pythonのscrapy抓取网站数据
(1)安装Scrapy环境
步骤请参考:https://blog.csdn.net/c406495762/article/details/60156205
需要注意的是,安装的时候需要根据自己的python的版本进行安装。
(2)创建Scrapy项目
通过命令创建:
scrapy startproject tutorial
在任意文件夹运行都可以,如果提示权限问题,可以加sudo运行。这个命令将会创建一个名字为tutorial的文件夹,文件夹结构如下:
|____scrapy.cfg # Scrapy部署时的配置文件
|____tutorial # 项目的模块,引入的时候需要从这里引入
| |______init__.py
| |______pycache__
| |____items.py # Items的定义,定义爬取的数据结构
| |____middlewares.py # Middlewares的定义,定义爬取时的中间件
| |____pipelines.py # Pipelines的定义,定义数据管道
| |____settings.py # 配置文件
| |____spiders # 放置Spiders的文件夹
| | |______init__.py
| | |______pycache__
Spider是由你来定义的Class,Scrapy用它来从网页里抓取内容,并将抓取的结果解析。不过这个Class必须要继承Scrapy提供的Spider类scrapy.Spider,并且你还要定义Spider的名称和起始请求以及怎样处理爬取后的结果的方法。
创建一个Spider也可以用命令生成,比如要生成Quotes这个Spider,可以执行命令。
scrapy genspider 爬虫名称 "作用域(eg:baidu.com)"
首先进入到刚才创建的tutorial文件夹,然后执行genspider这个命令,第一个参数是Spider的名称,第二个参数是网站域名。执行完毕之后,你会发现在spiders文件夹中多了一个quotes.py,这就是你刚刚创建的Spider,内容如下:
# -*- coding: utf-8 -*-
import scrapy class QuotesSpider(scrapy.Spider):
name = "quotes"
allowed_domains = ["quotes.toscrape.com"]
start_urls = ['http://quotes.toscrape.com/'] def parse(self, response):
pass
可以看到有三个属性,name,allowed_domains,start_urls,另外还有一个方法parse
name,每个项目里名字是唯一的,用来区分不同的Spider。
allowed_domains允许爬取的域名,如果初始或后续的请求链接不是这个域名下的,就会被过滤掉。
start_urls,包含了Spider在启动时爬取的url列表,初始请求是由它来定义的。
parse,是Spider的一个方法,默认情况下,被调用时start_urls里面的链接构成的请求完成下载后,返回的response就会作为唯一的参数传递给这个函数,该方法负责解析返回的response,提取数据或者进一步生成要处理的请求。
创建Item
Item是保存爬取数据的容器,它的使用方法和字典类似,虽然你可以用字典来表示,不过Item相比字典多了额外的保护机制,可以避免拼写错误或者为定义字段错误。
创建Item需要继承scrapy.Item类,并且定义类型为scrapy.Field的类属性来定义一个Item。观察目标网站,我们可以获取到到内容有text, author, tags
所以可以定义如下的Item,修改items.py如下:
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html import scrapy class QuoteItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
'''
item 时报错爬取数据的容器,它的使用方法和字典类似,虽然你可以用字典来表示,
不过Item相比字典多了额外的保护机制,可以避免拼写错误或者未定义字段错误。
创建item需要继承Scrapy.Item类,并且定义类型为scrapy.Field的类属性来定义一
个Item。观察目标网站,我们可以获取到内容有text、author、tags
'''
text = scrapy.Field()
author = scrapy.Field()
tags = scrapy.Field()
定义了三个Field,接下来爬取时我们会使用它。
解析Response
在上文中说明了parse方法的参数resposne是start_urls里面的链接爬取后的结果。所以在parse方法中,我们可以直接对response包含的内容进行解析,比如看看请求结果的网页源代码,或者进一步分析源代码里面包含什么,或者找出结果中的链接进一步得到下一个请求。
观察网站,我们可以看到网页中既有我们想要的结果,又有下一页的链接,所以两部分我们都要进行处理。
首先看一下网页结构,每一页都有多个class为quote的区块,每个区块内都包含text,author,tags,所以第一部需要找出所有的quote,然后对每一个quote进一步提取其中的内容。
提取的方式可以选用CSS选择器或XPath选择器,在这里我们使用CSS选择器进行选择,parse方法改写如下:
def parse(self, response):
quotes = response.css('.quote')
for quote in quotes:
text = quote.css('.text::text').extract_first()
author = quote.css('.author::text').extract_first()
tags = quote.css('.tags .tag::text').extract()
在这里使用了CSS选择器的语法,首先利用选择器选取所有的quote赋值为quotes变量。
然后利用for循环对每个quote遍历,解析每个quote的内容。
对text来说,观察到它的class为text,所以可以用.text来选取,这个结果实际上是整个带有标签的元素,要获取它的内容,可以加::text来得到。这时的结果是大小为1的数组,所以还需要用extract_first方法来获取第一个元素,而对于tags来说,由于我们要获取所有的标签,所以用extract方法获取即可。
<div class="quote" itemscope="" itemtype="http://schema.org/CreativeWork">
<span class="text" itemprop="text">“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”</span>
<span>by <small class="author" itemprop="author">Albert Einstein</small>
<a href="/author/Albert-Einstein">(about)</a>
</span>
<div class="tags">
Tags:
<meta class="keywords" itemprop="keywords" content="change,deep-thoughts,thinking,world">
<a class="tag" href="/tag/change/page/1/">change</a>
<a class="tag" href="/tag/deep-thoughts/page/1/">deep-thoughts</a>
<a class="tag" href="/tag/thinking/page/1/">thinking</a>
<a class="tag" href="/tag/world/page/1/">world</a>
</div>
</div>
使用Item
刚才定义了Item,接下来就要轮到使用它了,你可以把它理解为一个字典,不过在声明的时候需要实例化。然后依次对刚才解析的结果赋值,返回即可。
接下来QuotesSpider改写如下:
# -*- coding: utf-8 -*-
import scrapy
from tutorial.items import QuoteItem class QuotesSpider(scrapy.Spider):
# 爬虫名称
name = 'quotes' # 允许爬虫爬取的域名,如果初始或者后续请求链接不是这个域名下,就会被过滤
allowed_domains = ['quotes.toscrape.com'] # 包含了Spider在启动时爬取的url列表,初始请求是由它来定义的
start_urls = ['http://quotes.toscrape.com/'] # 时Spider的一个方法,默认情况下,被调用时start_urls里面的
# 链接构成的请求完成下载后,返回的response就会被作为唯一的
# 参数传递给这个函数,该方法负责解析返回的response,提取数
# 据或者进一步生成要处理的请求
def parse(self, response):
quotes = response.css(".quote")
for quote in quotes:
item = QuoteItem()
item['text'] = quote.css(".text::text").extract_first()
item['author'] = quote.css(".author::text").extract_first()
item['tags'] = quote.css(".tags .tag::text").extract()
yield item
next = response.css('.page .next a::attr("href")').extract_first()
url = response.urljoin(next)
yield scrapy.Request(url = url,callback = self.parse)
如此一来,首页的所有内容就解析出来了,并赋值成了一个个QuoteItem。
后续Request
如上的操作实现了从初始页面抓取内容,不过下一页的内容怎样继续抓取?这就需要我们从该页面中找到信息来生成下一个请求,然后下一个请求的页面里找到信息再构造下一个请求,这样循环往复迭代,从而实现整站的爬取。
观察到刚才的页面拉到最下方,有一个Next按钮,查看一下源代码,可以发现它的链接是/page/2/,实际上全链接就是http://quotes.toscrape.com/page/2,通过这个链接我们就可以构造下一个请求。
构造请求时需要用到scrapy.Request,在这里我们传递两个参数,url和callback。
url,请求链接
callback,回调函数,当这个请求完成之后,获取到response,会将response作为参数传递给这个回调函数,回调函数进行解析或生成下一个请求,如上文的parse方法。
在这里,由于parse就是用来解析text,author,tags的方法,而下一页的结构和刚才已经解析的页面结构是一样的,所以我们还可以再次使用parse方法来做页面解析。
好,接下来我们要做的就是利用选择器得到下一页链接并生成请求,在parse方法后追加下面的代码。
next = response.css('.pager .next a::attr(href)').extract_first()
url = response.urljoin(next)
yield scrapy.Request(url=url, callback=self.parse)
第一句代码是通过CSS选择器获取下一个页面的链接,需要获取<a>超链接中的href属性,在这里用到了::attr(href)操作,通过::attr加属性名称我们可以获取属性的值。然后再调用extract_first方法获取内容。
第二句是调用了urljoin方法,它可以将相对url构造成一个绝对的url,例如获取到的下一页的地址是/page/2,通过urljoin方法处理后得到的结果就是http://quotes.toscrape.com/page/2/
第三句是通过url和callback构造了一个新的请求,回调函数callback依然使用的parse方法。这样在完成这个请求后,response会重新经过parse方法处理,处理之后,得到第二页的解析结果,然后生成第二页的下一页,也就是第三页的请求。这样就进入了一个循环,直到最后一页。
通过几行代码,我们就轻松地实现了一个抓取循环,将每个页面的结果抓取下来了。
现在改写之后整个Spider类是这样的:
# -*- coding: utf-8 -*-
import scrapy
from tutorial.items import QuoteItem class QuotesSpider(scrapy.Spider):
# 爬虫名称
name = 'quotes' # 允许爬虫爬取的域名,如果初始或者后续请求链接不是这个域名下,就会被过滤
allowed_domains = ['quotes.toscrape.com'] # 包含了Spider在启动时爬取的url列表,初始请求是由它来定义的
start_urls = ['http://quotes.toscrape.com/'] # 时Spider的一个方法,默认情况下,被调用时start_urls里面的
# 链接构成的请求完成下载后,返回的response就会被作为唯一的
# 参数传递给这个函数,该方法负责解析返回的response,提取数
# 据或者进一步生成要处理的请求
def parse(self, response):
quotes = response.css(".quote")
for quote in quotes:
item = QuoteItem()
item['text'] = quote.css(".text::text").extract_first()
item['author'] = quote.css(".author::text").extract_first()
item['tags'] = quote.css(".tags .tag::text").extract()
yield item
next = response.css('.page .next a::attr("href")').extract_first()
url = response.urljoin(next)
yield scrapy.Request(url = url,callback = self.parse)
接下来让我们试着运行一下看看结果,进入目录,运行如下命令:
scrapy crawl quotes
正常情况下这里就会得到如图效果(部分):
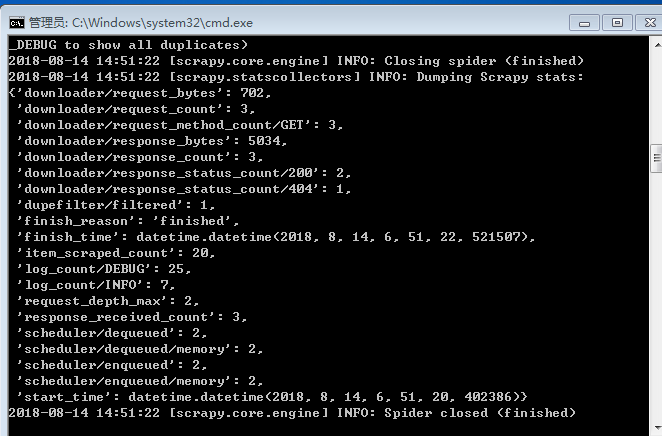
但是也有可能会遇到这种情况:
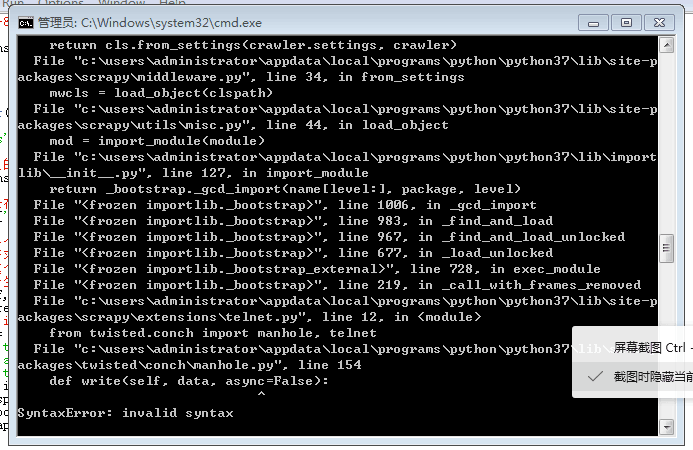
再回过头看看我们上边输出的正确结果,这个时候的解决办法是通过提示报错的地址找到manhole.py,然后将该文件中的所有async改为其它的名字比如async1,即可解决相应的问题。
首先Scrapy输出了当前的版本号,启动的项目。其次输出了当前在settings.py中的一些重写后的配置。然后输出了当前所应用的middlewares和pipelines,middlewares是默认启用的,如果要修改,我们可以在settings.py中修改,pipelines默认是空,同样也可以在settings.py中配置,后面会进行讲解。
再接下来就是输出各个页面的抓取结果了,可以看到它一边解析,一边翻页,直至将所有内容抓取完毕,然后终止。
在最后Scrapy输出了整个抓取过程的统计信息,如请求的字节数,请求次数,响应次数,完成原因等等。
这样整个Scrapy程序就成功运行完毕了。
可以发现我们通过非常简单的一些代码就完成了一个网站内容的爬取,相比之前自己一点点写程序是不是简洁太多了?
保存到文件
刚才运行完Scrapy后,我们只在控制台看到了输出结果,如果想将结果保存该怎么办呢?
比如最简单的形式,将结果保存成Json文件。
要完成这个其实不需要你写任何额外的代码,Scrapy提供了Feed Exports可以轻松地将抓取结果输出,例如我们想将上面的结果保存成Json文件,可以执行如下命令:
scrapy crawl quotes -o quotes.json
运行后发现项目内就会多了一个quotes.json文件,里面包含的就是刚才抓取的所有内容,是一个Json格式,多个项目由中括号包围,是一个合法的Json格式。
另外你还可以每一个Item一个Json,最后的结果没有中括号包围,一行对应一个Item,命令如下:
scrapy crawl quotes -o quotes.jl
或者
scrapy crawl quotes -o quotes.jsonlines
另外还支持很多格式输出,例如csv,xml,pickle,marshal等等,还支持ftp,s3等远程输出,另外还可以通过自定义ItemExporter来实现其他的输出。
例如如下命令分别对应输出为csv,xml,pickle,marshal,格式以及ftp远程输出:
scrapy crawl quotes -o quotes.csv
scrapy crawl quotes -o quotes.xml
scrapy crawl quotes -o quotes.pickle
scrapy crawl quotes -o quotes.marshal
scrapy crawl quotes -o ftp://user:pass@ftp.example.com/path/to/quotes.csv
其中ftp输出需要你正确配置好你的用户名,密码,地址,输出路径,否则会报错。
通过Scrapy提供的Feed Exports我们可以轻松地输出抓取结果到文件,对于一些小型项目这应该是足够了,不过如果想要更复杂的输出,如输出到数据库等等,你可以使用Item Pileline更方便地实现。
pythonのscrapy抓取网站数据的更多相关文章
- 抓取网站数据不再是难事了,Fizzler(So Easy)全能搞定
首先从标题说起,为啥说抓取网站数据不再难(其实抓取网站数据有一定难度),SO EASY!!!使用Fizzler全搞定,我相信大多数人或公司应该都有抓取别人网站数据的经历,比如说我们博客园每次发表完文章 ...
- python scrapy 抓取脚本之家文章(scrapy 入门使用简介)
老早之前就听说过python的scrapy.这是一个分布式爬虫的框架,可以让你轻松写出高性能的分布式异步爬虫.使用框架的最大好处当然就是不同重复造轮子了,因为有很多东西框架当中都有了,直接拿过来使用就 ...
- scrapy 抓取拉勾网数据
其实很简单,却因为一些小问题,折腾不少时间,简要记录一下,以备后需. >> scrapy startproject lagou >> cd lagou >> scr ...
- php外挂python脚本抓取ajax数据
之前我写过一遍php外挂python脚本处理视频的文章.今天和大家分享下php外挂python实现输入关键字搜索的脚本 首先我们先来分析一波网站: http://www.dzdpw.com/s.php ...
- Python 逆向抓取 APP 数据
今天继续给大伙分享一下 Python 爬虫的教程,这次主要涉及到的是关于某 APP 的逆向分析并抓取数据,关于 APP 的反爬会麻烦一些,比如 Android 端的代码写完一般会进行打包并混淆加密加固 ...
- C# 抓取网站数据
项目主管说这是项目中的一个亮点(无语...), 类似于爬虫一类的东西,模拟登陆后台系统,获取需要的数据.然后就开始研究这个. 之前有一些数据抓取的经验,抓取流程无非:设置参数->服务端发送请求- ...
- python 多线程抓取动态数据
利用多线程动态抓取数据,网上也有不少教程,但发现过于繁杂,就不能精简再精简?! 不多解释,直接上代码,基本上还是很好懂的. #!/usr/bin/env python # coding=utf-8 i ...
- 用curl抓取网站数据,仿造IP、防屏蔽终极强悍解决方式
最近在做一些抓取其它网站数据的工作,当然别人不会乖乖免费给你抓数据的,有各种防抓取的方法.不过道高一尺,魔高一丈,通过研究都是有漏洞可以钻的.下面的例子都是用PHP写的,不会用PHP来curl的孩纸先 ...
- PHP用curl抓取网站数据,仿造IP、伪造来源等,防屏蔽解决方案教程
1.伪造客户端IP地址,伪造访问referer:(一般情况下这就可以访问到数据了) curl_setopt($curl, CURLOPT_HTTPHEADER, ['X-FORWARDED-FOR:1 ...
随机推荐
- (贪心 线段不相交问题)codeVs 1214 线段覆盖
题目描述 Description 给定x轴上的N(0<N<100)条线段,每个线段由它的二个端点a_I和b_I确定,I=1,2,……N.这些坐标都是区间(-999,999)的整数.有些线段 ...
- apache安装及相应配置
给公司装过环境,自己也装过自己的服务器环境.但是每次都是现谷歌,毕竟每个人遇到的问题都不一样,还是记录下,以防忘记 一.安装 Centos7默认已经安装httpd服务,只是没有启动.如果你需要全新安装 ...
- Emgu.CV 播放视频-本地文件/RTSP流
using Emgu.CV; using System; using System.Drawing; using System.Threading; using System.Windows.Form ...
- MegaCli命令使用详解
一.MegaCli命令介绍 MegaCli是一款管理维护硬件RAID软件,可以用来查看raid信息等MegaCli 的Media Error Count: 0 Other Error Count: 0 ...
- day-03(js)
回顾: css: 层叠样式表 作用: 渲染页面 提供工作效率,将html和样式分离 和html的整合 方式1:内联样式表 通过标签的style属性 <xxx style="...&qu ...
- 2017-12-14python全栈9期第一天第二节之初始计算机系统
CPU:相当于人的大脑.用于计算 内存:储存数据.4G.8G.32G....成本高.断电即消失 硬盘:固态.机械.长久保存数据+文件 操作系统: 应用程序:
- maven_eclipse配置maven
1.eclipse配置3.3.9版本的maven 2.修改仓库位置
- tedu训练营day04
1.猜拳:import randomlist = ['石头','剪刀','布']y = input('''(0) 石头(1) 剪刀(2) 布请出拳(0/1/2):******************* ...
- Ext.net NumberField要设置MinValue,MaxValue
<Items> <ext:NumberField ID="NumberField1" runat="server" FieldLabel=&q ...
- 关于HTTP的笔记
网上看了一篇关于HTTP的博客,觉得还不错,这里就记下来了. 参考:https://www.cnblogs.com/guguli/p/4758937.html 一.主要特点 1.支持客户/服务器模式2 ...