虚拟机hadoop集群搭建
hadoop
tar -xvf hadoop-2.7.3.tar.gz
mv hadoop-2.7.3 hadoop
在hadoop根目录创建目录
hadoop/hdfs
hadoop/hdfs/tmp
hadoop/hdfs/name
hadoop/hdfs/data
core-site.xml
修改/etc/hadoop中的配置文件
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/hdfs/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://sjck-node01:9000</value>
</property>
</configuration>
hdfs-site.xml
创建hdfs文件系统
dfs.replication维护副本数,默认是3个
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>sjck-node01:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.datanode.registration.ip-hostname-check</name>
<value>false</value>
</property>
</configuration>
mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>sjck-node01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>sjck-node01:19888</value>
</property>
</configuration>
yarn-site.xml
webapp.address是web端口
yarn.resourcemanager.address,port for clients to submit jobs.
arn.resourcemanager.scheduler.address,port for ApplicationMasters to talk to Scheduler to obtain resources.
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
slaves
sjck-node02
sjck-node03
hadoop-env.sh,配置里的变量为集群特有的值
export JAVA_HOME=/usr/local/src/jdk/jdk1.8
export HADOOP_NAMENODE_OPTS="-XX:+UseParallelGC"
yarn-env.sh
export JAVA_HOME=/usr/local/src/jdk/jdk1.8
环境变量
export HADOOP_HOME=/usr/local/hadoop
export PATH="$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH"
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
将目录复制到slaver
scp -r /usr/local/hadoop/ sjck-node02:/usr/local/
scp -r /usr/local/hadoop/ sjck-node03:/usr/local/
启动hadoop的命令都在master上执行,初始化hadoop
hadoop namenode -format
INFO common.Storage: Storage directory /usr/local/hadoop/hdfs/name has been successfully formatted.
master启动
Hadoop守护进程的日志默认写入到 ${HADOOP_HOME}/logs
[root@sjck-node01 sbin]# /usr/local/hadoop/sbin/start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [sjck-node01]
sjck-node01: starting namenode, logging to /usr/local/hadoop/logs/hadoop-root-namenode-sjck-node01.out
sjck-node02: starting datanode, logging to /usr/local/hadoop/logs/hadoop-root-datanode-sjck-node02.out
sjck-node03: starting datanode, logging to /usr/local/hadoop/logs/hadoop-root-datanode-sjck-node03.out
Starting secondary namenodes [sjck-node01]
sjck-node01: starting secondarynamenode, logging to /usr/local/hadoop/logs/hadoop-root-secondarynamenode-sjck-node01.out
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop/logs/yarn-root-resourcemanager-sjck-node01.out
sjck-node02: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-root-nodemanager-sjck-node02.out
sjck-node03: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-root-nodemanager-sjck-node03.out
master关闭
[root@sjck-node01 sbin]# /usr/local/hadoop/sbin/stop-all.sh
This script is Deprecated. Instead use stop-dfs.sh and stop-yarn.sh
Stopping namenodes on [sjck-node01]
sjck-node01: stopping namenode
sjck-node02: stopping datanode
sjck-node03: stopping datanode
Stopping secondary namenodes [sjck-node01]
sjck-node01: stopping secondarynamenode
stopping yarn daemons
stopping resourcemanager
sjck-node02: stopping nodemanager
sjck-node03: stopping nodemanager
no proxyserver to stop
查看集群状态

Namenode
文件系统的管理节点,维护文件系统的目录结构元数据,还有文件与block对应关系
master是NameNode,也是JobTracker
DataNode
提供真实文件数据,slaver是DataNode,也是TaskTracker
查看master进程状态
[root@sjck-node01 hadoop]# jps
4404 SecondaryNameNode
4215 NameNode
4808 Jps
4555 ResourceManager
查看slaver进程状态
[root@sjck-node02 hadoop]# jps
2752 DataNode
4995 Jps
2839 NodeManager
[root@sjck-node03 hadoop]# jps
3076 DataNode
3163 NodeManager
3260 Jps
查看防火墙状态
service iptables status
关闭防火墙,开机不启动
service iptables stop
chkconfig --del iptables
查看集群状态
http://172.16.92.128:18088/cluster
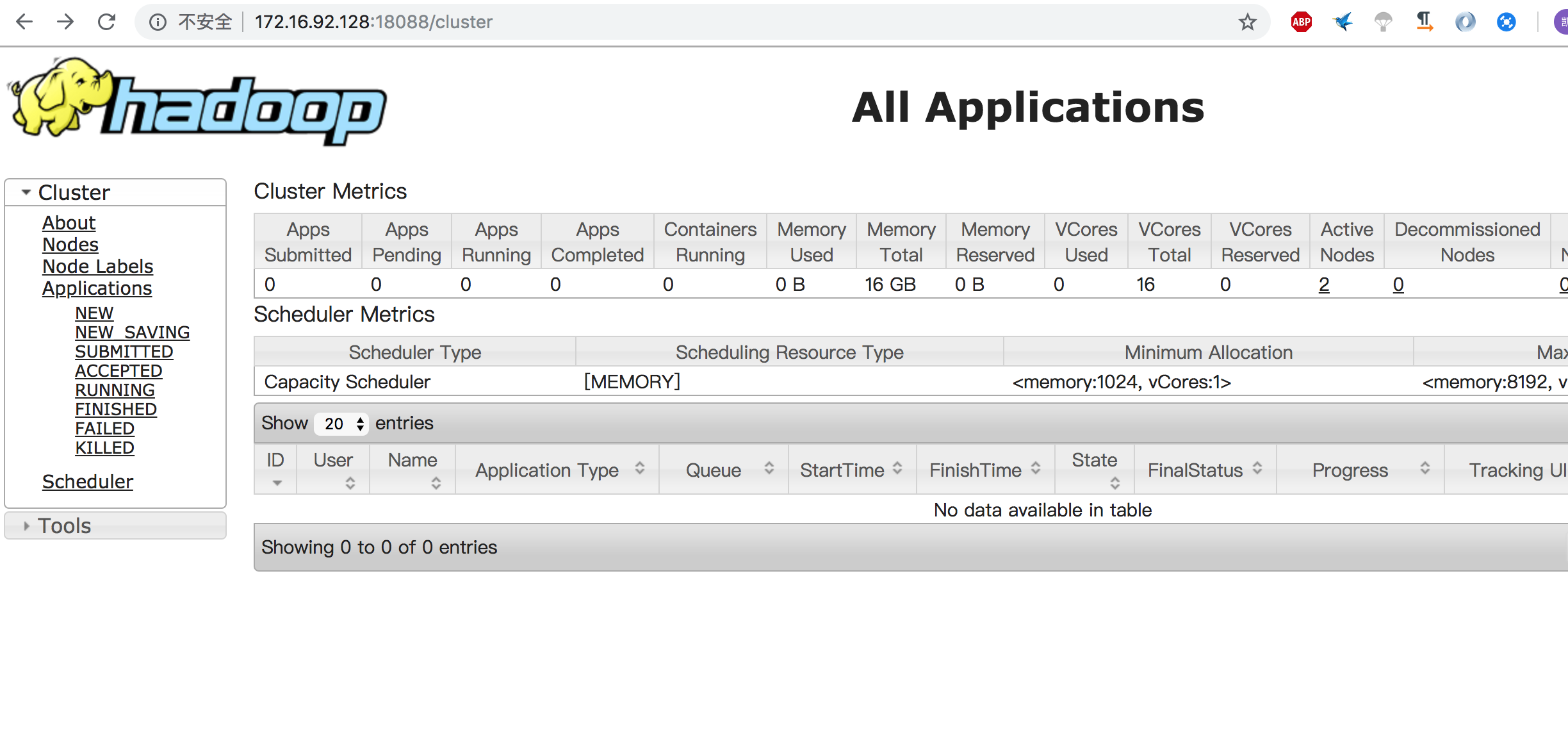
执行测试任务
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar pi 10 10
19/03/20 20:42:30 INFO mapreduce.Job: map 0% reduce 0%
19/03/20 20:42:51 INFO mapreduce.Job: map 20% reduce 0%
19/03/20 20:43:05 INFO mapreduce.Job: map 20% reduce 7%
19/03/20 20:45:43 INFO mapreduce.Job: map 40% reduce 7%
19/03/20 20:45:44 INFO mapreduce.Job: map 50% reduce 7%
19/03/20 20:45:47 INFO mapreduce.Job: map 60% reduce 7%
19/03/20 20:45:48 INFO mapreduce.Job: map 100% reduce 7%
19/03/20 20:45:49 INFO mapreduce.Job: map 100% reduce 33%
19/03/20 20:45:50 INFO mapreduce.Job: map 100% reduce 100%
Job Finished in 218.298 seconds
配置参数详情
[root@sjck-node01 hadoop]# jps
4404 SecondaryNameNode
4215 NameNode
4808 Jps
4555 ResourceManager
虚拟机hadoop集群搭建的更多相关文章
- Hadoop集群搭建(完全分布式版本) VMWARE虚拟机
Hadoop集群搭建(完全分布式版本) VMWARE虚拟机 一.准备工作 三台虚拟机:master.node1.node2 时间同步 ntpdate ntp.aliyun.com 调整时区 cp /u ...
- Hadoop集群搭建安装过程(一)(图文详解---尽情点击!!!)
Hadoop集群搭建(一)(上篇中讲到了Linux虚拟机的安装) 一.安装所需插件(以hadoop2.6.4为例,如果需要可以到官方网站进行下载:http://hadoop.apache.org) h ...
- Linux环境下Hadoop集群搭建
Linux环境下Hadoop集群搭建 前言: 最近来到了武汉大学,在这里开始了我的研究生生涯.昨天通过学长们的耐心培训,了解了Hadoop,Hdfs,Hive,Hbase,MangoDB等等相关的知识 ...
- Hadoop(二) HADOOP集群搭建
一.HADOOP集群搭建 1.集群简介 HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起 HDFS集群: 负责海量数据的存储,集群中的角色主要有 Na ...
- Hadoop学习之路(四)Hadoop集群搭建和简单应用
概念了解 主从结构:在一个集群中,会有部分节点充当主服务器的角色,其他服务器都是从服务器的角色,当前这种架构模式叫做主从结构. 主从结构分类: 1.一主多从 2.多主多从 Hadoop中的HDFS和Y ...
- 1.Hadoop集群搭建之Linux主机环境准备
Hadoop集群搭建之Linux主机环境 创建虚拟机包含1个主节点master,2个从节点slave1,slave2 虚拟机网络连接模式为host-only(非虚拟机环境可跳过) 集群规划如下表: 主 ...
- 三节点Hadoop集群搭建
1. 基础环境搭建 新建3个CentOS6.5操作系统的虚拟机,命名(可自定)为masternode.slavenode1和slavenode2.该过程参考上一篇博文CentOS6.5安装配置详解 2 ...
- 大数据初级笔记二:Hadoop入门之Hadoop集群搭建
Hadoop集群搭建 把环境全部准备好,包括编程环境. JDK安装 版本要求: 强烈建议使用64位的JDK版本,这样的优势在于JVM的能够访问到的最大内存就不受限制,基于后期可能会学习到Spark技术 ...
- 大数据学习——HADOOP集群搭建
4.1 HADOOP集群搭建 4.1.1集群简介 HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起 HDFS集群: 负责海量数据的存储,集群中的角色主 ...
随机推荐
- 一、Kafka初认识
一.kafka使用背景 1.Kafka使用背景 在我们大量使用分布式数据库.分布式计算集群的时候,是否会遇到这样的一些问题: 我们想分析下用户行为(pageviews),以便我们设计出更好的广告位 我 ...
- Java并发编程原理与实战四:线程如何中断
如果你使用过杀毒软件,可能会发现全盘杀毒太耗时间了,这时你如果点击取消杀毒按钮,那么此时你正在中断一个运行的线程. java为我们提供了一种调用interrupt()方法来请求终止线程的方法,下面我们 ...
- C语言的内存对齐
从一个例子开始 象下面这样定义的结构体占几个字节? typedef struct{ char a; int i; } Sample; char占1个字节,int占4个字节,答案是5个字节? 错了.如果 ...
- 20165227朱越 预备作业3 Linux安装及学习
预备作业3 Linux安装及学习 Linux的安装 虚拟机的安装远没有想象中的那样容易,下载还没有出现什么问题,当我安装的时候,第一个问题出现在创建虚拟机时选择安装的虚拟机版本和类型的时候的错误 当时 ...
- linux 进程内存解析【转】
转自:http://blog.csdn.net/lile269/article/details/6460807 之前我所了解的linux下进程的地址空间的布局的知识,是从APUE第2版的P430得来的 ...
- 新浪的wap网站,发现原来我们的head存在着这样的差异
前一段时间一直被wap网站的自适应困惑…… 仔细研究了一下新浪的wap网站,发现原来我们的head存在着这样的差异…… <%@page contentType="text/html;c ...
- 理解 Linux 的硬链接与软链接(待研究)
从 inode 了解 Linux 文件系统 硬链接与软链接是 Linux 文件系统中的一个重要概念,其涉及文件系统中的索引节点 (index node 又称 inode),而索引节点对象是 Linux ...
- 手淘移动适配方案flexible.js兼容bug处理
什么是flexible.js 移动端自适应方案 https://www.jianshu.com/p/04efb4a1d2f8 什么是rem 这个单位代表根元素的 font-size 大小(例如 元素的 ...
- plsql developer配置
一:今天plsql developer连接 出问题了 ,Oracleclient没正确安装 0.连接vpn 1.环境变量:TNS_ADMIN = D:\worksoftware\oracleClien ...
- TDictionary 与 TObjectDictionary
TDictionary 与 TObjectDictionary 的区别是 : TObjectDictionary 可以做到 free的时候 里面的对象 一并free,从而不会出现内存 泄露. 用途: ...