Deep Learning学习随记(一)稀疏自编码器
最近开始看Deep Learning,随手记点,方便以后查看。
主要参考资料是Stanford 教授 Andrew Ng 的 Deep Learning 教程讲义:http://deeplearning.stanford.edu/wiki/index.php/UFLDL_Tutorial。这个讲义已经有人翻译了(赞一个),可以参见邓侃的新浪博客http://blog.sina.com.cn/s/blog_46d0a3930101h6nf.html。另外,博客园里有一个前辈关于讲义中练习的一系列文章,在具体实现时可以参照下:http://www.cnblogs.com/tornadomeet/category/497607.html
讲义从稀疏自编码(Sparse Autoencoder)这一章节开始讲起。前面三节是神经网络、BP神经网络以及梯度检验的方法。由于还有点神经网络的相关知识,这部分不是太难懂。就从自编码器和稀疏性(Autoencoders and sparisity)记起吧。
稀疏自编码器构建:
假设我们只有一个没有类别标签的训练样本集合{x(1),x(2)...},一个自编码神经网络就是一种非监督学习算法,它使用BP算法,并将目标值设为输入值(y(i)=x(i))。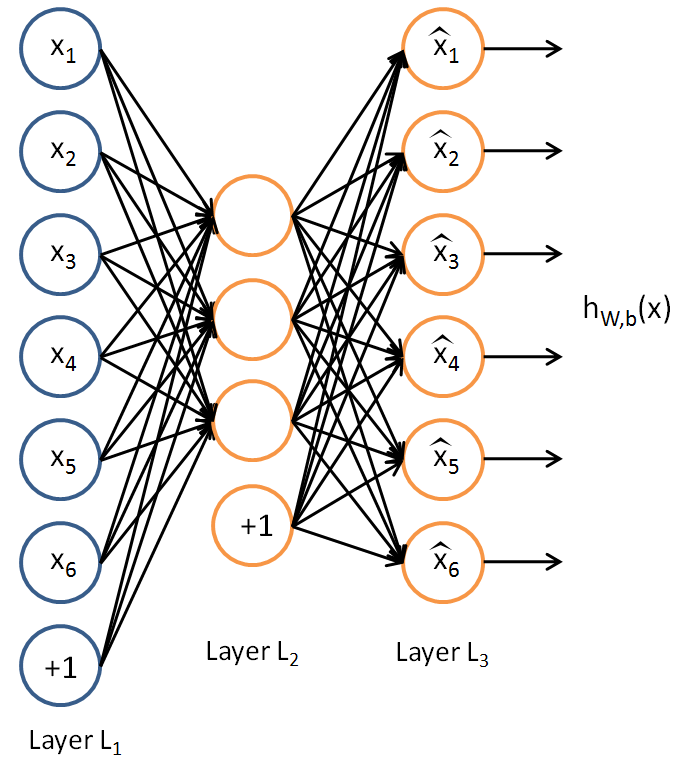
我们的目标是希望得到hW,b(X)≈x。用aj(2)(x)表示输入向量x对隐藏层单元j的激活值。则j的平均激活值:
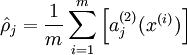
为了达到稀疏性,也即用最少(最稀疏)的隐藏单元来表示输入层的特征,我们希望所有隐藏层单元平均激活值接近于0.于是应用KL距离:
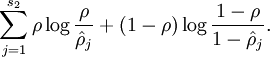
其中为了方便书写: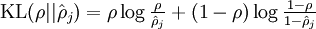 。
。
其中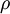 是稀疏参数,一般来说选一个很小的数,如0.05。
是稀疏参数,一般来说选一个很小的数,如0.05。
这样,神经网络整体代价函数就可以表示为: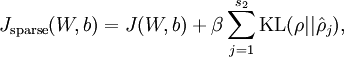 ,其中J(W,b)在前面BP网络章节中介绍过。
,其中J(W,b)在前面BP网络章节中介绍过。
讲义中同时给出了这种情况下如何计算用于偏导数计算的残差,自己懒得去推导了,直接拿来用就好了:
将反向传导过程中残差计算公式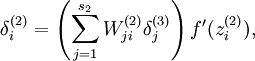 改为:
改为: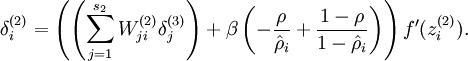 即可。
即可。
这样,一个稀疏自编码器就完成了。
个人感觉这个跟PCA貌似有点类似,可以将数据的维度降到很低(稀疏性嘛,用几个有用的隐层就可以表示出原始数据)。从Visualizing a Trained Autoencoder这节的结果来看,应该是这么个情况。
练习:
讲义中还给出了一个Exercise,Matlab用的不熟啊,这里去看了tornadomeet的博文http://www.cnblogs.com/tornadomeet/archive/2013/03/20/2970724.html,里面将代码实现了(膜拜下~),自己下下来跑了一下,结果什么的都跟原来博文一样(废话了,同一个程序,哈哈),最后没有收敛,迭代400次终止了。同时发现matlab貌似有点好用啊。。。这么几行代码就实现了,让我这用惯了C的情何以堪...回去自己补一下matlab了。
Deep Learning学习随记(一)稀疏自编码器的更多相关文章
- Deep Learning 学习随记(六)Linear Decoder 线性解码
线性解码器(Linear Decoder) 前面第一章提到稀疏自编码器(http://www.cnblogs.com/bzjia-blog/p/SparseAutoencoder.html)的三层网络 ...
- Deep Learning 学习随记(五)Deep network 深度网络
这一个多周忙别的事去了,忙完了,接着看讲义~ 这章讲的是深度网络(Deep Network).前面讲了自学习网络,通过稀疏自编码和一个logistic回归或者softmax回归连接,显然是3层的.而这 ...
- Deep Learning 学习随记(四)自学习和非监督特征学习
接着看讲义,接下来这章应该是Self-Taught Learning and Unsupervised Feature Learning. 含义: 从字面上不难理解其意思.这里的self-taught ...
- Deep Learning学习随记(二)Vectorized、PCA和Whitening
接着上次的记,前面看了稀疏自编码.按照讲义,接下来是Vectorized, 翻译成向量化?暂且这么认为吧. Vectorized: 这节是老师教我们编程技巧了,这个向量化的意思说白了就是利用已经被优化 ...
- Deep Learning 学习随记(八)CNN(Convolutional neural network)理解
前面Andrew Ng的讲义基本看完了.Andrew讲的真是通俗易懂,只是不过瘾啊,讲的太少了.趁着看完那章convolution and pooling, 自己又去翻了翻CNN的相关东西. 当时看讲 ...
- Deep Learning 学习随记(七)Convolution and Pooling --卷积和池化
图像大小与参数个数: 前面几章都是针对小图像块处理的,这一章则是针对大图像进行处理的.两者在这的区别还是很明显的,小图像(如8*8,MINIST的28*28)可以采用全连接的方式(即输入层和隐含层直接 ...
- Deep Learning 学习随记(五)深度网络--续
前面记到了深度网络这一章.当时觉得练习应该挺简单的,用不了多少时间,结果训练时间真够长的...途中debug的时候还手贱的clear了一下,又得从头开始运行.不过最终还是调试成功了,sigh~ 前一篇 ...
- Deep Learning 学习随记(三)Softmax regression
讲义中的第四章,讲的是Softmax 回归.softmax回归是logistic回归的泛化版,先来回顾下logistic回归. logistic回归: 训练集为{(x(1),y(1)),...,(x( ...
- Deep Learning 学习随记(三)续 Softmax regression练习
上一篇讲的Softmax regression,当时时间不够,没把练习做完.这几天学车有点累,又特别想动动手自己写写matlab代码 所以等到了现在,这篇文章就当做上一篇的续吧. 回顾: 上一篇最后给 ...
随机推荐
- Important Programming Concepts (Even on Embedded Systems) Part V: State Machines
Earlier articles in this series: Part I: Idempotence Part II: Immutability Part III: Volatility Part ...
- backbone初次使用及hello world
官网:http://backbonejs.org/ Backbone.js gives structure to web applications by providing models with k ...
- Volatile vs. Interlocked vs. lock
今天在stackoverflow上看到一个关于Volatile, Interlock, Lock的问题,发现回答的特别好,所以就想到把它翻译一下, 希望给那些对它们有疑惑的人提供点帮助 :假设有一个类 ...
- WordPress BulletProof Security插件多个HTML注入漏洞
漏洞名称: WordPress BulletProof Security插件多个HTML注入漏洞 CNNVD编号: CNNVD-201308-023 发布时间: 2013-08-06 更新时间: 20 ...
- [Poetize I]黑魔法师之门
描述 Description applepi被囚禁的地点只有一扇门,当地 人称它为“黑魔法师之门”.这扇门上画着一张无向无权图,而打开这扇门的密码就是图中[每个点的度数大于零且都是偶数]的子图的个数对 ...
- 南桥先生谈《OUTLIERS》
借来一套语音版的 Outliers 听完了.这本书里有很多故事,可是希望借此找到成功的奥秘恐怕很难,作者做的是一描述而不是预见.听了半天,只听出了六个字: “天时地利人和”. 比如比尔·盖茨,他之所以 ...
- UVAlive3415 Guardian of Decency(最大独立集)
题目链接:http://acm.hust.edu.cn/vjudge/problem/viewProblem.action?id=34831 [思路] 二分图的最大独立集. 即在二分图中选取最多的点, ...
- Postman 基本操作学习
History 所有使用postman发送的request都会保存在这里.点击之后会在当前Tab打开. 参考: Requests History Environments 这里用来设定当前reques ...
- Linux内存寻址之分段机制
前言 最近在学习Linux内核,读到<深入理解Linux内核>的内存寻址一章.原本以为自己对分段分页机制已经理解了,结果发现其实是一知半解.于是,查找了很多资料,最终理顺了内存寻址的知识. ...
- LibreOffice连接orcle 11g
1.安装java 2.安装JDBC 官网下载 复制到/usr/java/jdk1.8.0_111/jre/lib/ext文件下