rest-framework解析器,url控制,分页,响应器,渲染器,版本控制
解析器
1.json解析器
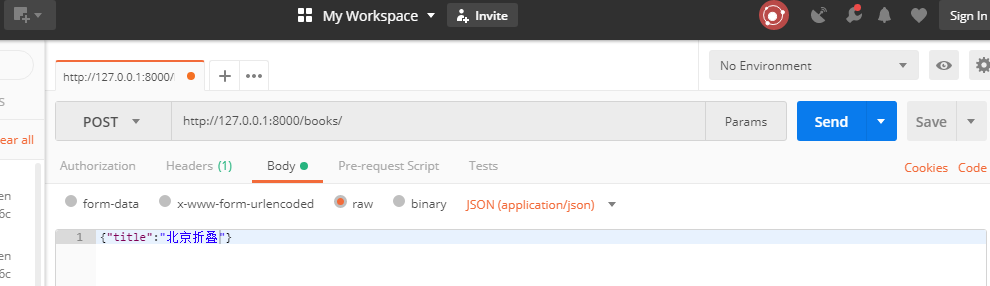
发一个json格式的post请求。
后台打印:
request_data---> {'title': '北京折叠'}
request.POST---> <QueryDict: {}>
2.urlencode解析器

request_data---> <QueryDict: {'title': ['北京'], 'price': ['']}>
request.POST---> <QueryDict: {'title': ['北京'], 'price': ['']}>
rest-framework默认支持的有3种解析器,json,form,文件上传。而Django原生只支持form的解析,不支持json的解析。
源码:
JSON解析器类:
class JSONParser(BaseParser):
"""
Parses JSON-serialized data.
"""
media_type = 'application/json'
renderer_class = renderers.JSONRenderer
strict = api_settings.STRICT_JSON def parse(self, stream, media_type=None, parser_context=None):
"""
Parses the incoming bytestream as JSON and returns the resulting data.
"""
parser_context = parser_context or {}
encoding = parser_context.get('encoding', settings.DEFAULT_CHARSET) try:
decoded_stream = codecs.getreader(encoding)(stream)
parse_constant = json.strict_constant if self.strict else None
return json.load(decoded_stream, parse_constant=parse_constant)
except ValueError as exc:
raise ParseError('JSON parse error - %s' % six.text_type(exc))
form解析器类:
class FormParser(BaseParser):
"""
Parser for form data.
"""
media_type = 'application/x-www-form-urlencoded' def parse(self, stream, media_type=None, parser_context=None):
"""
Parses the incoming bytestream as a URL encoded form,
and returns the resulting QueryDict.
"""
parser_context = parser_context or {}
encoding = parser_context.get('encoding', settings.DEFAULT_CHARSET)
data = QueryDict(stream.read(), encoding=encoding)
return data
文件上传类:
class MultiPartParser(BaseParser):
"""
Parser for multipart form data, which may include file data.
"""
media_type = 'multipart/form-data' def parse(self, stream, media_type=None, parser_context=None):
"""
Parses the incoming bytestream as a multipart encoded form,
and returns a DataAndFiles object. `.data` will be a `QueryDict` containing all the form parameters.
`.files` will be a `QueryDict` containing all the form files.
"""
parser_context = parser_context or {}
request = parser_context['request']
encoding = parser_context.get('encoding', settings.DEFAULT_CHARSET)
meta = request.META.copy()
meta['CONTENT_TYPE'] = media_type
upload_handlers = request.upload_handlers try:
parser = DjangoMultiPartParser(meta, stream, upload_handlers, encoding)
data, files = parser.parse()
return DataAndFiles(data, files)
except MultiPartParserError as exc:
raise ParseError('Multipart form parse error - %s' % six.text_type(exc))
URL控制
1.因为每次url都需要写下面的2条线,导致代码冗余。
# url(r'authors/$', views.AuthorModelView.as_view({"get":"list","post":"create"}),name="authors"),
# url(r'authors/(?P<pk>\d+)/$', views.AuthorModelView.as_view({"get":"retrieve","put":"update","delete":"destroy"}),name="authordetail"),
2.使用rest-framework提供的:
from django.conf.urls import url,include
from app01 import views from rest_framework import routers
routers=routers.DefaultRouter()
routers.register("authors",views.AuthorModelView)
url中需要加这一句即可:
url(r'',include(routers.urls)),
以后每一个表,注册一下即可,前面的是url的前缀,后面是对应的视图类。
测试结果以及自动生成的url路径如下图:(可以直接.json取到结果)

生成的URL:

分页
1.基本分页器:
from rest_framework.pagination import PageNumberPagination
#自己写一个继承分页器,然后自己设置
class MyPageNumberPagination(PageNumberPagination):
page_size = 2 #每个页面显示多少数据
page_query_param = "page" #?page 的名字,默认"page",可以改其他
page_size_query_param = "size" #临时的一个分页数目,虽然最多2条,但是可以临时扩大每页显示的数据数量
max_page_size = 3 #虽然临时的可以调,但不能无限大,做一个最大临时限制。 class BookView(APIView):
# authentication_classes = [TokenAuth]
def get(self,request):
print(request.user) #token_obj.user.name
print(request.auth) #token_obj.token
book_list=Book.objects.all()
#加入分页
pnp=MyPageNumberPagination() #分页器实例对象
books_page=pnp.paginate_queryset(book_list,request,self) #传入数据 bs2=BookModelSerializers(books_page,many=True,context={'request': request}) #将分好的数据进行序列化并展示
return Response(bs2.data)
2.偏移分页器(很少用到):
from rest_framework.pagination import LimitOffsetPagination
和上面一模一样,只是加了一个offset的偏移参数。
3.对于高度封装的视图类怎么使用分页器:
from rest_framework import viewsets
class AuthorModelView(viewsets.ModelViewSet):
queryset=Author.objects.all()
serializer_class=AuthorModelSerializers
pagination_class = MyPageNumberPagination
因为这个作者的视图进行了高度的封装,显然重写list方法并且进行分页展示非常的麻烦,那么使用一个
pagination_class =你自己继承分页器并且定制好的分页器类即可完成分页。
4.全局配置分页数目:
settings中进行配置。
REST_FRAMEWORK={
# "DEFAULT_AUTHENTICATION_CLASSES":["app01.utils.TokenAuth",],
# "DEFAULT_PERMISSION_CLASSES":["app01.utils.SVIPPermission",],
"PAGE_SIZE":3,
}
响应器
from rest_framework.response import Response
针对rest-frarmwork返回的数据进行各种操作,如果使用浏览器,那么响应器会渲染一个页面出来提供各种操作,如果使用postman,只返回一堆数据。
具体如下图:
postman:
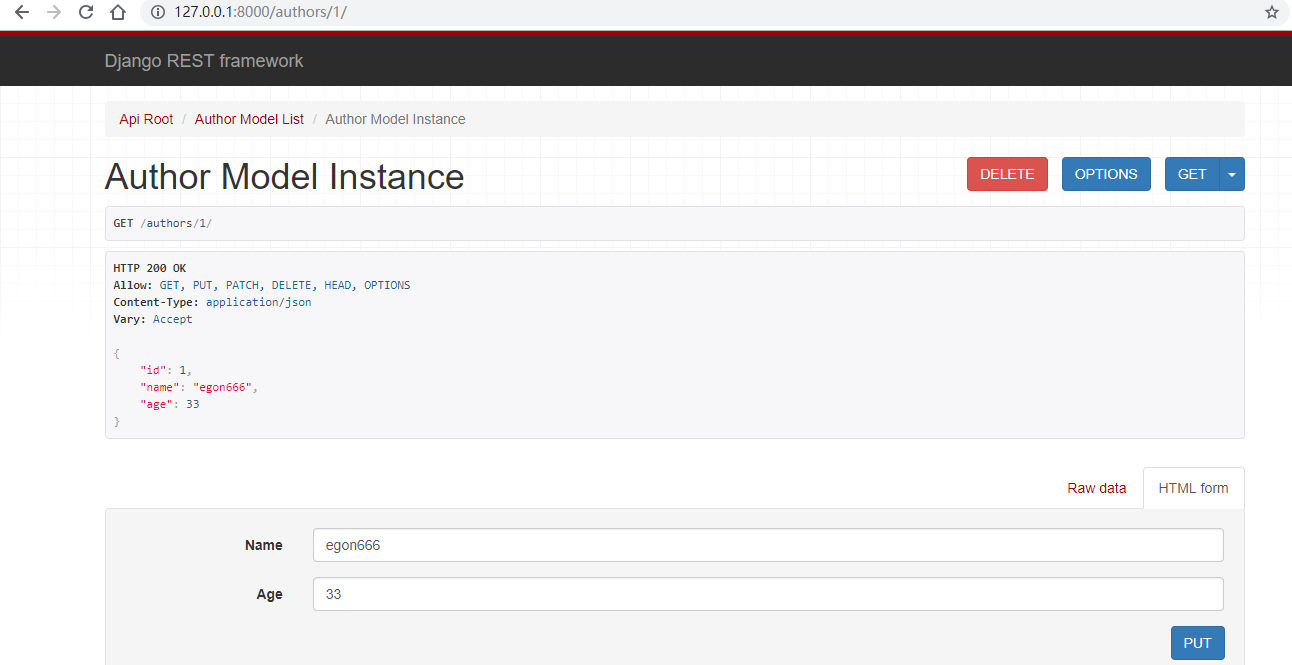
浏览器上:
这个页面可进行option,delete,put操作。
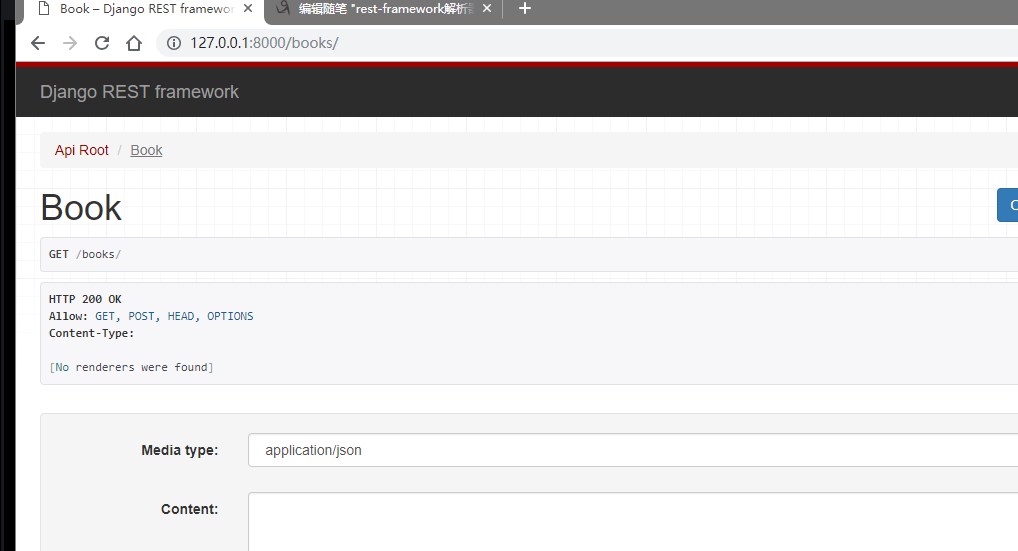
针对所有数据,下面可以进行get和post请求。
渲染器

这里可以使用Json的渲染器

也可以是这种页面形式的(用的少)
全局配置渲染器:

版本控制
1.先导入
from rest_framework.versioning import QueryParameterVersioning,URLPathVersioning
2.在APIView中
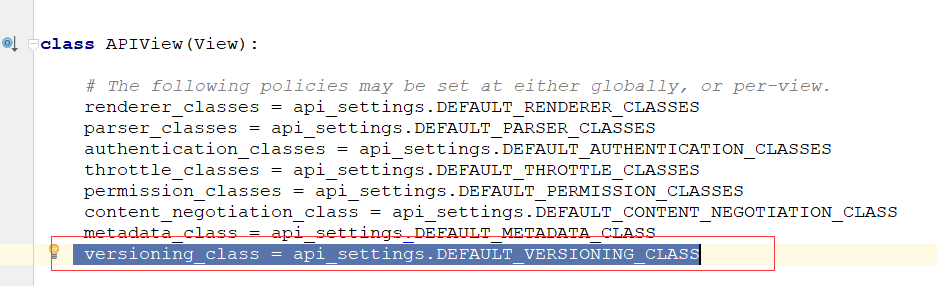
3.局部配置

4.全局配置
settings中配置:
REST_FRAMEWORK={
# "DEFAULT_AUTHENTICATION_CLASSES":["app01.utils.TokenAuth",],
# "DEFAULT_PERMISSION_CLASSES":["app01.utils.SVIPPermission",],
"PAGE_SIZE":1,
# 配置全局渲染器(Json格式的,和那种页面形式的)
# 'DEFAULT_RENDERER_CLASSES':['rest_framework.renderers.JSONRenderer',]
'DEFAULT_VERSION_CLASS':'rest_framework.versioning.QueryParameterVersioning',#使用哪种版本控制
'ALLOWED_VERSIONS':['v1','v2'], #允许的版本
'VERSION_PARAM':'version', #参数
'DEFAULT_VERSION':'v1', #默认版本
}
5.对于两种不同的配置要说的是。
(1)对于QueryParameterVersioning这种
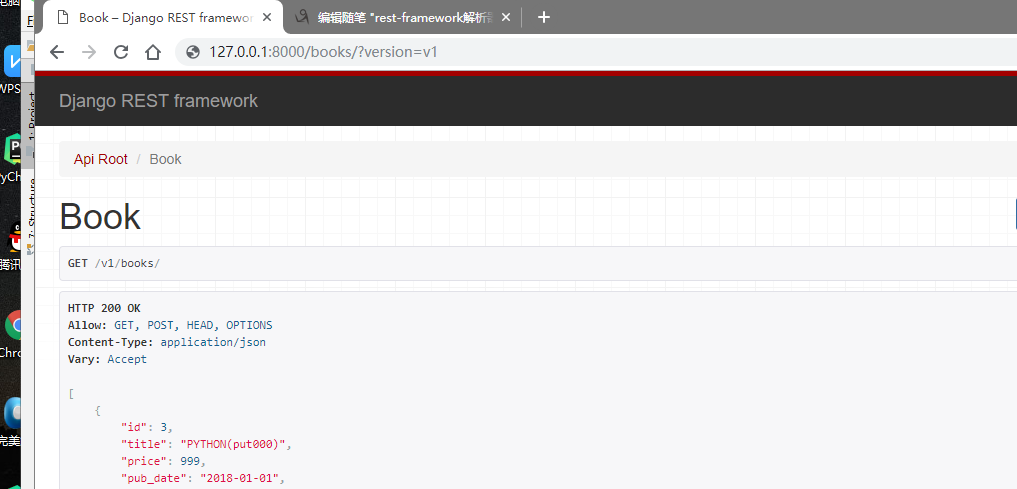
在url后缀加上版本。
后端通过request.version就可以拿到这个版本

(2)对于URLPathVersioning(推荐使用)
这个实在URL里面直接写。
首先要在url做一个配置。
url(r'^(?P<version>\w+)/books/$', views.BookView.as_view(),name="books"),
get请求参数拿到这个version。
def get(self,request,*args,**kwargs):
print("version",request.version)
#print(request.user) #token_obj.user.name
#print(request.auth) #token_obj.token
book_list=Book.objects.all()
#加入分页
pnp=MyPageNumberPagination()
books_page=pnp.paginate_queryset(book_list,request,self) # bs=BookSerializers(book_list,many=True)
bs2=BookModelSerializers(books_page,many=True,context={'request': request})
# return Response(bs.data)
return Response(bs2.data)
前端页面的URL是
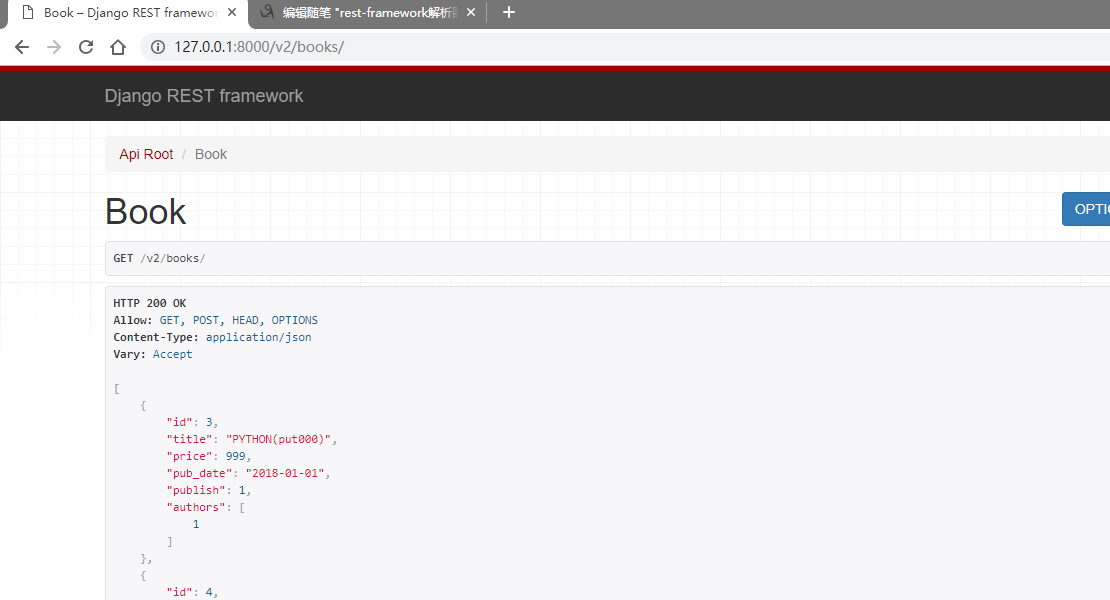
因为在全局做了允许配置,所以只能是v1,v2如果输入其他会报错。
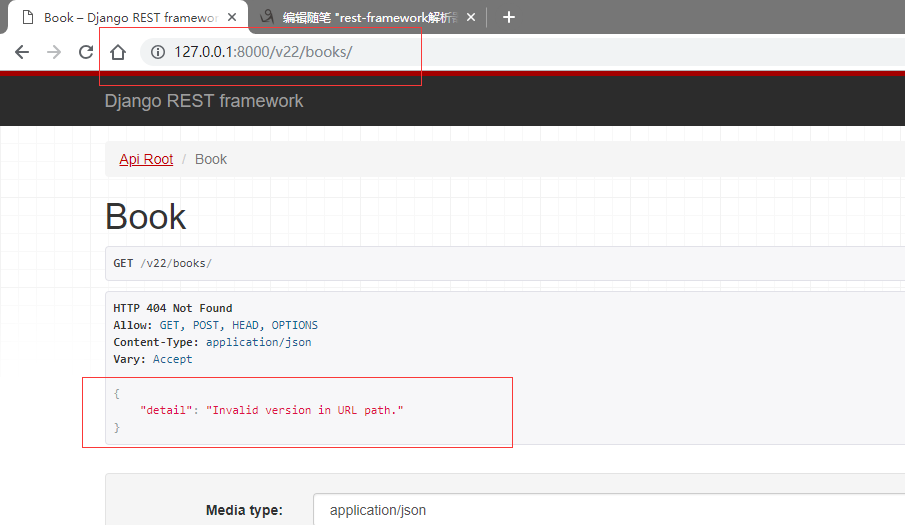
这就是版本控制。
rest-framework解析器,url控制,分页,响应器,渲染器,版本控制的更多相关文章
- Django_rest_framework_渲染器/解析器/路由控制/分页
目录 渲染器 解析器 路由控制 分页 渲染器 简介 什么是渲染器 根据 用户请求URL 或 用户可接受的类型,筛选出合适的 渲染组件. 渲染器的作用 序列化.友好的展示数据 渲染器配置 首先要在set ...
- rest-framework之响应器(渲染器)
rest-framework之响应器(渲染器) 本文目录 一 作用 二 内置渲染器 三 局部使用 四 全局使用 五 自定义显示模版 回到目录 一 作用 根据 用户请求URL 或 用户可接受的类型,筛选 ...
- rest-framework 响应器(渲染器)
一 作用: 根据 用户请求URL 或 用户可接受的类型,筛选出合适的 渲染组件. 用户请求URL: http://127.0.0.1:8000/test/?format=json http ...
- 5 解析器、url路由控制、分页、渲染器和版本
1 数据解析器 1 什么是解析器 相当于request 中content-type 对方传什么类型的数据,我接受什么样的数据:怎样解析 无论前面传的是什么数据,都可以解开 例如:django不能解析j ...
- restful(3):认证、权限、频率 & 解析器、路由控制、分页、渲染器、版本
models.py中: class UserInfo(models.Model): name = models.CharField(max_length=32) psw = models.CharFi ...
- rest-framework框架——解析器、ur控制、分页、响应器、渲染器、版本
一.解析器(parser) 解析器在reqest.data取值的时候才执行. 对请求的数据进行解析:是针对请求体进行解析的.表示服务器可以解析的数据格式的种类. from rest_framework ...
- Restful framework【第十篇】响应器(渲染器)
基本使用 -响应器(一般用默认就可以了) -局部配置 renderer_classes=[JSONRenderer,] -全局配置 'DEFAULT_RENDERER_CLASSES': ( 'res ...
- Django Rest Framework(分页、视图、路由、渲染器)
一.分页 试问如果当数据量特别大的时候,你是怎么解决分页的? 方式a.记录当前访问页数的数据id 方式b.最多显示120页等 方式c.只显示上一页,下一页,不让选择页码,对页码进行加密 1.基于lim ...
- DRF 解析器和渲染器
一,DRF 解析器 根据请求头 content-type 选择对应的解析器就请求体内容进行处理. 1. 仅处理请求头content-type为application/json的请求体 from dja ...
随机推荐
- php伪协议,利用文件包含漏洞
php支持多种封装协议,这些协议常被CTF出题中与文件包含漏洞结合,这里做个小总结.实验用的是DVWA平台,low级别,phpstudy中的设置为5.4.45版本, 设置allow_url_fopen ...
- 4.6Python数据处理篇之Matplotlib系列(六)---plt.hist()与plt.hist2d()直方图
目录 目录 前言 (一)直方图 (二)双直方图 目录 前言 今天我们学习的是直方图,导入的函数是: plt.hist(x=x, bins=10) 与plt.hist2D(x=x, y=y) (一)直方 ...
- LeetCode算法题-Valid Perfect Square(Java实现-四种解法)
这是悦乐书的第209次更新,第221篇原创 01 看题和准备 今天介绍的是LeetCode算法题中Easy级别的第77题(顺位题号是367).给定正整数num,写一个函数,如果num是一个完美的正方形 ...
- Lingo求解线性规划案例4——下料问题
凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 造纸厂接到定单,所需卷纸的宽度和长度如表 卷纸的宽度 长度 5 7 9 10000 30000 20000 工 ...
- Spring Data JPA 简单查询--方法定义规则
一.常用规则速查 1 And 并且2 Or 或3 Is,Equals 等于4 Between 两者之间5 LessThan 小于6 LessThanEqual 小于等于7 Gre ...
- MySQL 初识别语句,数据库、表、行的增删改查
一.MySQL 开场语句 1.登陆 mysql -u root -p ; #回车然后输入密码 2.退出 eixt | quit #二者选其一 3.查看数据文件路径(配置文件中学习的) show glo ...
- SpringMVC实现国际化过程中所遇问题
前言:在利用SpringMVC实现国际化的过程中,看似简单,实则还是遇到了一些小问题,现在笔者对所遇问题总结如下. 注:笔者所用的编辑器为Intellij IEDA 14.1.7版本 1.国际化资源文 ...
- Linux之定时任务crond
定时任务说明与分类 定时任务的应用场景举例 每天晚上 12点备份/etc/目录 tar 定时任务的三种分类 crond(crontab)定时任务软件(软件包cronie),用的最多的一种 atd,应用 ...
- 在新建的python3环境下运行jupyter失败的原因
在deeplearning中再运行jupyter notebook就出现了错误: (deeplearning) userdeMBP:~ user$ jupyter notebook -bash: ju ...
- ogg-01027(长事务)
OGG-01027(长事务) 示例9-25: WARNING OGG-01027 Long Running Transaction: XID 82.4.242063, Items 0, Extra ...