使用正则表达式爬取500px上的图片
网址:https://500px.com/seanarcher,seanarcher是一个up主的名字
打开这个网址,会发现有好多图片,具体到每一个图片的url地址 https://500px.com/photo/273383049/galya-by-sean-archer,其中273383049为图片的id
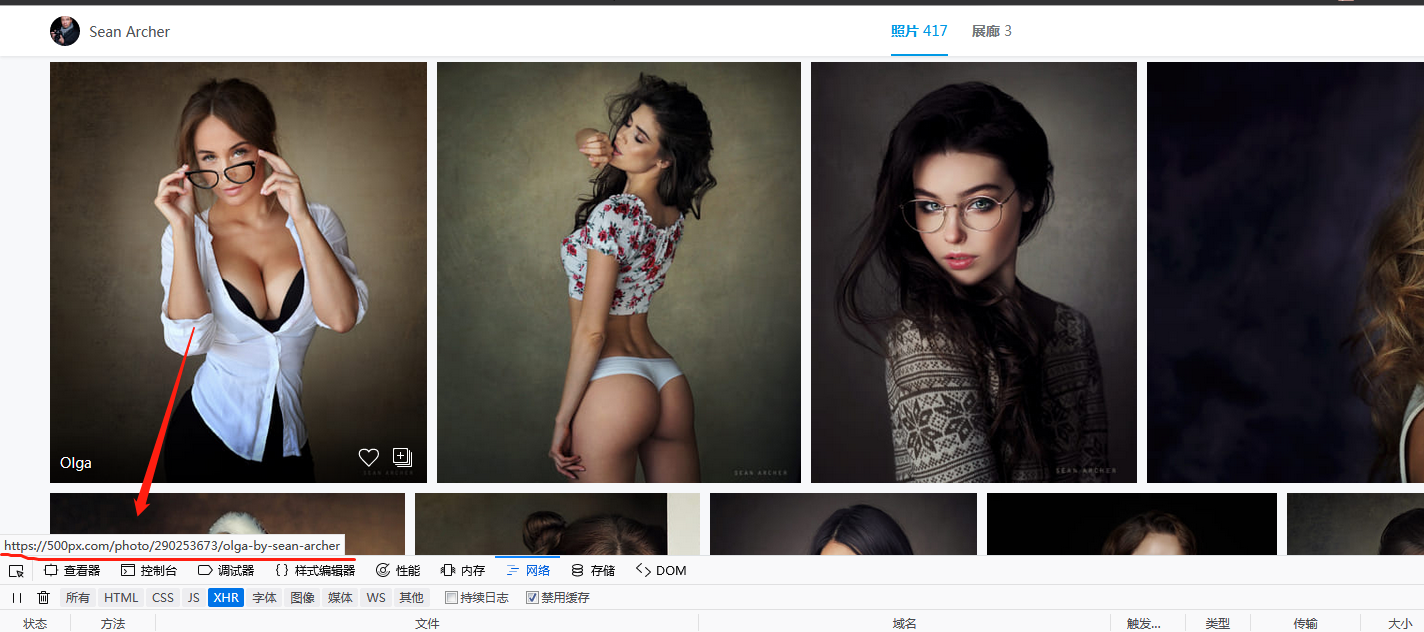
使用https://api.500px.com/v1/photos?ids=图片id,也就是https://api.500px.com/v1/photos?ids=273383049可以访问每一个图片的详情json信息
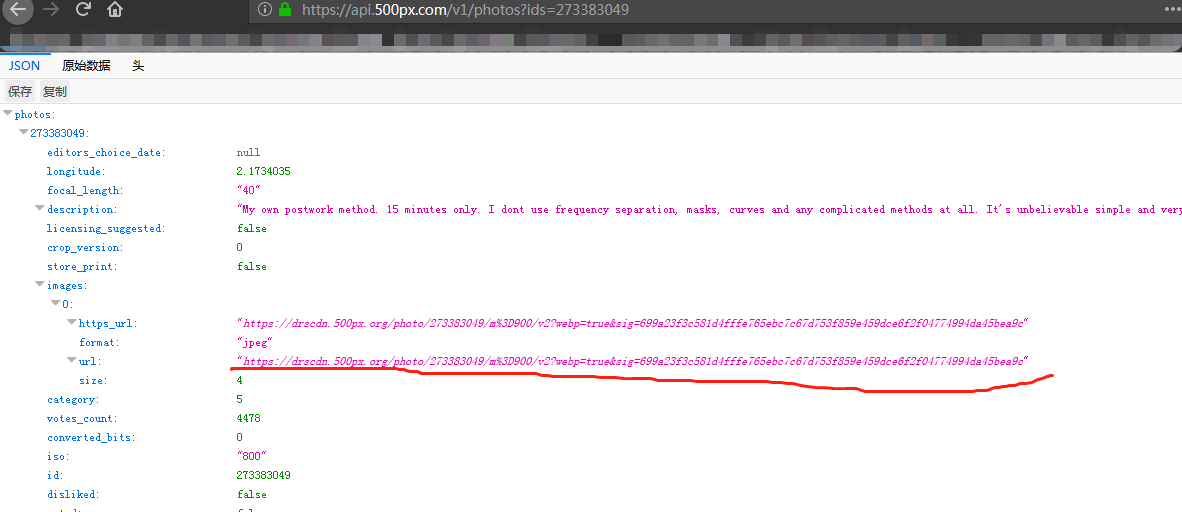
那是不是可以通过如下思路来获取图片信息呢?
1.访问索引页,获得每个图片的id
2.根据图片id构造新的url地址,
3.访问每个图片的url地址,获得图片链接
4.使用图片链接下载图片
我起初也是这样想的,可以第一步确实现不了,访问索引页后获得的数据中根本就没有所有的图片id信息,有关的只有这部分数据,还是在script标签里,处理这些数据后发现只有50个图片数据信息.
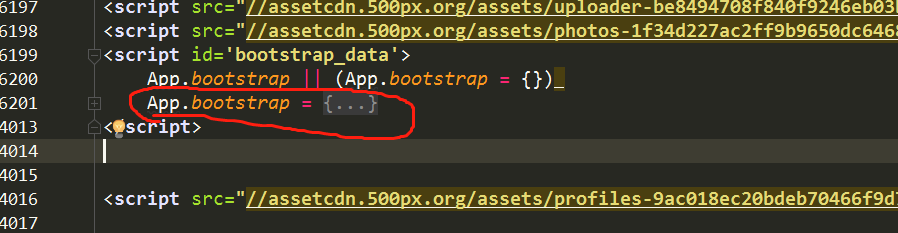
然后再继续分析,调试模式到XHR,发现一个有意思的现象

发现这个请求有返回的json数据,是直接从第二页开始的,总共8页,photos参数中就是各个图片的具体信息,跟使用https://api.500px.com/v1/photos?ids=图片id访问的结果差不多
但是有一个问题,直接访问这个地址会报错:


结合上述的情况分析,可以得到大致的结论: 该网站的 首页信息是静态加载的,从第 2 页开始是采用了 Ajax 动态加载,URL 不同,需要分别进行解析提取。
1.初次请求网站是直接在html中使用script的标签返回50条数据信息
2.页面继续往下拉,使用的是ajax加载页面的方式,每次加载一页,又50条数据,直到第8页图片信息加载完才结束
3.结合以上分析,差不多也就400多条数据,算是符合要求
那么现在的问题是如何获取ajax加载出来的数据信息?
很遗憾,我也暂时还没找到有啥解决的办法.
唯一想到的笨办法是使用浏览器获取返回的json数据,保存下来,然后分析这些json数据,从而获得图片下载链接,进而下载图片
一:只下载首页50个图片
#!/usr/bin/env python
# -*- coding: utf-8 -*- import csv
import json
import os
import re
from _md5 import md5 import pymongo
import requests
from requests.exceptions import RequestException MONGO_URL = 'localhost'
MONGO_DB = 'maoyan'
MONGO_TABLE = 'gril' client = pymongo.MongoClient(MONGO_URL, connect=False)
db = client[MONGO_DB] def get_one_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0'
}
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
else:
return None
except RequestException:
print('请求失败')
return None def parse_one_page(html):
pattern = re.compile("<script id='bootstrap_data'>.*?{}.*?App.bootstrap = (.*?)</script>", re.S | re.M)
items = re.findall(pattern, html)
image_data = json.loads(items[0])['userdata']['photos']
# print(image_data)
# print(type(image_data))
for i in range(len(image_data)):
yield {
'id': image_data[i]['id'],
'name': image_data[i]['name'],
'taken_at': image_data[i]['taken_at'],
'image_url': image_data[i]['image_url'][-3], # 图片链接有多种大小格式,选择格式最大的
} # 数据存储到csv
def write_to_file3(item):
with open('gril.csv', 'a', encoding='utf_8_sig', newline='') as f:
# 'a'为追加模式(添加)
# utf_8_sig格式导出csv不乱码
fieldnames = ['id', 'name', 'taken_at', 'image_url']
w = csv.DictWriter(f, fieldnames=fieldnames)
# w.writeheader()
w.writerow(item) # 保存到数据库中
def save_to_mongo(result):
if db[MONGO_TABLE].insert(result):
print('Successfully Saved to Mongo', result)
return True
return False # 请求图片url,获取图片二进制数据
def download_image(url):
try:
response = requests.get(url)
if response.status_code == 200:
save_image(response.content) # response.contenter二进制数据 response.text文本数据
return None
except RequestException:
print('请求图片出错')
return None def save_image(content):
file_path = 'D:\\pachong\\gril\\{1}.{2}'.format(os.getcwd(), md5(content).hexdigest(), 'jpg')
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(content) def main():
url = 'https://500px.com/seanarcher'
html = get_one_page(url)
for item in parse_one_page(html): # 只有50个图片,实际有400多个,还有待进一步研究
# write_to_file3(item) # 保存到csv文件
# save_to_mongo(item) # 保存到数据库
download_image(item['image_url']) if __name__ == '__main__':
main()
效果截图:

二:获取剩余图片
复制其他也返回的json数据,构造如下形式:

def parse_page_detail(data):
image_data = data['photos']
for i in range(len(image_data)):
yield {
'image_url': image_data[i]['image_url'][-3], # 图片链接有多种大小格式,选择格式最大的
} # 请求图片url,获取图片二进制数据
def download_image(url):
try:
response = requests.get(url)
if response.status_code == 200:
save_image(response.content) # response.contenter二进制数据 response.text文本数据
return None
except RequestException:
print('请求图片出错')
return None def save_image(content):
file_path = 'D:\\pachong\\500px_all\\{1}.{2}'.format(os.getcwd(), md5(content).hexdigest(), 'jpg')
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(content) def get_other(data):
for item in parse_page_detail(data):
download_image(item['image_url']) get_other(data_2)
get_other(data_3)
get_other(data_4)
get_other(data_5)
get_other(data_6)
get_other(data_7)
get_other(data_8) 实际效果:
使用正则表达式爬取500px上的图片的更多相关文章
- 爬虫入门(三)——动态网页爬取:爬取pexel上的图片
Pexel上有大量精美的图片,没事总想看看有什么好看的自己保存到电脑里可能会很有用 但是一个一个保存当然太麻烦了 所以不如我们写个爬虫吧(๑•̀ㅂ•́)و✧ 一开始学习爬虫的时候希望爬取pexel上的 ...
- python网络爬虫之解析网页的正则表达式(爬取4k动漫图片)[三]
前言 hello,大家好 本章可是一个重中之重,因为我们今天是要爬取一个图片而不是一个网页或是一个json 所以我们也就不用用到selenium模块了,当然有兴趣的同学也一样可以使用selenium去 ...
- [python] 常用正则表达式爬取网页信息及分析HTML标签总结【转】
[python] 常用正则表达式爬取网页信息及分析HTML标签总结 转http://blog.csdn.net/Eastmount/article/details/51082253 标签: pytho ...
- 使用python爬取MedSci上的期刊信息
使用python爬取medsci上的期刊信息,通过设定条件,然后获取相应的期刊的的影响因子排名,期刊名称,英文全称和影响因子.主要过程如下: 首先,通过分析网站http://www.medsci.cn ...
- 14-Requests+正则表达式爬取猫眼电影
'''Requests+正则表达式爬取猫眼电影TOP100''''''流程框架:抓去单页内容:利用requests请求目标站点,得到单个网页HTML代码,返回结果.正则表达式分析:根据HTML代码分析 ...
- C#爬取微博文字、图片、视频(不使用Cookie)
前两天在网上偶然看到一个大佬OmegaXYZ写的文章,Python爬取微博文字与图片(不使用Cookie) 于是就心血来潮,顺手撸一个C#版本的. 其实原理也很简单,现在网上大多数版本都需要Cooki ...
- Python爬取 | 唯美女生图片
这里只是代码展示,且复制后不能直接运行,需要配置一些设置才行,具体请查看下方链接介绍: Python爬取 | 唯美女生图片 from selenium import webdriver from fa ...
- python爬取某个网页的图片-如百度贴吧
python爬取某个网页的图片-如百度贴吧 作者:vpoet mail:vpoet_sir@163.com 注:随意copy,不用告诉我 #coding:utf-8 import urllib imp ...
- requests+正则表达式爬取ip
#requests+正则表达式爬取ip #findall方法,如果表达式中包含有子组,则会把子组单独返回出来,如果有多个子组,则会组合成元祖 import requests import re def ...
随机推荐
- 使用同步适配器(sync adapter)数据传输
在android设备与webserver之间实现数据同步能显著提高你的应用的有用性.让你的应用更受用户的欢迎. 比方说.你的数据上传给webserver,这就有了一个有用的备份.当用户的设备离线工作时 ...
- Mybatis 碰到的一些问题
1. SQL语句参数无法获取:nested exception is org.apache.ibatis.reflection.ReflectionException: There is no get ...
- Python 下的数据结构实现
既然采用了 Python 编程语言实现数据结构,就要充分发挥 Python 语言的语法特性. 参考<Python 算法教程><数据结构与算法 -- Python 语言描述>: ...
- B1821 [JSOI2010]Group 部落划分 Group 二分答案&&并查集
这个题正解是最小生成树,但是...最大值最小?一看就是二分答案啊!不用多想,直接二分答案加暴力验证就行了. 题干: Description 聪聪研究发现,荒岛野人总是过着群居的生活,但是,并不是整个荒 ...
- 常见文件MIME类型
常见文件MIME类型.asx,video/x-ms-asf .xml,text/xml .tsv,text/tab-separated-values .ra,audio/x-pn-realaudio ...
- NPM 国内镜像使用方法
npm官方站点: http://www.npmjs.org/ 本文使用国内镜像地址: http://www.cnpmjs.org/ 搜索镜像:https://npm.taobao.org/ 具体方法: ...
- Elasticsearch之curl删除索引库
关于curl创建索引库的介绍,请移步 Elasticsearch之curl创建索引库 [hadoop@djt002 elasticsearch-2.4.3]$ curl -XPUT 'http://1 ...
- 微信小程序特殊字符转义方法——&转义&等等
在我编写公司小程序的过程中,有一次在网页端添加了一张图片,结果在小程序端访问失败了,究其原因,竟然是因为该图片名称中有一个“&”符号,网页端添加后,自动转义成了“&”存储到了数据库.当 ...
- Spring Boot (13) druid监控
druid druid是和tomcat jdbc一样优秀的连接池,出自阿里巴巴.除了连接池,druid哈hi有一个很实用的监控功能. pom.xml 添加了以下依赖后,会自动用druid连接池替代默认 ...
- spring jdbc、事务(三)
spring整合jdbc spring中提供了一个可以操作数据库的对象(JDBCTemplate),对象封装了jdbc技术. 1.使用spring整合jdbc需要jdbc驱动.c3p0连接池.spri ...