Centos 7下VMware三台虚拟机Hadoop集群初体验
一、下载并安装Centos 7
传送门:https://www.centos.org/download/
注:下载DVD ISO镜像
这里详解一下VMware安装中的两个过程
网卡配置
是Additional search domains:8.8.4.4也是谷歌提供的免费DNS服务器Ip地址

二、SecureCRT远程操控
ping www.baidu.com 发现slave1,2不通,而master可以ping通,查看master配置,发现两个从机少了一些配置。
安装vim:yum install vim-enhanced
分别修改配置:vim /etc/sysconfig/network 增加"nameserver 192.168.200.2"
再ping 发现问题解决
三台机器分别执行:vim /etc/sysconfig/network 像下图这样进行配置
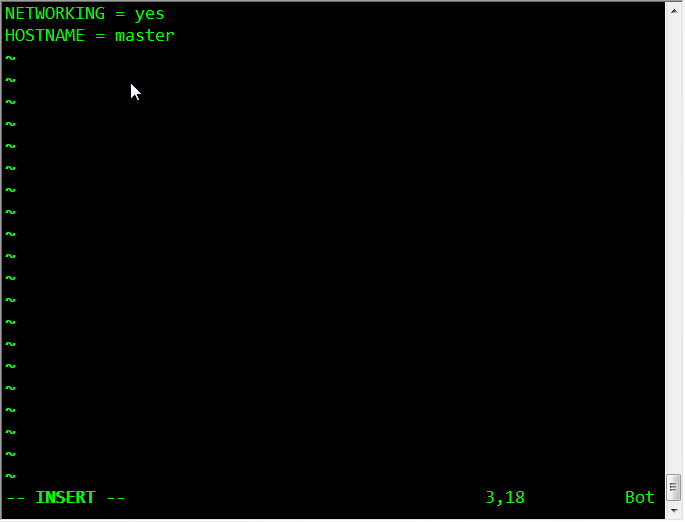
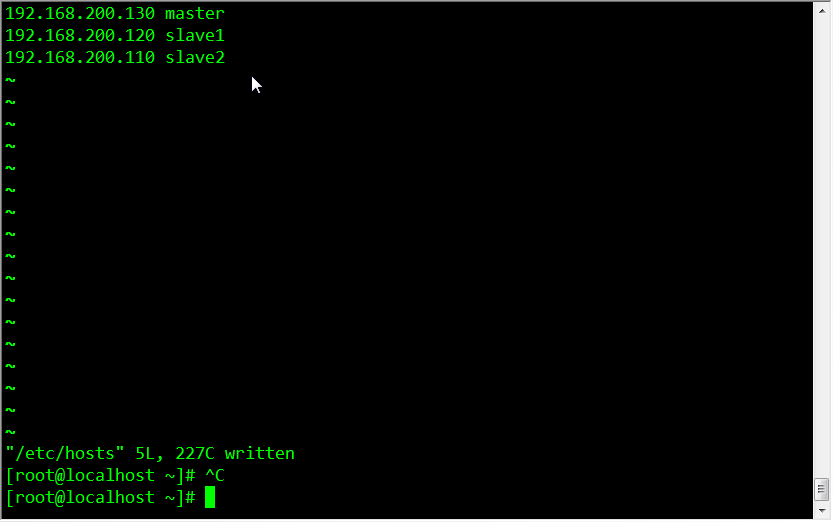
三台机器分别执行:vim /etc/hosts 配置内容相同,增加
192.168.200.130 master
192.168.200.120 slave1
192.168.200.110 slave2
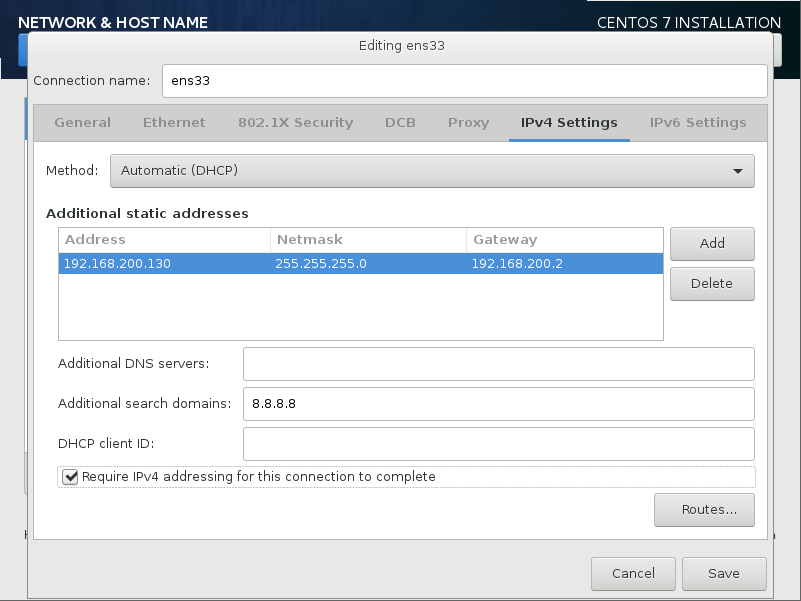
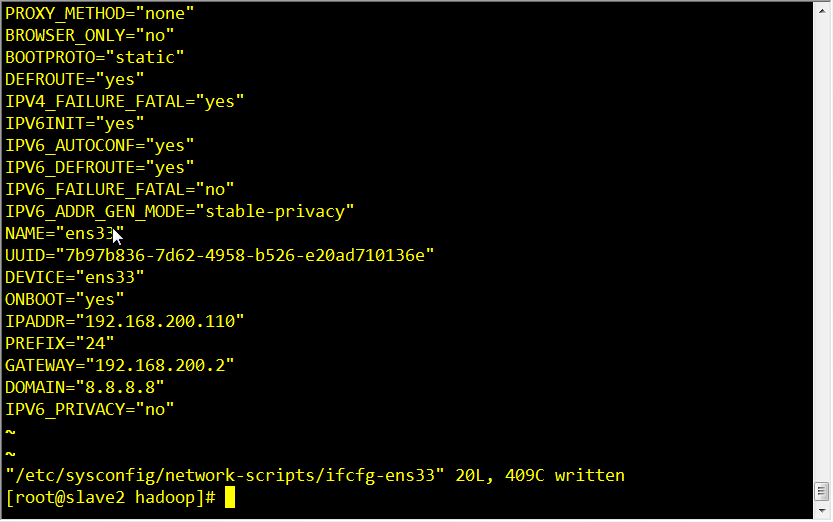
vi /etc/sysconfig/network-scripts/ifcfg-ens33
将dhcp 换位static 静态ip
systemctl restart network.service
之后重启并执行ping验证 ping master/ping slave1/ping slave2
三、下载安装jdk配置环境变量
传送门:https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
注:下载的是 jdk-8u191-linux-x64.tar.gz
在home文件加下新建文件夹hadoop,上传本地jdk文件至该目录中yum install lrzsz rz为上传指令
因为我安装的centos7 为minimal版,若为其他版本例如图形界面版则需卸载本地jdk后再解压配置自己下载的jdk,可参考:https://www.cnblogs.com/sxdcgaq8080/p/7492426.html 前两个步骤。
解压 [root@master hadoop]# tar -zxvf jdk-8u191-linux-x64.tar.gz
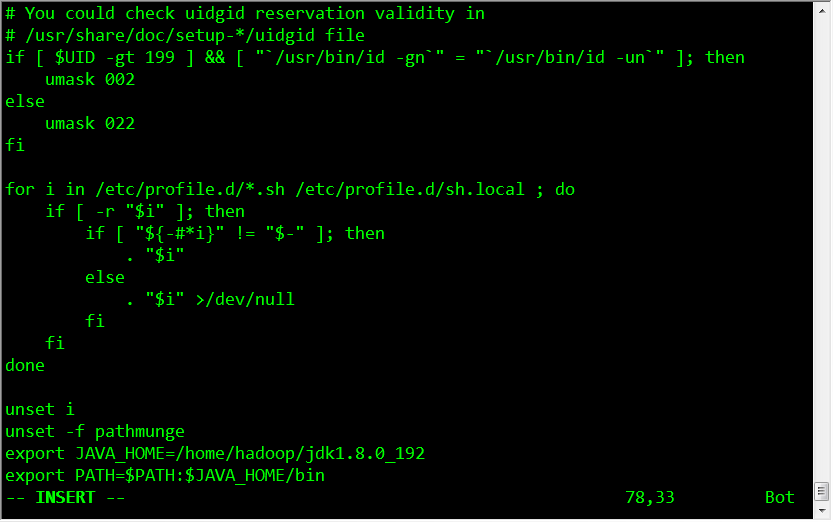
配置java环境变量:vim /etc/profile
export JAVA_HOME=/home/hadoop/jdk1.8.0_191
export PATH=$PATH:$JAVA_HOME/bin
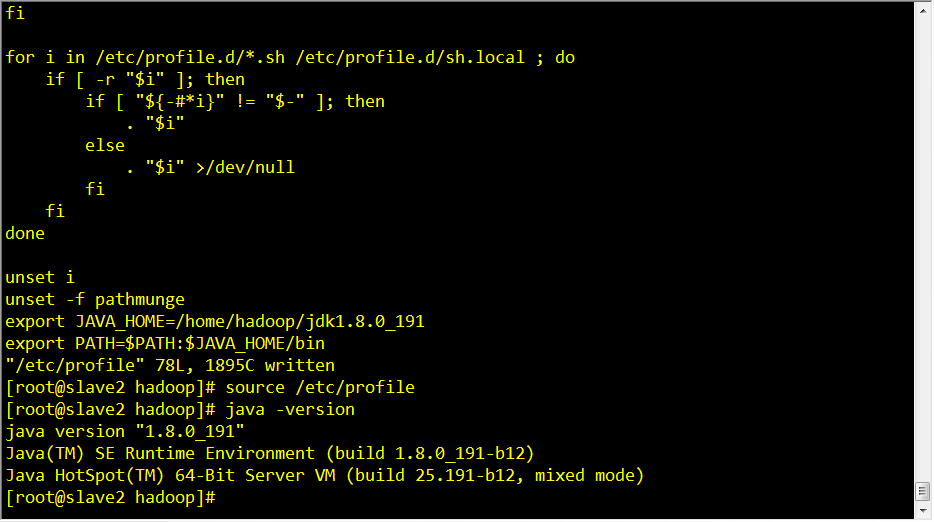
刷新配置:source /etc/profile
验证 java/javac/java -version
四、免秘钥登录操作——以master主机为例
第一步:ssh-keygen -t dsa
第二步:cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
第三步:在~/.ssh目录下执行 scp authorized_keys root@192.168.200.120:~/.ssh/和scp authorized_keys root@192.168.200.120:~/.ssh/分别将授权文件复制给slave1,slave2
同样的三步骤要分别在slave1,slave2上执行,之后查看三台主机的authorized_keys:


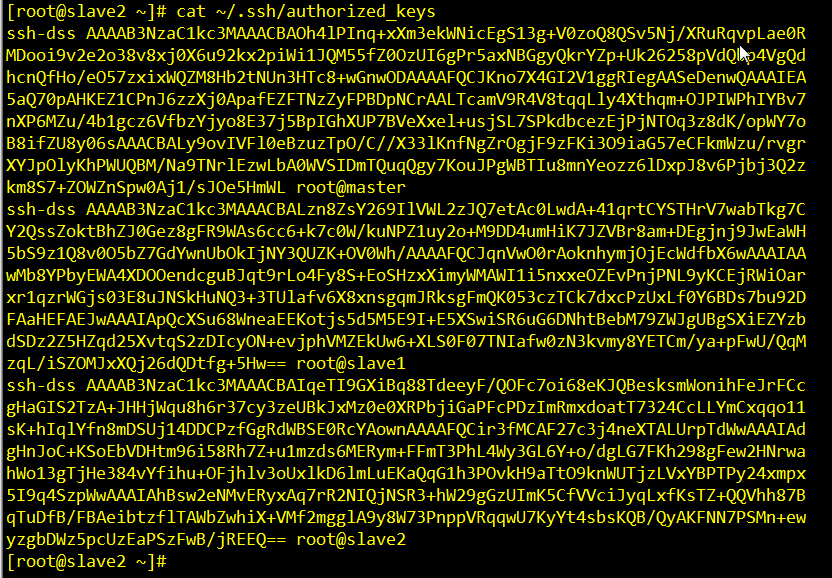
看懂没?
五、下载安装完全分布式hadoop
注:下载二进制binary版本 传送门:http://hadoop.apache.org/releases.html
[root@slave2 hadoop]# tar -axvf hadoop-2.8.5.tar.gz
在/home/hadoop/hadoop-2.8.5/etc/hadoop下面要进行七项配置:
配置1:vim hadoop-env.sh
export JAVA_HOME=/home/hadoop/jdk1.8.0_191
配置2:vim yarn-env.sh
export JAVA_HOME=/home/hadoop/jdk1.8.0_191
配置3:vim slaves

配置4:vim core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-2.8.5/tmp</value>
</property>
配置5:vim hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>master:50090</value>
</property>
配置6:mapred-site.xml是不存在的所以需要复制一份,怎么做呢? mv mapred-site.xml.template mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
配置7:vim yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
六、将配置好的hadoop复制到另外两台机器
scp -r /home/hadoop/hadoop-2.8.5 slave1:/home/hadoop/
scp -r /home/hadoop/hadoop-2.8.5 slave2:/home/hadoop/
七 、配置 bin、sbin路径
vim /etc/profile export JAVA_HOME=/home/hadoop/jdk1.8.0_191 export HADOOP_HOME=/home/hadoop/hadoop-2.8.5 export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
八、重启并测试
hdfs namenode -format
start-dfs.sh

SUCCESS!
目前这篇随笔更像是什么都不懂的外行人按照博客以及自己的实践从头到尾跑下来的成功案例,本人羞愧的说也确实这样。至于其中的众多道理我还不怎么懂,我会在今后不断维护这篇博客,让其更有料,让其完全成为自己肚子里的知识。
[2018.11.27更新 新增了测试wordcount] 如果想测试hadoop 自带wordcount例子,参考这篇 https://blog.csdn.net/hliq5399/article/details/78193113 对应部分就好了,先创建本地输入文件,创建dfs上输出文件,执行就ok
删除自带jdk
rpm -e --nodeps java-1.7.-openjdk-headless-1.7.0.171-2.6.13.2.el7.x86_64
rpm -e --nodeps java-1.7.-openjdk-1.7.0.171-2.6.13.2.el7.x86_64
rpm -e --nodeps java-1.8.-openjdk-headless-1.8.0.161-.b14.el7.x86_64
rpm -e --nodeps java-1.8.-openjdk-1.8.0.161-.b14.el7.x86_64
永久修改主机名
hostnamectl set-hostname centos7
su
hostname
配置host
vim /etc/hosts 关闭防火墙
systemctl status firewalld.service
systemctl stop firewalld.service
systemctl disable firewalld.service
关闭selinux
vim /etc/sysconfig/selinux 配置jdk环境变量
vim /etc/profile
修改完则个文件后一定要执行一条指令使配置生效source /etc/profile
export JAVA_HOME=/opt/modules/jdk1..0_191
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
配置hadoop环境变量
vim /etc/profile
export HADOOP_HOME=/opt/modules/hadoop-2.5.
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
source /etc/profile 进入/opt/modules/hadoop-2.8./etc/hadoop进行一些配置
vim hadoop-env.sh
vim core-site.xml <property>
<name>fs.defaultFS</name>
<value>hdfs://centos7:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/data/tmp</value>
</property> vim hdfs-site.xml <property>
<name>dfs.replication</name>
<value></value>
</property> 格式化hdfs
[root@centos7 hadoop-2.8.]# bin/hdfs namenode -format
查看有无dfs文件夹
ls /opt/data/tmp
ll /opt/data/tmp/dfs/name/current
cat /opt/data/tmp/dfs/name/current/VERSION
执行当前目录下的命令要以./xxx的形式
启动namenode
/opt/modules/hadoop-2.8./sbin
./hadoop-daemon.sh start namenode
启动datanode
./hadoop-daemon.sh start datanode
启动secondarynamenode
./hadoop-daemon.sh start secondarynamenode jps查看启动情况 HDFS上测试创建目录、上传、下载文件 创建目录
在/opt/modules/hadoop-2.8./bin目录下
./hdfs dfs -mkdir /demo
./hdfs dfs -put 待上传文件路径 /demo
./hdfs dfs -cat 待读取文件
./hdfs dfs -get 下载
不存在的复制一份模板 配置mapred-site.xml
cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml <property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
配置yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>centos7</value>
</property>
在/opt/modules/hadoop-2.8.5目录下
启动resourcemanager
sbin/yarn-daemon.sh start resourcemanager
启动nodemanager
sbin/yarn-daemon.sh start nodemanager
jps查看启动情况
查看yarn web页面
http://192.168.200.134:8088/cluster 运行Mapreduce job
创建测试用Input文件bin/hdfs dfs -mkdir -p /wordcountdemo/input
本地/opt/data目录创建一个文件wc.input内容为
hadoop mapreduce hive
hbase spark storm
sqoop hadoop hive
spark hadoop
上传
bin/hdfs dfs -put /opt/data/wc.input /wordcountdemo/input
运行WordCount MapReduce Job [hadoop@bigdata-senior01 hadoop-2.5.]$ bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8..jar wordcount /wordcountdemo/input /wordcountdemo/output
查看输出结果目录
bin/hdfs dfs -ls /wordcountdemo/output
查看输出文件内容
bin/hdfs dfs -cat /wordcountdemo/output/part-r-
我贴上整个过程用到的命令
参考文章:https://www.cnblogs.com/biehongli/p/7640469.html 感谢该作者~
https://blog.csdn.net/hliq5399/article/details/78193113 感谢该作者~
Centos 7下VMware三台虚拟机Hadoop集群初体验的更多相关文章
- 初学Hadoop:利用VMWare+CentOS7搭建Hadoop集群
一.前言 开始学习数据处理相关的知识了,第一步是搭建一个Hadoop集群.搭建一个分布式集群需要多台电脑,在此我选择采用VMWare+CentOS7搭建一个三台虚拟机组成的Hadoop集群. 注:1 ...
- Linux 下 LXD 容器搭建 Hadoop 集群
配置要求 主机内存 4GB . 磁盘 100 GB 以上. HOST 机安装常用 Linux 发行版. Linux Container ( LXD ) 以主机 ubuntu 16.04 为例. 安装 ...
- windows下eclipse远程连接hadoop集群开发mapreduce
转载请注明出处,谢谢 2017-10-22 17:14:09 之前都是用python开发maprduce程序的,今天试了在windows下通过eclipse java开发,在开发前先搭建开发环境.在 ...
- 【转载】 TensorflowOnSpark:1)Standalone集群初体验
原文地址: https://blog.csdn.net/jiangpeng59/article/details/72867368 作者:PJ-Javis 来源:CSDN --------------- ...
- docker从零开始(四)集群初体验,docker-machine swarm
介绍 在第三节中,选择了第二节中编写的应用程序,并通过将其转换为服务来定义它应如何在生产中运行,并生成五个应用实例 在本节中,将此应用程序部署到群集上,在多台计算机上运行它.多容器,多机应用程序通过连 ...
- centos 6.9 x86 安装搭建hadoop集群环境
又来折腾hadoop了 文件准备: centos 6.9 x86 minimal版本 163的源 下软件的时候可能会用到 jdk-8u144-linux-i586.tar.gz ftp工具 putty ...
- 虚拟机hadoop集群搭建
hadoop tar -xvf hadoop-2.7.3.tar.gz mv hadoop-2.7.3 hadoop 在hadoop根目录创建目录 hadoop/hdfs hadoop/hdfs/tm ...
- 【备忘:待完善】nsq集群初体验
本机的一个节点及监控与管理后台 虚拟机中的一个节点 命令: [root@vm-vagrant nsq]# nsqd --lookupd-tcp-address=192.168.23.150:4160 ...
- 一脸懵逼学习基于CentOs的Hadoop集群安装与配置(三台机器跑集群)
1:Hadoop分布式计算平台是由Apache软件基金会开发的一个开源分布式计算平台.以Hadoop分布式文件系统(HDFS)和MapReduce(Google MapReduce的开源实现)为核心的 ...
随机推荐
- js自定义水印
前言:今天在github上看到了一个定义水印的项目,因为获取的星星还蛮多,就多看了几眼,发现该项目简单有趣,心想以后可能会用的到,并且我下载到本地并亲自测试运行了一波.其实该项目最吸引我的是它定义js ...
- Python字符串的格式化,看这一篇就够了
相信很多人在格式化字符串的时候都用"%s" % v的语法,PEP 3101 提出一种更先进的格式化方法 str.format() 并成为 Python 3 的标准用来替换旧的 %s ...
- CentOS安装使用.netcore极简教程(免费提供学习服务器)
本文目标是指引从未使用过Linux的.Neter,如何在CentOS7上安装.Net Core环境,以及部署.Net Core应用. 仅针对CentOS,其它Linux系统类似,命令环节稍加调整: 需 ...
- 如何在优雅地Spring 中实现消息的发送和消费
本文将对rocktmq-spring-boot的设计实现做一个简单的介绍,读者可以通过本文了解将RocketMQ Client端集成为spring-boot-starter框架的开发细节,然后通过一个 ...
- Cookie提要
Cookie的基本概念和设置 Cookie在远程浏览器端存储数据并以此跟踪和识别用户的机制.从实现上说,Cookie是存储在客户端上的小段数据,浏览器(即客户端)通过HTTP协议和服务器端进行Coo ...
- [转]Docker学习之四:使用docker安装mysql
本文转自:https://blog.csdn.net/qq_19348391/article/details/82998391 Docker学习之一:注册Docker Hub账号 Docker学习之二 ...
- PHP开发中bcscale timezone charset的设定
关于php的开发,有几个细节设定,需要知悉下:在项目的init.php 或 index.php 或 api.php 1. bcscale(18); 表示bc函数,默认小数点位数. 没有设定的话,默认为 ...
- [转]Angular引入第三方库
本文转自: https://blog.csdn.net/yuzhiqiang_1993/article/details/71215232 版权声明:本文为博主原创文章,转载请注明地址.如果文中有什么纰 ...
- Docker虚拟机理论
Docker虚拟机架构 ◆ Docker架构 Docker创建的所有虚拟实例共用同一个Linux内核,对硬件占用较小,属于轻量级虚拟机 Docker镜像与容 ...
- [Linux] Nginx 提供静态内容和优化积压队列
1.try_files指令可用于检查指定的文件或目录是否存在; NGINX会进行内部重定向,如果没有,则返回指定的状态代码.例如,要检查对应于请求URI的文件是否存在,请使用try_files指令和$ ...