唯一ID生成器--雪花算法
在微服务架构,分布式系统中的操作会有一些全局性ID的需求,所以我们不能用数据库本身的自增功能来产生主键值,只能由程序来生成唯一的主键值。我们采用的是twitter的snokeflake(雪花)算法。
说明
程序snokeflake会生成一个64bit的数据,结构如下
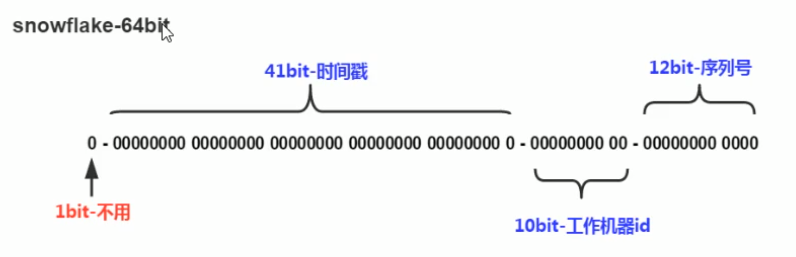
最后12位的序列号容纳的大小为4096,同一毫秒,同个机器产生超过这个数的ID,就会自动等待一毫秒,进入下一个时间戳继续计数。
代码
import java.lang.management.ManagementFactory;
import java.net.InetAddress;
import java.net.NetworkInterface;
/**
* 雪花算法代码实现
*/
public class IdWorker {
/**
* twepoch: 时间起始标记点,作为基准,一般取系统的最近时间(一旦确定不能变动)
*/
private final static long twepoch = 1288834974657L;
// 机器标识位数
private final static long workerIdBits = 5L;
// 数据中心标识位数
private final static long datacenterIdBits = 5L;
// 机器ID最大值
private final static long maxWorkerId = -1L ^ (-1L << workerIdBits);
// 数据中心ID最大值
private final static long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
// 毫秒内自增位
private final static long sequenceBits = 12L;
// 机器ID偏左移12位
private final static long workerIdShift = sequenceBits;
// 数据中心ID左移17位
private final static long datacenterIdShift = sequenceBits + workerIdBits;
// 时间毫秒左移22位
private final static long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
private final static long sequenceMask = -1L ^ (-1L << sequenceBits);
/* 上次生产id时间戳 */
private static long lastTimestamp = -1L;
// 0,并发控制
private long sequence = 0L;
private final long workerId;
// 数据标识id部分
private final long datacenterId;
public IdWorker(){
this.datacenterId = getDatacenterId(maxDatacenterId);
this.workerId = getMaxWorkerId(datacenterId, maxWorkerId);
}
/**
* @param workerId
* 工作机器ID
* @param datacenterId
* 序列号
*/
public IdWorker(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
/**
* 获取下一个ID
*
* @return
*/
public synchronized long nextId() {
long timestamp = timeGen();
if (timestamp < lastTimestamp) {
throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
if (lastTimestamp == timestamp) {
// 当前毫秒内,则+1
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
// 当前毫秒内计数满了,则等待下一秒
timestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = 0L;
}
lastTimestamp = timestamp;
// ID偏移组合生成最终的ID,并返回ID
long nextId = ((timestamp - twepoch) << timestampLeftShift)
| (datacenterId << datacenterIdShift)
| (workerId << workerIdShift) | sequence;
return nextId;
}
private long tilNextMillis(final long lastTimestamp) {
long timestamp = this.timeGen();
while (timestamp <= lastTimestamp) {
timestamp = this.timeGen();
}
return timestamp;
}
private long timeGen() {
return System.currentTimeMillis();
}
/**
* <p>
* 获取 maxWorkerId
* </p>
*/
protected static long getMaxWorkerId(long datacenterId, long maxWorkerId) {
StringBuffer mpid = new StringBuffer();
mpid.append(datacenterId);
String name = ManagementFactory.getRuntimeMXBean().getName();
if (!name.isEmpty()) {
/*
* GET jvmPid
*/
mpid.append(name.split("@")[0]);
}
/*
* MAC + PID 的 hashcode 获取16个低位
*/
return (mpid.toString().hashCode() & 0xffff) % (maxWorkerId + 1);
}
/**
* <p>
* 数据标识id部分
* </p>
*/
protected static long getDatacenterId(long maxDatacenterId) {
long id = 0L;
try {
InetAddress ip = InetAddress.getLocalHost();
NetworkInterface network = NetworkInterface.getByInetAddress(ip);
if (network == null) {
id = 1L;
} else {
byte[] mac = network.getHardwareAddress();
id = ((0x000000FF & (long) mac[mac.length - 1])
| (0x0000FF00 & (((long) mac[mac.length - 2]) << 8))) >> 6;
id = id % (maxDatacenterId + 1);
}
} catch (Exception e) {
System.out.println(" getDatacenterId: " + e.getMessage());
}
return id;
}
}
欢迎批评指正!
唯一ID生成器--雪花算法的更多相关文章
- ID 生成器 雪花算法
https://blog.csdn.net/wangming520liwei/article/details/80843248 ID 生成器 雪花算法 2018年06月28日 14:58:43 wan ...
- 生成主键ID,唯一键id,分布式ID生成器雪花算法代码实现
工具类: package com.ihrm.common.utils; import java.lang.management.ManagementFactory; import java.net. ...
- 百度开源的分布式唯一ID生成器UidGenerator,解决了时钟回拨问题
UidGenerator是百度开源的Java语言实现,基于Snowflake算法的唯一ID生成器.而且,它非常适合虚拟环境,比如:Docker.另外,它通过消费未来时间克服了雪花算法的并发限制.Uid ...
- springboot 集成百度的唯一ID生成器
UidGenerator是百度开源的Java语言实现,基于Snowflake算法的唯一ID生成器.而且,它非常适合虚拟环境,比如:Docker.另外,它通过消费未来时间克服了雪花算法的并发限制.Uid ...
- 分布式ID生成 - 雪花算法
雪花算法是一种生成分布式全局唯一ID的经典算法,关于雪花算法的解读网上多如牛毛,大多抄来抄去,这里请参考耕耘的小象大神的博客ID生成器,Twitter的雪花算法(Java) 网上的教程一般存在两个问题 ...
- Spring Boot集成全局唯一ID生成器
流水号生成器(全局唯一 ID生成器)是服务化系统的基础设施,其在保障系统的正确运行和高可用方面发挥着重要作用.而关于流水号生成算法首屈一指的当属 Snowflake雪花算法,然而 Snowflake本 ...
- 全局ID生成--雪花算法
分布式ID常见生成策略: 分布式ID生成策略常见的有如下几种: 数据库自增ID. UUID生成. Redis的原子自增方式. 数据库水平拆分,设置初始值和相同的自增步长. 批量申请自增ID. 雪花算法 ...
- java 实现唯一ID生成器
2014-11-08 内容存档在evernote,笔记名"java 实现唯一ID生成器"
- 分布式唯一id生成器的想法
0x01 起因 前端时间遇到一个问题,怎么快速生成唯一的id,后来采用了hashid的方法.最近在网上读到了美团关于分布式唯一id生成器的解决方案, 其中提到了三种生成法:(建议看一下这篇文章,写得很 ...
随机推荐
- SpringBoot要点之使用Actuator监控
Actuator是Springboot提供的用来对应用系统进行自省和监控的功能模块,借助于Actuator开发者可以很方便地对应用系统某些监控指标进行查看.统计等. 在pom文件中加入spring-b ...
- ACM数据结构-树状数组
模板: int n; int tree[LEN]; int lowbit(int x){ return x&-x; } void update(int i,int d){//index,del ...
- 洛谷 P5614题解
吐槽:数据好像有点水,直接枚举到200可以得80 points. 另:我还是太弱了,比赛的时候只有90 points,#7死卡不过去,最后发现是没有判断 \(z_1\) 和 \(z_2\) 的范围-- ...
- C++ STL(标准模板库)的学习了解
C++ STL(标准模板库)是一套功能强大的 C++ 模板类,提供了通用的模板类和函数,这些模板类和函数可以实现多种流行和常用的算法和数据结构,如向量.链表.队列.栈. C++ 标准模板库的核心包括以 ...
- bzoj 3585 mex - 线段树 - 分块 - 莫队算法
Description 有一个长度为n的数组{a1,a2,...,an}.m次询问,每次询问一个区间内最小没有出现过的自然数. Input 第一行n,m. 第二行为n个数. 从第三行开始,每行一个询问 ...
- 欧拉法求解常微分方程(c++)
#include<iostream> #include<iomanip> using namespace std; int main() { double x, y, h; ...
- 《京东B2B业务架构演变》阅读笔记
一.京东 B2B 业务的定位 让各类型的企业都可以在京东的 B 平台上进行采购.建立采购关系. 京东 B2B 的用户群体主要分为 2 类: 一类是大 B 用户.另一类是小 B 用户.京东 B 平台需要 ...
- java NIO面试题剖析
转载:https://mp.weixin.qq.com/s/YIcXaH7AWLJbPjnTUwnlyQ 首先我们分别画图来看看,BIO.NIO.AIO,分别是什么? BIO:传统的网络通讯模型,就是 ...
- 【Beta】“北航社团帮”发布声明——小程序v2.0与网页端v1.0
目录 Beta版本新功能 小程序v2.0新功能 新功能列表 功能详情图 新功能动图展示 网页端v1.0功能 登录方式 社团信息的修改 新闻的录入和修改 活动的录入和修改 这一版修复的缺陷 Beta版本 ...
- PhastCons | 序列保守性打分
这是一个进化学上的概念,基因组的序列是不断进化而来的,根据45个脊椎动物的基因组序列,通过多重比对,我们就可以知道人类基因组上每个位置的保守性,一些高度保守的区域可以做非常有意思的下游分析. This ...