Scrapy中的核心工作流程以及POST请求
五大核心组件工作流程
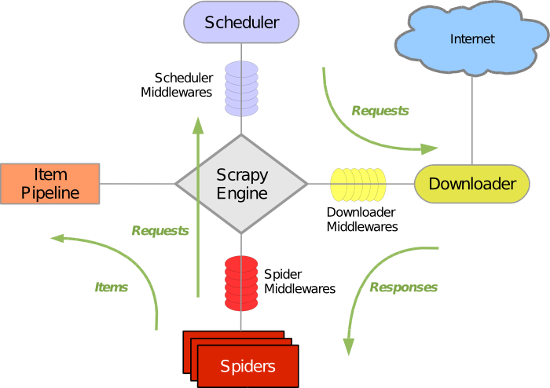
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
post请求发送
- 重写爬虫应用文件中继承Spider类的 类的里面的start_requests(self)这个方法
def start_requests(self):
#请求的url
post_url = 'http://fanyi.baidu.com/sug'
# post请求参数
formdata = {
'kw': 'wolf',
}
# 发送post请求
yield scrapy.FormRequest(url=post_url, formdata=formdata, callback=self.parse)
递归爬取
- 递归爬取解析多页页面数据
- 需求:将糗事百科所有页码的作者和段子内容数据进行爬取切持久化存储
- 需求分析:每一个页面对应一个url,则scrapy工程需要对每一个页码对应的url依次发起请求,然后通过对应的解析方法进行作者和段子内容的解析。
- 实现方案:
1.将每一个页码对应的url存放到爬虫文件的起始url列表(start_urls)中。(不推荐)
2.使用Request方法手动发起请求。(推荐)
- 代码:
# -*- coding: utf-8 -*-
import scrapy
from qiushibaike.items import QiushibaikeItem
# scrapy.http import Request
class QiushiSpider(scrapy.Spider):
name = 'qiushi'
allowed_domains = ['www.qiushibaike.com']
start_urls = ['https://www.qiushibaike.com/text/'] #爬取多页
pageNum = 1 #起始页码
url = 'https://www.qiushibaike.com/text/page/%s/' #每页的url def parse(self, response):
div_list=response.xpath('//*[@id="content-left"]/div')
for div in div_list:
#//*[@id="qiushi_tag_120996995"]/div[1]/a[2]/h2
author=div.xpath('.//div[@class="author clearfix"]//h2/text()').extract_first()
author=author.strip('\n')
content=div.xpath('.//div[@class="content"]/span/text()').extract_first()
content=content.strip('\n')
item=QiushibaikeItem()
item['author']=author
item['content']=content yield item #提交item到管道进行持久化 #爬取所有页码数据
if self.pageNum <= 13: #一共爬取13页(共13页)
self.pageNum += 1
url = format(self.url % self.pageNum) #递归爬取数据:callback参数的值为回调函数(将url请求后,得到的相应数据继续进行parse解析),递归调用parse函数
yield scrapy.Request(url=url,callback=self.parse)
Scrapy中的核心工作流程以及POST请求的更多相关文章
- Scrapy项目结构分析和工作流程
新建的空Scrapy项目: spiders目录: 负责存放继承自scrapy的爬虫类.里面主要是用于分析response并提取返回的item或者是下一个URL信息,每个Spider负责处理特定的网站或 ...
- scrapy核心组件工作流程和post请求
一 . 五大核心组件的工作流程 引擎(Scrapy)用来处理整个系统的数据流处理, 触发事务(框架核心) 调度器(Scheduler)用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返 ...
- Struts框架核心工作流程与原理
1.Struts2架构图 这是Struts2官方站点提供的Struts 2 的整体结构. 执行流程图 2.Struts2部分类介绍 这部分从Struts2参考文档中翻译就可以了. ActionM ...
- 分析Android中View的工作流程
在分析View的工作流程时,需要先分析一个很重要的类,MeasureSpec.这个类在View的测量(Measure)过程中会用到. MeasureSpec MeasureSpec是View的静态内部 ...
- C#中消息的工作流程
C#中的消息被Application类从应用程序消息队列中取出,然后分发到消息对应的窗体,窗体对象的第一个响应函数是对象中的protected override void WndProc(ref Sy ...
- Java中动态代理工作流程
当谈到动态代理就会想到接口,因为接口是一种规范,动态代理对象通过接口便会很清楚地知道他的实现类(被代理对象)是何种类型的(即有哪些方法).Now,然我们来开始编写一个例子来了解动态代理的全过程: 第一 ...
- SpringMVC第一篇【介绍、入门、工作流程、控制器】
什么是SpringMVC? SpringMVC是Spring家族的一员,Spring是将现在开发中流行的组件进行组合而成的一个框架!它用在基于MVC的表现层开发,类似于struts2框架 为什么要使用 ...
- cocos 资源工作流程
前面的话 本文将详细介绍 cocos 中的资源工作流程 概述 [同步性] 资源管理器中的资源和操作系统的文件管理器中看到的项目资源文件夹是同步的 在资源管理器中对资源的移动.重命名和删除,都会直接在用 ...
- RDIFramework.NET ━ .NET快速信息化系统开发框架 ━ 工作流程组件介绍
RDIFramework.NET ━ .NET快速信息化系统开发框架 工作流程组件介绍 RDIFramework.NET,基于.NET的快速信息化系统开发.整合框架,给用户和开发者最佳的.Net框架部 ...
随机推荐
- 编程领域中的 "transparent" 和 "opaque"
引言 在学习计算机的过程中,经常会接触到 “透明” 和 “非透明” 的概念. 刚开始理解 “透明” 这个概念的时候,认为 “透明” 就是程序员可以看见其中的构造,但是老师却说透明是程序员意识不到其中的 ...
- 模拟登录新浪微博(Python)
PC 登录新浪微博时, 在客户端用js预先对用户名.密码都进行了加密, 而且在POST之前会GET 一组参数,这也将作为POST_DATA 的一部分. 这样, 就不能用通常的那种简单方法来模拟POST ...
- C#第十四节课
函数的调用 using System;using System.Collections.Generic;using System.Linq;using System.Text;using System ...
- HAOI2010软件安装(树形背包)
HAOI2010软件安装(树形背包) 题意 有n个物品,每个物品最多会依赖一个物品,但一个物品可以依赖于一个不独立(依赖于其它物品)的物品,且可能有多个物品依赖一个物品,并且依赖关系可能形成一个环.现 ...
- python-flask-1
https://askubuntu.com/questions/244641/how-to-set-up-and-use-a-virtual-python-environment-in-ubuntu ...
- 天翼云 RDS数据库操作
1.RDS数据库创建好之后点击RDS实例管理找到已下信息 官方文档 -1:http://www.ctyun.cn/help/qslist/567 官方文档 -2:http://www.ctyun.cn ...
- id和class命名规范
- Intro.js 分步向导插件使用方法
简介 为您的网站和项目提供一步一步的.更好的介绍 Intro.js 目前兼容 Firefox.Chrome 和 IE8,不兼容 IE6 和 IE7,后续版本将会提供更好的兼容. 在线演示及下载 在线演 ...
- 强大的jQuery图片查看器插件Viewer.js
简介 Viewer.js 是一款强大的图片查看器 Viewer.js 有以下特点: 支持移动设备触摸事件 支持响应式 支持放大/缩小 支持旋转(类似微博的图片旋转) 支持水平/垂直翻转 支持图片移动 ...
- K大数查询
3110: [Zjoi2013]K大数查询 Time Limit: 20 Sec Memory Limit: 512 MB Description 有N个位置,M个操作.操作有两种,每次操作如果是1 ...