Redis的底层数据结构-跳表
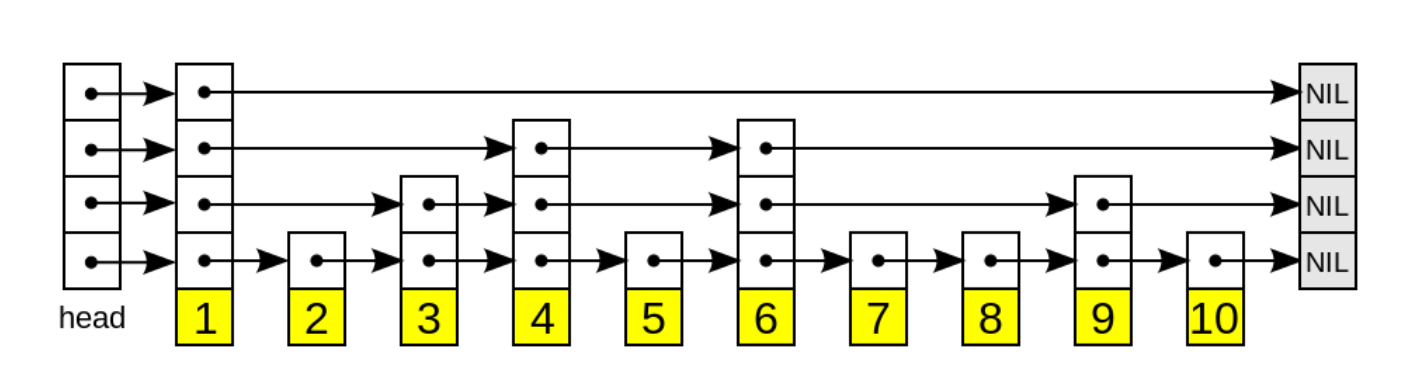
跳跃表(skiplist)是一种有序数据结构,它通过在每个节点中维持多个指向其它节点的指针,从而达到快速访问节点的目的。具有如下性质:
1、由很多层结构组成;
2、每一层都是一个有序的链表,排列顺序为由高层到底层,都至少包含两个链表节点,分别是前面的head节点和后面的nil节点;
3、最底层的链表包含了所有的元素;
4、如果一个元素出现在某一层的链表中,那么在该层之下的链表也全都会出现(上一层的元素是当前层的元素的子集);
5、链表中的每个节点都包含两个指针,一个指向同一层的下一个链表节点,另一个指向下一层的同一个链表节点;
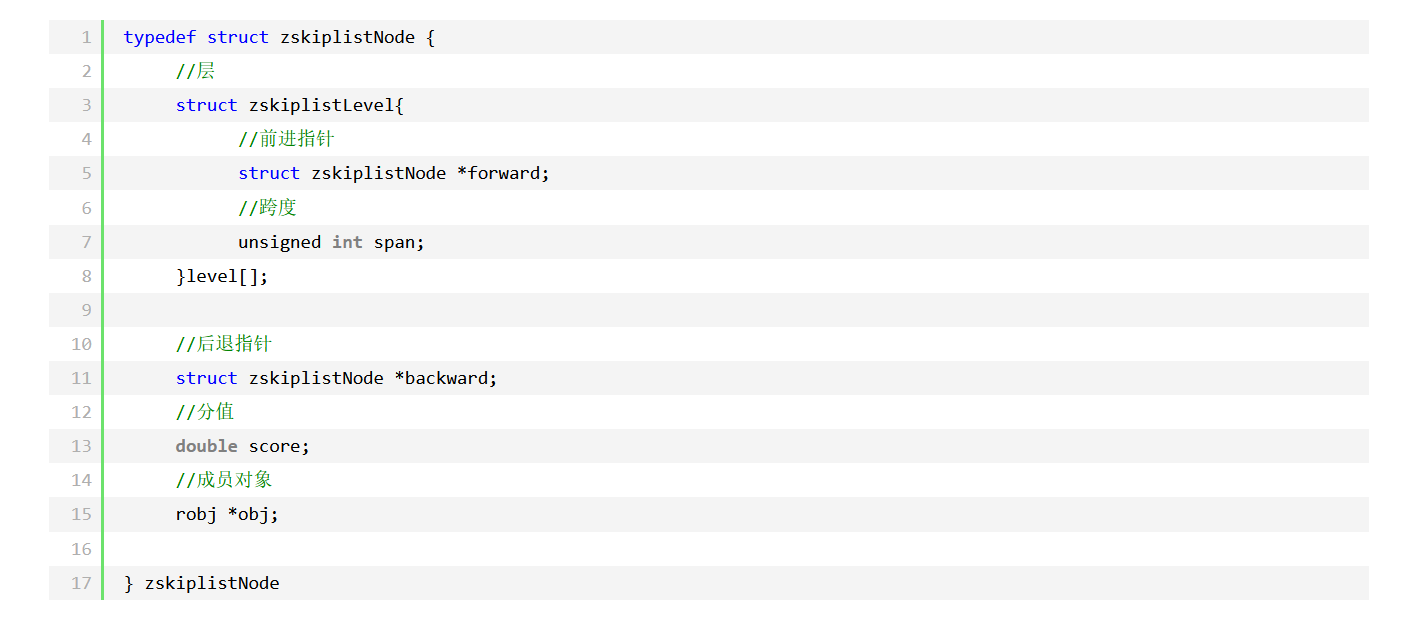
Redis中跳跃表节点定义如下:
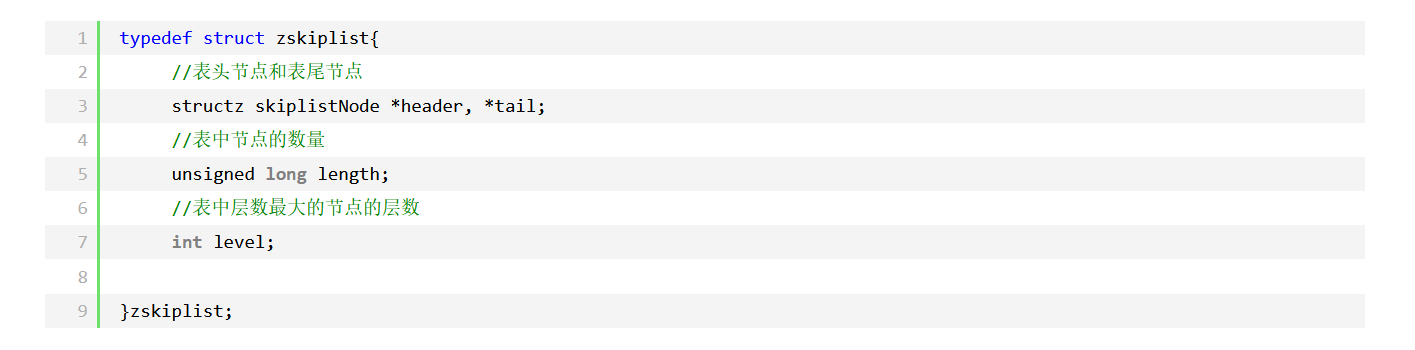
多个跳跃表节点构成一个跳跃表:

①、搜索:从最高层的链表节点开始,如果比当前节点要大和比当前层的下一个节点要小,那么则往下找,也就是和当前层的下一层的节点的下一个节点进行比较,以此类推,一直找到最底层的最后一个节点,如果找到则返回,反之则返回空。
②、插入:首先确定插入的层数,有一种方法是假设抛一枚硬币,如果是正面就累加,直到遇见反面为止,最后记录正面的次数作为插入的层数。当确定插入的层数k后,则需要将新元素插入到从底层到k层
③、删除:在各个层中找到包含指定值的节点,然后将节点从链表中删除即可,如果删除以后只剩下头尾两个节点,则删除这一层。
属性分析
层:level 数组包含多个元素,每个元素包含指向其他节点的指针。根据幕次定律(power law,越大的数出现的概率越小)随机生成一个介于 1 和 32 之间的值(Redis5 之后最大为 64)作为 level 数组的大小,这个大小就是层的高度,节点的第一层是 level[0] = L1
前进指针:forward 用于从表头到表尾方向正序(升序)遍历节点,遇到 NULL 停止遍历
跨度:span 用于记录两个节点之间的距离,用来计算排位(rank):
两个节点之间的跨度越大相距的就越远,指向 NULL 的所有前进指针的跨度都为 0
在查找某个节点的过程中,将沿途访问过的所有层的跨度累计起来,结果就是目标节点在跳跃表中的排位,按照上图所示:
查找分值为 3.0 的节点,沿途经历的层:查找的过程只经过了一个层,并且层的跨度为 3,所以目标节点在跳跃表中的排位为 3
查找分值为 2.0 的节点,沿途经历的层:经过了两个跨度为 1 的节点,因此可以计算出目标节点在跳跃表中的排位为 2
后退指针:backward 用于从表尾到表头方向逆序(降序)遍历节点
分值:score 属性一个 double 类型的浮点数,跳跃表中的所有节点都按分值从小到大来排序
成员对象:obj 属性是一个指针,指向一个 SDS 字符串对象。同一个跳跃表中,各个节点保存的成员对象必须是唯一的,但是多个节点保存的分值可以是相同的,分值相同的节点将按照成员对象在字典序中的大小来进行排序(从小到大)
跳表的演化过程案例
对于单链表来说,即使数据是已经排好序的,想要查询其中的一个数据,只能从头开始遍历链表,这样效率很低,时间复杂度很高,是 O(n)。
那我们有没有什么办法来提高查询的效率呢?我们可以为链表建立一个“索引”,这样查找起来就会更快,如下图所示,我们在原始链表的基础上,每两个结点提取一个结点建立索引,我们把抽取出来的结点叫做索引层或者索引,down 表示指向原始链表结点的指针
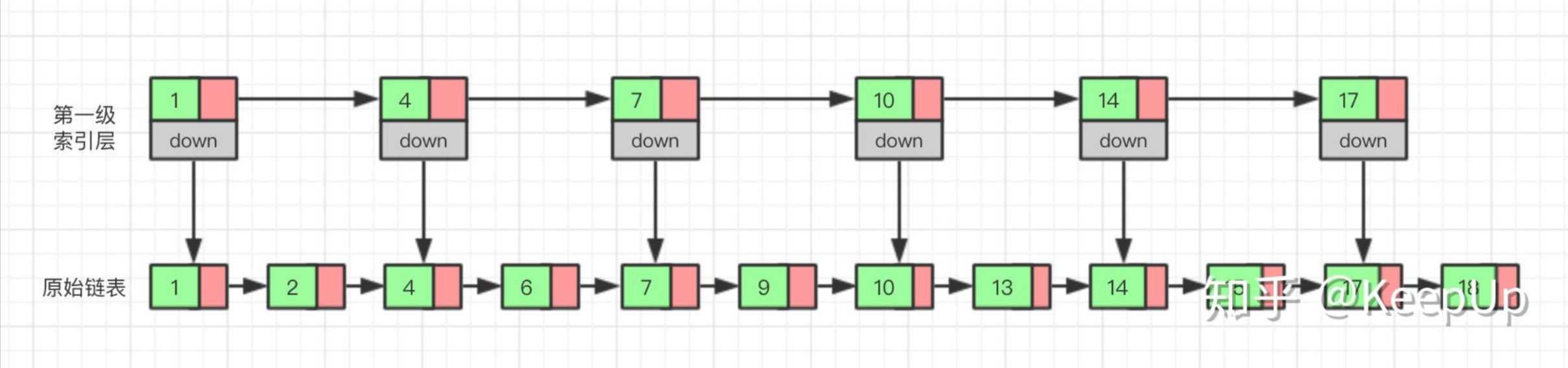
现在如果我们想查找一个数据,比如说 15,我们首先在索引层遍历,当我们遍历到索引层中值为 14 的结点时,我们发现下一个结点的值为 17,所以我们要找的 15 肯定在这两个结点之间。这时我们就通过 14 结点的 down 指针,回到原始链表,然后继续遍历,这个时候我们只需要再遍历两个结点,就能找到我们想要的数据。好我们从头看一下,整个过程我们一共遍历了 7 个结点就找到我们想要的值,如果没有建立索引层,而是用原始链表的话,我们需要遍历 10 个结点
通过这个例子我们可以看出来,通过建立一个索引层,我们查找一个基点需要遍历的次数变少了,也就是查询的效率提高了
那么如果我们给索引层再加一层索引呢?遍历的结点会不会更少呢,效率会不会更高呢?我们试试就知道了
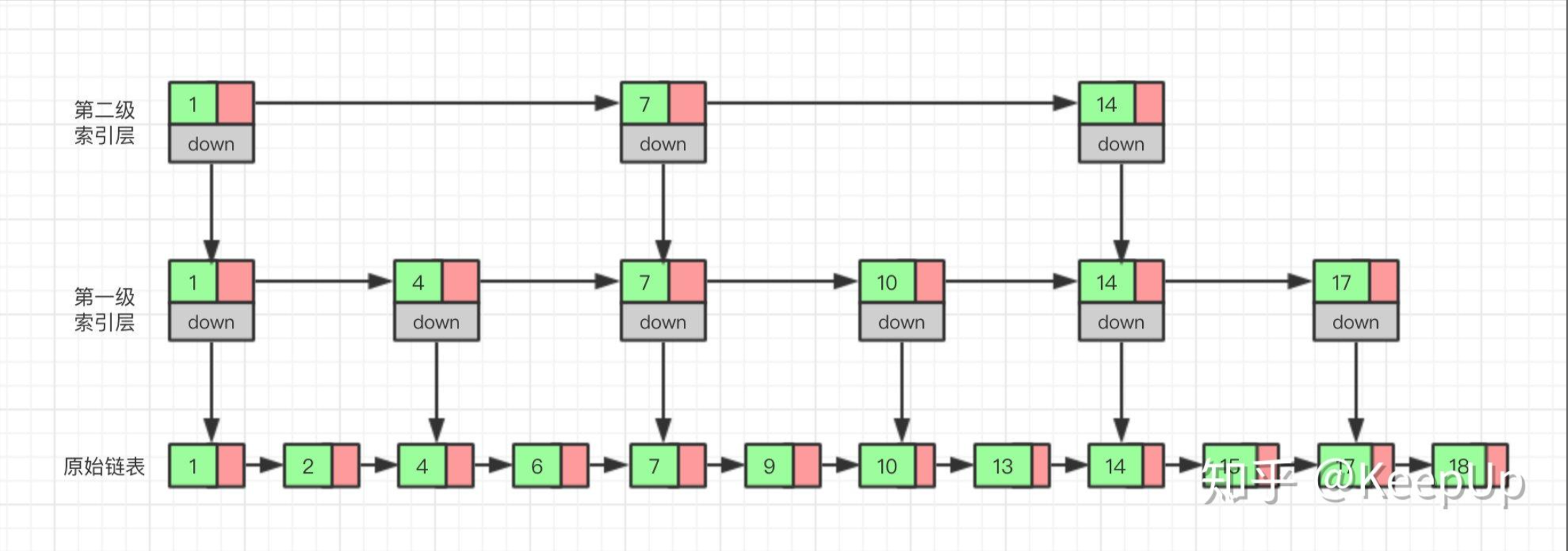
现在我们再来查找 15,我们从第二级索引开始,最后找到 15,一共遍历了 6 个结点,果然效率更高。
当然,因为我们举的这个例子数据量很小,所以效率提升的不是特别明显,如果数据量非常大的时候,我们多建立几层索引,效率提升的将会非常的明显,感兴趣的可以自己试一下,这里我们就不举例子了
这种通过对链表加多级索引的机构,就是跳表了。
Redis的底层数据结构-跳表的更多相关文章
- Redis 的底层数据结构(跳跃表)
字典相对于数组,链表来说,是一种较高层次的数据结构,像我们的汉语字典一样,可以通过拼音或偏旁唯一确定一个汉字,在程序里我们管每一个映射关系叫做一个键值对,很多个键值对放在一起就构成了我们的字典结构. ...
- Redis(二)--- Redis的底层数据结构
1.Redis的数据结构 Redis 的底层数据结构包含简单的动态字符串(SDS).链表.字典.压缩列表.整数集合等等:五大数据类型(数据对象)都是由一种或几种数结构构成. 在命令行中可以使用 OBJ ...
- Redis中为什么使用跳表---------转自http://blog.csdn.net/u010412301/article/details/64923131
最近在研究数据库的一些底层实现,百度的面试官问到了跳表,当时没有回答上来,在csdn上看到了这篇文章,感觉写的比较好,希望大家可以多多交流. Redis里面使用skiplist是为了实现sorted ...
- Redis 的底层数据结构(对象)
目前为止,我们介绍了 redis 中非常典型的五种数据结构,从 SDS 到 压缩列表,这都是 redis 最底层.最常用的数据结构,相信你也掌握的不错. 但 redis 实际存储键值对的时候,是基于对 ...
- Redis源码研究--跳表
-------------6月29日-------------------- 简单看了下跳表这一数据结构,理解起来很真实,效率可以和红黑树相比.我就喜欢这样的. typedef struct zski ...
- Redis详解(四)------ redis的底层数据结构
上一篇博客我们介绍了 redis的五大数据类型详细用法,但是在 Redis 中,这几种数据类型底层是由什么数据结构构造的呢?本篇博客我们就来详细介绍Redis中五大数据类型的底层实现. 1.演示数据类 ...
- Redis 详解 (四) redis的底层数据结构
目录 1.演示数据类型的实现 2.简单动态字符串 3.链表 4.字典 5.跳跃表 6.整数集合 7.压缩列表 8.总结 上一篇博客我们介绍了 redis的五大数据类型详细用法,但是在 Redis 中, ...
- 深入理解Redis:底层数据结构
简介 redis[1]是一个key-value存储系统.和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list(链表).set(集合).zset(sorte ...
- redis string底层数据结构sds
redis的string没有采用c语言的字符串数组而采用自定义的数据结构SDS(simple dynamic string)设计 len 为字符串的实际长度 在redis中获取字符串的key长度的时 ...
- Redis 的底层数据结构(字典)
字典相对于数组,链表来说,是一种较高层次的数据结构,像我们的汉语字典一样,可以通过拼音或偏旁唯一确定一个汉字,在程序里我们管每一个映射关系叫做一个键值对,很多个键值对放在一起就构成了我们的字典结构. ...
随机推荐
- law Intermediate walkthrough pg
靶场很简单分数只有10分跟平常做的20分的中级靶场比确实简单 我拿来放松的 算下来30分钟解决战斗 nmap 扫到80端口web界面 是个框架 搜exp https://www.exploit-db. ...
- 拥有自己的解析器(C#实现LALR(1)语法解析器和miniDFA词法分析器的生成器)
拥有自己的解析器(C#实现LALR(1)语法解析器和miniDFA词法分析器的生成器) 参考lex和yacc的输入格式,参考虎书<现代编译原理-C语言描述>的算法,不依赖第三方库,大力整合 ...
- 使用Vant做移动端对图片预览ImagePreview和List的理解
使用Vant3做移动端的感受 最近在使用Vant3做移动端. 感觉还可以,使用起来也简单,但是也遇见一些坑. 图片预览ImagePreview的使用 在使用图片预览的时候, 我们在main.js中进行 ...
- 小程序uView中loadMore 加载更多
<u-loadmore :status="status" :icon-type="iconType" :load-text="loadText& ...
- 微信小程序block的作用
有了block标签过后,你就可以把if 或则 for 语句写在block标签里面; 这样就控制了这一块的逻辑. 个人建议是要是v-if和v-for的都可以写在block上: block并不是一个组件, ...
- .NET周刊【1月第2期 2025-01-12】
国内文章 [.NET] API网关选择:YARP还是Ocelot? https://www.cnblogs.com/madtom/p/18655530 本文详细比较了YARP和Ocelot两种API网 ...
- PC端自动化测试实战教程-1-pywinauto 环境搭建(详细教程)
1.简介 之前总有人在群里或者私信留言问:Windows系统安装的软件如何自动化测试呢?因为没有接触过或者遇到过,所以说实话宏哥当时也不清楚怎么实现,怎么测试.然而在一次偶然的机会接触到了Python ...
- linux ubuntu更改软件源
更换步骤 sudo cp /etc/apt/sources.list /etc/apt/sources.list.back sudo vim /etc/apt/sources.list 替换为下面内容 ...
- 使用iceberg-flink读取iceberg v2表
一.背景 mysql数据入湖后,有同事需要实时抽取iceberg v2表,想通过iceberg做分钟级实时数仓.目前flink社区暂不支持读取v2表.腾讯内部支持 目前只能用Oceanus内置conn ...
- DeepSeek普照的阳光下,继续RAG还是Distillation?
什么是RAG RAG概述 RAG,全称为Retrieval-Augmented Generation(检索增强生成),是一种结合了信息检索和文本生成的人工智能技术.简单来说,RAG通过从大量文档或数据 ...