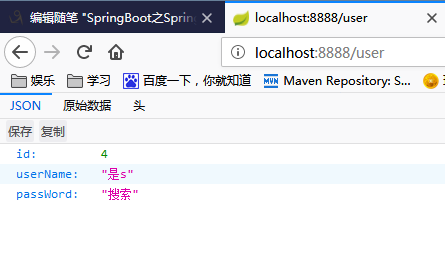
@RequestMapping(value="/user")
public UserBean list() {
List<UserBean> userList=userMapper.findAll();
for(UserBean user:userList) {
System.out.println(user);
} System.out.println("========================"); UserBean user=userMapper.findOne(4); return user;
}
}
1.5 编写mapper
package com.shyroke.dao;
import org.springframework.data.jpa.repository.JpaRepository;
import com.shyroke.entity.UserBean;
public interface UserMapper extends JpaRepository<UserBean, Integer>{
}
1.6 测试

(十三)SpringBoot之Spring-Data-Jpa(二)CRUD实现以及添加自定义方法的更多相关文章
- spring-boot (三) spring data jpa
学习文章来自:http://www.ityouknow.com/spring-boot.html spring data jpa介绍 首先了解JPA是什么? JPA(Java Persistence ...
- spring boot学习(4) SpringBoot 之Spring Data Jpa 支持(1)
第一节:Spring Data Jpa 简介 Spring-Data-Jpa JPA(Java Persistence API)定义了一系列对象持久化的标准,目前实现这一规范的产品有Hibernate ...
- springboot整合spring Data JPA
今天敲代码,一连串的错误,我也是服气~果然,我们不是在出bug,就是在找bug的路上…… 今天完成的是springboot整合spring data JPA ,出了一连串的错,真是头大 java.sq ...
- springboot整合spring data jpa 动态查询
Spring Data JPA虽然大大的简化了持久层的开发,但是在实际开发中,很多地方都需要高级动态查询,在实现动态查询时我们需要用到Criteria API,主要是以下三个: 1.Criteria ...
- <Spring Data JPA>二 Spring Data Jpa
1.pom依赖 <?xml version="1.0" encoding="UTF-8"?> <project xmlns="htt ...
- springboot集成Spring Data JPA数据查询
1.JPA介绍 JPA(Java Persistence API)是Sun官方提出的Java持久化规范.它为Java开发人员提供了一种对象/关联映射工具来管理Java应用中的关系数据.它的出现主要是为 ...
- Spring Data Jpa (二)JPA基础查询
介绍Spring Data Common里面的公用基本方法 (1)Spring Data Common的Repository Repository位于Spring Data Common的lib里面, ...
- IntelliJ IDEA 2017版 spring-boot使用Spring Data JPA使用Repository<T, T>编程
1.环境搭建pom.xml搭建 <?xml version="1.0" encoding="UTF-8"?> <project xmlns=& ...
- spring boot学习(5) SpringBoot 之Spring Data Jpa 支持(2)
第三节:自定义查询@Query 有时候复杂sql使用hql方式无法查询,这时候使用本地查询,使用原生sql的方式: 第四节:动态查询Specification 使用 什么时候用呢?比如搜索有很多条 ...
- IntelliJ IDEA 2017版 spring-boot使用Spring Data JPA搭建基础版的三层架构
1.配置环境pom <?xml version="1.0" encoding="UTF-8"?> <project xmlns="h ...
随机推荐
- Linux虚拟化与容器化
随着云计算的不断发展,计算资源不断集中于大规模的服务器集群上.为了充分发挥硬件潜力,提高服务器性能,虚拟化技术由此诞生. 所谓虚拟化技术,是指将计算元件和硬件隔离开来,隐藏底层的硬件物理特性,为用户提 ...
- OpenJudge计算概论-矩阵交换行
/*======================================================================== 矩阵交换行 总时间限制: 1000ms 内存限制: ...
- ArcGIS 10.5 tensorflow安装日记
ArcGIS 10.5 tensorflow安装日记 商务科技合作:向日葵,135-4855__4328,xiexiaokui#qq.com Datetime: 2019年5月27日星期一 Os: w ...
- Angular 执行 css3 简单的动画
<div class="content"> 内容区域 <button (click)="showAside()">弹出侧边栏</b ...
- ISO/IEC 9899:2011 条款6.4.5——字符串字面量
6.4.5 字符串字面量 语法 1.string-literal: encoding-prefixopt " s-char-sequenceopt " encoding- ...
- docker之redis使用
#拉取redis > docker pull redis:latest latest: Pulling from library/redis 8d691f585fa8: Pull complet ...
- thymeleaf中分类信息使用不同的样式
需求: 相关class类名:S224_on_point url:/notification/list url:/notification/list?type=2 thymeleaf代码如下: < ...
- python 函数、参数及参数解构
函数 数学定义 y=f(x), y是x函数,x是自变量.y=f(x0,x1...xn) Python函数 由若干语句组成的语句块,函数名称,参数列表构成,它是组织代码的最小单位 完成一定的功能 函数作 ...
- Spark2.x学习笔记:5、Spark On YARN模式
https://blog.csdn.net/chengyuqiang/article/details/77864246
- topK问题
概述 在N个乱序数字中查找第K大的数字,时间复杂度可以减小至O(N). 可能存在的限制条件: 要求时间和空间消耗最小.海量数据.待排序的数据可能是浮点型等. 方法 方法一 对所有元素进行排序,之后取出 ...