Spark Mllib里的分布式矩阵(行矩阵、带有行索引的行矩阵、坐标矩阵和块矩阵概念、构成)(图文详解)
不多说,直接上干货!
Distributed matrix : 分布式矩阵 一般能采用分布式矩阵,说明这数据存储下来,量还是有一定的。
在Spark Mllib里,提供了四种分布式矩阵存储形式,均由支持长整形的行列数和双精度浮点型的数据内容组成。
包括行矩阵、带有行索引的行矩阵、坐标矩阵和块矩阵。 依据你数据的不同的特点,你可以选择不同类型的数据。
(1)、行矩阵: 以行为基本方向的矩阵存储格式,列的作用相对较少。
理解记忆,行矩阵是一个巨大的特征向量的集合
每一行就是一个具有相同格式的向量数据,且每一行的向量内容都可以单独取出来进行操作。
要注意的是,此种矩阵不能按照行号访问。(我也不知道为什么这样)
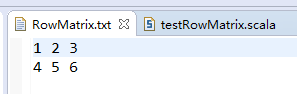
testRowMatrix.scala

package zhouls.bigdata.chapter4 import org.apache.spark._
import org.apache.spark.mllib.linalg.{Vector, Vectors}
import org.apache.spark.mllib.linalg.distributed.RowMatrix object testRowMatrix {
def main(args: Array[String]) {
val conf = new SparkConf() //创建环境变量
.setMaster("local") //设置本地化处理
.setAppName("testRowMatrix") //设定名称
val sc = new SparkContext(conf) //创建环境变量实例
val rdd = sc.textFile("data/input/chapter4/RowMatrix.txt") //创建RDD文件路径
.map(_.split(' ') //按“ ”分割
.map(_.toDouble)) //转成Double类型
.map(line => Vectors.dense(line)) //转成Vector格式
val rm = new RowMatrix(rdd) //读入行矩阵
println(rm.numRows()) //打印列数
println(rm.numCols()) //打印行数
}
}
这里,我带你是的
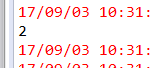
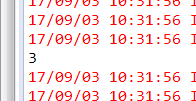
(2) 带有行索引的矩阵
单纯的行矩阵对其内容无法进行直接显示,当然可以通过调用其方法显示内部数据内推。即通过带有行索引的行矩阵。
IndexedRowMatrix矩阵和RowMatrix矩阵的不同之处在于,你可以通过索引值来访问每一行。其他的,没啥区别。
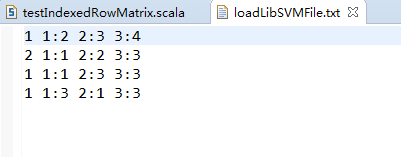
testIndexedRowMatrix.scala
package zhouls.bigdata.chapter4 import org.apache.spark._
import org.apache.spark.mllib.linalg.distributed.{IndexedRow, RowMatrix, IndexedRowMatrix}
import org.apache.spark.mllib.linalg.{Vector, Vectors} object testIndexedRowMatrix {
def main(args: Array[String]) {
val conf = new SparkConf() //创建环境变量
.setMaster("local") //设置本地化处理
.setAppName("testIndexedRowMatrix") //设定名称
val sc = new SparkContext(conf) //创建环境变量实例
val rdd = sc.textFile("data/input/chapter4/loadLibSVMFile.txt") //创建RDD文件路径
.map(_.split(' ') //按“ ”分割
.map(_.toDouble)) //转成Double类型
.map(line => Vectors.dense(line)) //转化成向量存储
.map((vd) => new IndexedRow(vd.size,vd)) //转化格式
val irm = new IndexedRowMatrix(rdd) //建立索引行矩阵实例
println(irm.getClass) //打印类型
println(irm.rows.foreach(println)) //打印内容数据
}
}
打印结果是
class org.apache.spark.mllib.linalg.distributed.IndexedRowMatrix
IndexedRow(3,[1.0,2.0,3.0])
IndexedRow(3,[4.0,5.0,6.0])
注意:IndexedRowMatrix除了这个带有行索引的行矩阵功能外,还有其他功能,如:
toRowMatrix将其转化成单纯的行矩阵,toCoordinateMatrix将其转化成坐标矩阵,toBlockMatrix将其转化成块矩阵。
(3) 坐标矩阵
是一种带有坐标标记的矩阵。
坐标矩阵一般用于数据比较多且数据较为分散的情形,即矩阵中含0或者某个具体值较多的情况下。
当你的数据特别稀疏的时候怎么办?采用这种坐标矩阵吧。
CoordinateMatrix矩阵中的存储形式是(row,col,value),就是原始的最稀疏的方式,所以如果矩阵比较稠密,别用这种数据格式。
其中的每一个具体数据都有一组坐标进行标示。其类型格式如下:
(x: Long , y:Long , value:Double)
x和y分别代表标示坐标的坐标轴标号,value是具体内容。x是行坐标,y是列坐标。
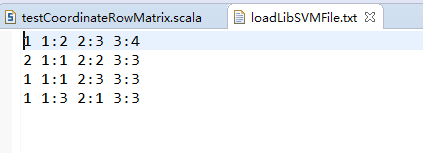
testCoordinateRowMatrix.scala
package zhouls.bigdata.chapter4 import org.apache.spark._
import org.apache.spark.mllib.linalg.{Vector, Vectors}
import org.apache.spark.mllib.linalg.distributed.{CoordinateMatrix, MatrixEntry} object testCoordinateRowMatrix {
def main(args: Array[String]) {
val conf = new SparkConf() //创建环境变量
.setMaster("local") //设置本地化处理
.setAppName("testCoordinateRowMatrix") //设定名称
val sc = new SparkContext(conf) //创建环境变量实例
val rdd = sc.textFile("data/input/chapter4/loadLibSVMFile.txt") //创建RDD文件路径
.map(_.split(' ') //按“ ”分割
.map(_.toDouble)) //转成Double类型
.map(vue => (vue(0).toLong,vue(1).toLong,vue(2))) //转化成坐标格式
.map(vue2 => new MatrixEntry(vue2 _1,vue2 _2,vue2 _3)) //转化成坐标矩阵格式
val crm = new CoordinateMatrix(rdd) //实例化坐标矩阵
println(crm.entries.foreach(println)) //打印数据
}
}
运行结果是,
MatrixEntry(1,2,3.0)
MatrixEntry(4,5,6.0)
Spark Mllib里的分布式矩阵(行矩阵、带有行索引的行矩阵、坐标矩阵和块矩阵概念、构成)(图文详解)的更多相关文章
- IDEA里点击Build,再Build Artifacts没反应,灰色的?解决办法(图文详解)
不多说,直接上干货! 问题详情 如下:点击Build ,再 Build -> Build Artifacts,没反应??? 解决办法 1.File,再Project Structure 2.然后 ...
- 如何在cmd窗口里快速且正确打开任意位置路径(各版本windows系统都适合)(图文详解)(博主推荐)
问题的由来 有时候,我们很苦恼,总是先系统键 + R,然后再去手动敲.尤其对win7系统比较麻烦 解决办法 方法一:复制路径(这点对win10系统做得好,直接可以复制) ,win7系统的话可能还需要设 ...
- Eclipse里Tomcat报错:Document base ……does not exist or is not a readable directory(图文详解)
问题描述: 严重: Error starting static Resourcesjava.lang.IllegalArgumentException: Document base D:\Code\M ...
- spark最新源码下载并导入到开发环境下助推高质量代码(Scala IDEA for Eclipse和IntelliJ IDEA皆适用)(以spark2.2.0源码包为例)(图文详解)
不多说,直接上干货! 前言 其实啊,无论你是初学者还是具备了有一定spark编程经验,都需要对spark源码足够重视起来. 本人,肺腑之己见,想要成为大数据的大牛和顶尖专家,多结合源码和操练编程. ...
- Spark Mllib里决策树回归分析使用.rootMeanSquaredError方法计算出以RMSE来评估模型的准确率(图文详解)
不多说,直接上干货! Spark Mllib里决策树二元分类使用.areaUnderROC方法计算出以AUC来评估模型的准确率和决策树多元分类使用.precision方法以precision来评估模型 ...
- Spark Mllib里决策树回归分析如何对numClasses无控制和将部分参数设置为variance(图文详解)
不多说,直接上干货! 在决策树二元或决策树多元分类参数设置中: 使用DecisionTree.trainClassifier 见 Spark Mllib里如何对决策树二元分类和决策树多元分类的分类 ...
- Spark Mllib里决策树二元分类使用.areaUnderROC方法计算出以AUC来评估模型的准确率和决策树多元分类使用.precision方法以precision来评估模型的准确率(图文详解)
不多说,直接上干货! Spark Mllib里决策树二元分类使用.areaUnderROC方法计算出以AUC来评估模型的准确率 具体,见 Hadoop+Spark大数据巨量分析与机器学习整合开发实战的 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- Scala IDEA for Eclipse里用maven来创建scala和java项目代码环境(图文详解)
这篇博客 是在Scala IDEA for Eclipse里手动创建scala代码编写环境. Scala IDE for Eclipse的下载.安装和WordCount的初步使用(本地模式和集群模式) ...
随机推荐
- str_2.判断两个字符串是否互为旋转词
1. 字符串str的前面任意部分挪到后面形成的字符串叫做字符串str的旋转词 $str1 = "2ab1"; $str2 = "ab12"; $ret = is ...
- IOC/DI控制反转与依赖注入
IOC/DI控制反转与依赖注入 IOC和DI表现的效果的是一样的只不过对于作用的对象不同,有了不一样的名字. 先用一个现实的例子来说明IOC/DI表现出来的效果.
- ACM学习历程—HDU5418 Victor and World(动态规划 && 状压)
这个题目由于只有16个城市,很容易想到去用状压来保存状态. p[i][state]表示到i城市经过state状态的城市的最优值(state的二进制位每一位为1表示经过了该城市,否则没经过) 这样p[j ...
- 洛谷【P4883】mzf的考验
浅谈\(splay\):https://www.cnblogs.com/AKMer/p/9979592.html 浅谈\(fhq\)_\(treap\):https://www.cnblogs.com ...
- Vijos1132:求二叉树的先序序列
描述 给出一棵二叉树的中序与后序排列.求出它的先序排列.(约定树结点用不同的大写字母表示,长度≤8). 格式 输入格式 第一行为二叉树的中序序列第二行为二叉树的后序序列 输出格式 一行,为二叉树的先序 ...
- lwip【4】 lwIP配置文件opt.h和lwipopts.h初步分析之一
在这里先说一下这两个配置lwip协议栈文件opt.h和lwipopts.h的关系: opt.h是lwip"出厂"时原装的配置文件,它的作者是瑞士科学院的Adam等 ...
- 第3章 编写ROS程序-3
1.订阅者程序 我们继续使用 turtlesim 作为测试平台,订阅 turtlesim_node发布的/turtle1/pose 话题. 这一话题的消息描述了海龟的位姿 (位置和朝向) .尽管目前你 ...
- L2-014. 列车调度 (DP)
火车站的列车调度铁轨的结构如下图所示. Figure 两端分别是一条入口(Entrance)轨道和一条出口(Exit)轨道,它们之间有N条平行的轨道.每趟列车从入口可以选择任意一条轨道进入,最后从出口 ...
- DOM,date,字符串
ECMAscript Dom doc Bom Browerwindow --窗口. location --地址栏. history --历史. document --文档. statue --任务栏& ...
- ListView Item 里多种点击事件的用法
思路:由于item里需要处理多种点击事件,所以不便于用listview的onItemClickListener, 需要在adapter里进行设置不同点击区域的onclicklistener 但是,有 ...