Scrapy项目结构分析和工作流程
新建的空Scrapy项目:

spiders目录: 负责存放继承自scrapy的爬虫类。里面主要是用于分析response并提取返回的item或者是下一个URL信息,每个Spider负责处理特定的网站或一些网站。
__init__.py: 项目的初始化文件。
items.py: 负责数据模型的建立,类似于实体类。定义我们所要爬取的信息的相关属性。Item对象是种容器,用来保存获取到的数据。
middlewares.py: 自己定义的中间件。可以定义相关的方法,用以处理蜘蛛的响应输入和请求输出。
pipelines.py: 负责对spider返回数据的处理。在item被Spider收集之后,就会将数据放入到item pipelines中,在这个组件是一个独立的类,他们接收到item并通过它执行一些行为,同时也会决定item是否能留在pipeline,或者被丢弃。
settings.py: 负责对整个爬虫的配置。提供了scrapy组件的方法,通过在此文件中的设置可以控制包括核心、插件、pipeline以及Spider组件。 scrapy.cfg: scrapy基础配置
scrapy 是一个为了爬取网站数据,提取结构性数据而编写的应用框架,我们只需要实现少量代码,就能够快速的抓取到数据内容。Scrapy 使用了 Twisted['twɪstɪd](其主要对手是Tornado)异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
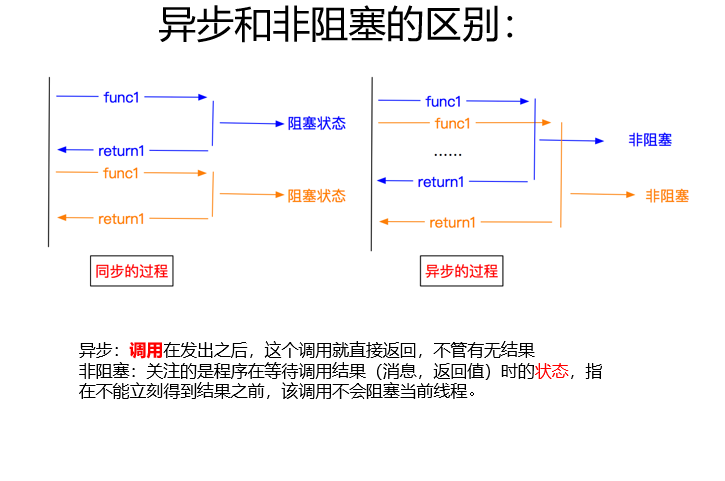
普通爬虫流程:

Scrapy工作流程
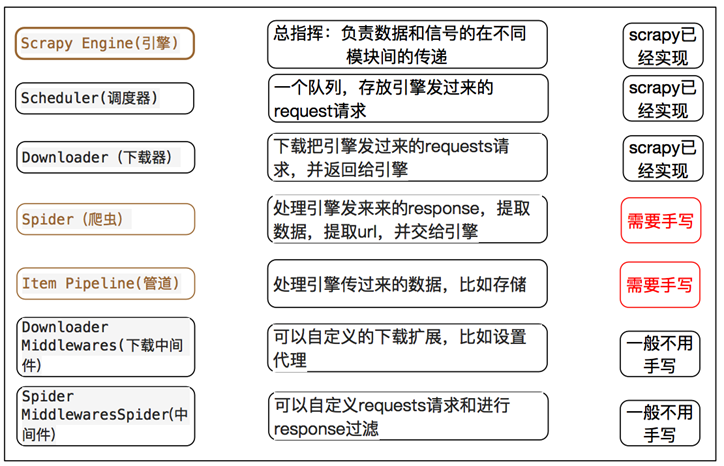
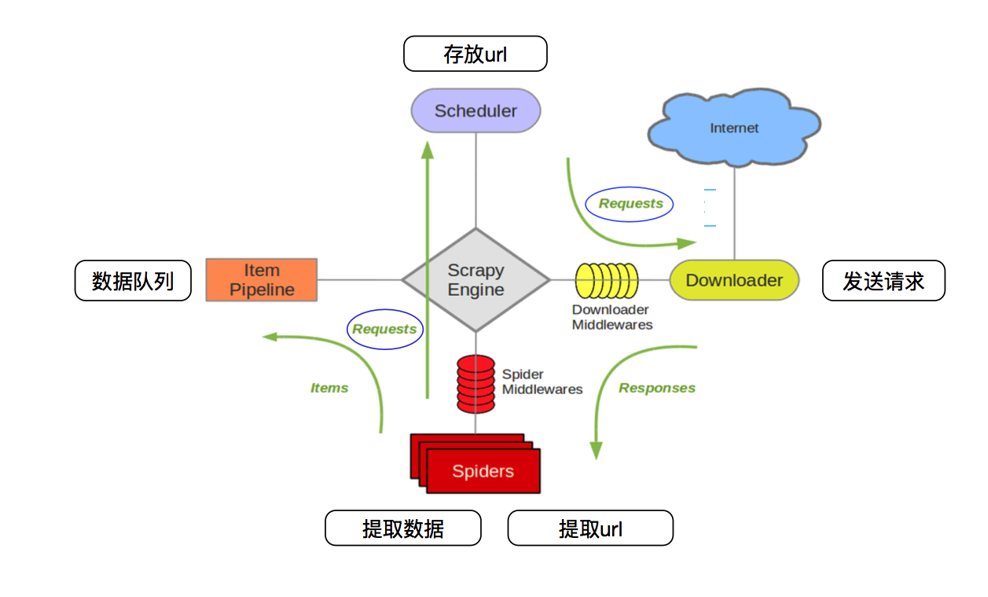
scrapy框架的工作流程:
1.首先Spiders(爬虫)将需要发送请求的url(requests)经ScrapyEngine(引擎)交给Scheduler(调度器)。
2.Scheduler(排序,入队)处理后,经ScrapyEngine,DownloaderMiddlewares(可选,主要有User_Agent, Proxy代理)交给Downloader。
3.Downloader向互联网发送请求,并接收下载响应(response)。将响应(response)经ScrapyEngine,SpiderMiddlewares(可选)交给Spiders。
4.Spiders处理response,提取数据并将数据经ScrapyEngine交给ItemPipeline保存(可以是本地,可以是数据库)。
提取url重新经ScrapyEngine交给Scheduler进行下一个循环。直到无Url请求程序停止结束。
scrapy爬虫框架之理解篇(个人理解)
Scrapy项目结构分析和工作流程的更多相关文章
- Scrapy中的核心工作流程以及POST请求
五大核心组件工作流程 post请求发送 递归爬取 五大核心组件工作流程 引擎(Scrapy)用来处理整个系统的数据流处理, 触发事务(框架核心) 调度器(Scheduler)用来接受引擎发过来的请求, ...
- YARN结构分析与工作流程
YARN Architecture Link: http://hadoop.apache.org/docs/r2.7.2/hadoop-yarn/hadoop-yarn-site/YARN.html ...
- CocosCreator资源工作流程
--摘自官方文档 资源工作流程 添加资源 资源管理器 提供了三种在项目中添加资源的方式: 通过 创建按钮 添加资源 在操作系统的文件管理器中,将资源文件复制到项目资源文件夹下,之后再打开或激活 Coc ...
- 【Git项目管理】分布式 Git - 分布式工作流程
分布式 Git - 分布式工作流程 你现在拥有了一个远程 Git 版本库,能为所有开发者共享代码提供服务,在一个本地工作流程下,你也已经熟悉了基本 Git 命令.你现在可以学习如何利用 Git 提供的 ...
- pip:带你认识一个 Python 开发工作流程中的重要工具
摘要:许多Python项目使用pip包管理器来管理它们的依赖项.它包含在Python安装程序中,是Python中依赖项管理的重要工具. 本文分享自华为云社区<使用Python的pip管理项目的依 ...
- scrapy核心组件工作流程和post请求
一 . 五大核心组件的工作流程 引擎(Scrapy)用来处理整个系统的数据流处理, 触发事务(框架核心) 调度器(Scheduler)用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返 ...
- 爬虫之scrapy工作流程
Scrapy是什么? scrapy 是一个为了爬取网站数据,提取结构性数据而编写的应用框架,我们只需要实现少量代码,就能够快速的抓取到数据内容.Scrapy 使用了 Twisted['twɪstɪd] ...
- Scrapy五大核心组件工作流程
一.Scrapy五大核心组件工作流程 1.核心组件 # 引擎(Scrapy) 对整个系统的数据流进行处理, 触发事务(框架核心). # 调度器(Scheduler) 用来接受引擎发过来的请求. 由过滤 ...
- J2EE进阶(六)SSH框架工作流程项目整合实例讲解
J2EE进阶(六)SSH框架工作流程项目整合实例讲解 请求流程 经过实际项目的进行,结合三大框架各自的运行机理可分析得出SSH整合框架的大致工作流程. 首先查看一下客户端的请求信息: 对于一个Web项 ...
随机推荐
- 【洛谷P1052【NOIP2005提高T2】】过河
题目描述 在河上有一座独木桥,一只青蛙想沿着独木桥从河的一侧跳到另一侧.在桥上有一些石子,青蛙很讨厌踩在这些石子上.由于桥的长度和青蛙一次跳过的距离都是正整数,我们可以把独木桥上青蛙可能到达的点看成数 ...
- [CQOI2011]放棋子 (DP,数论)
[CQOI2011]放棋子 \(solution:\) 看到这道题我们首先就应该想到有可能是DP和数论,因为题目已经很有特性了(首先题面是放棋子)(然后这一题方案数很多要取模)(而且这一题的数据范围很 ...
- mysql 架构 ~异地容灾
一 简介 我们来探讨下多机房下的mysql架构二 目的: 首先要清楚你的目的 1 实现异地机房的容灾备份 2 实现异地机房的双活 三 叙说 1 实现异地机房的容灾备份 ...
- JQuery中的$.getScript()、$.getJson()和$.ajax()方法
$.getScript() 有时候,在页面初次加载时就取得所需的全部JavaScript文件是完全没有必要的.虽然可以在需要哪个JavaScript文件时,动态地创建<script>标签, ...
- maven配置jdk1.8环境
<!-- 局部jdk配置,pom.xml中 --> <build> <plugins> <plugin> <groupId>org.apac ...
- 2018-2019-2 网络对抗技术 20165230 Exp6 信息搜集与漏洞扫描
目录 1.实验内容 2.实验过程 任务一:各种搜索技巧的应用 通过搜索引擎进行信息搜集 搜索网址目录结构 使用IP路由侦查工具traceroute 搜索特定类型的文件 任务二:DNS IP注册信息的查 ...
- UML入门[转]
访问权限控制 class Dummy { - private field1 # protected field2 ~ package method1() + public method2() } Al ...
- Linux安装后首次设置root密码
① 1.sudo password root //给指定用户设置密码 2.sudo passwd root //给指定用户设置密码 ②su root //切换到指定用户
- IAR拷贝工程后,修改工程名的方法
在实际使用过程中,经常基于某个demo进行开发,但是demo的项目名往往不满足新项目的名称,如果重新建立工程,就需要进行一系列的配置,非常麻烦,其实可以直接修改项目名,做法如下; 1. 修改项目目录下 ...
- svn的常用命令
svn :看log.版本库.增删.提交 (1)svn up //代码更新到最新版本. (2)svn checkout //将代码checkout出来. (3)svn revert -R ./ //将代 ...