第十一节:Web爬虫之数据存储(数据更新、删除、查询)
接着上一节的内容
5、MySQL数据更新
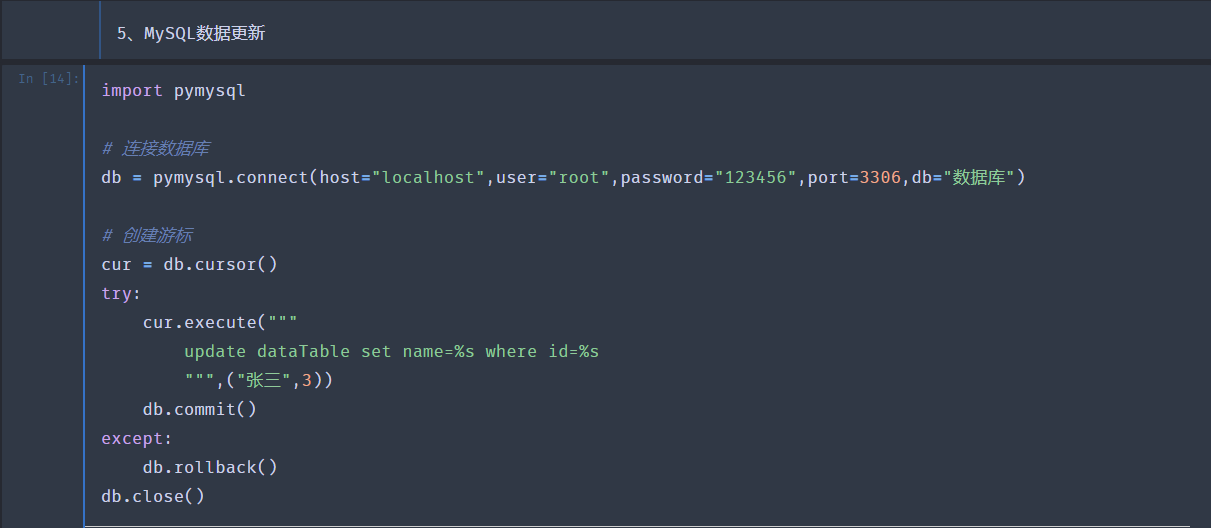
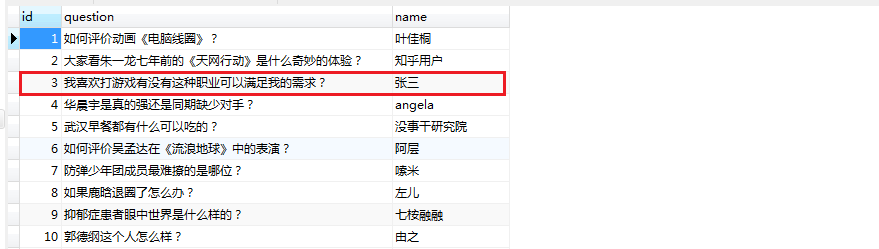
结果是将id=3的name进行更新操作,结果如下:
6、MySQL数据去重及更新
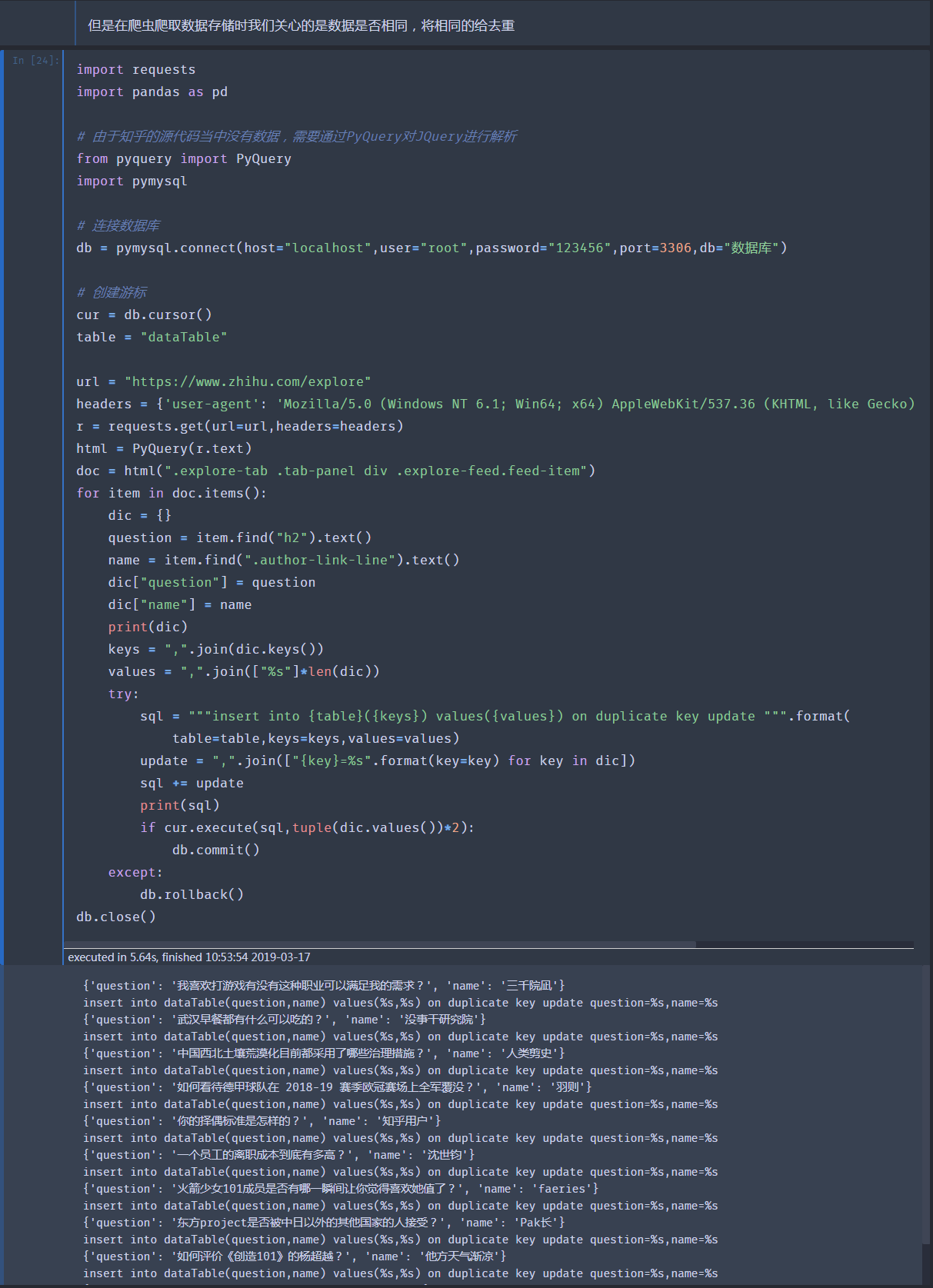
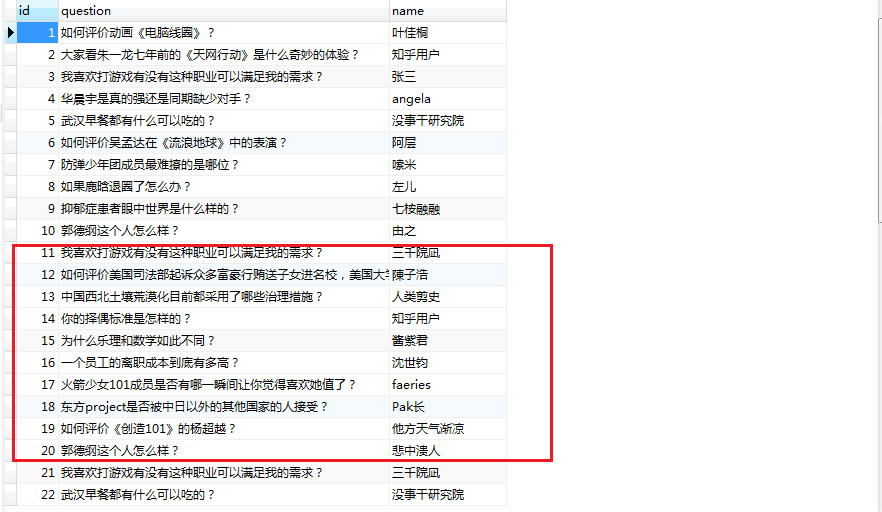
结果是判断数据是否有重复的,如果有重复的将不再存储,若没有重复的就更新数据进行插入操作,
最后两行数据与红色框起来的数据有相同的,故之存储了最后两行数据,结果如下:
7、MySQL数据删除
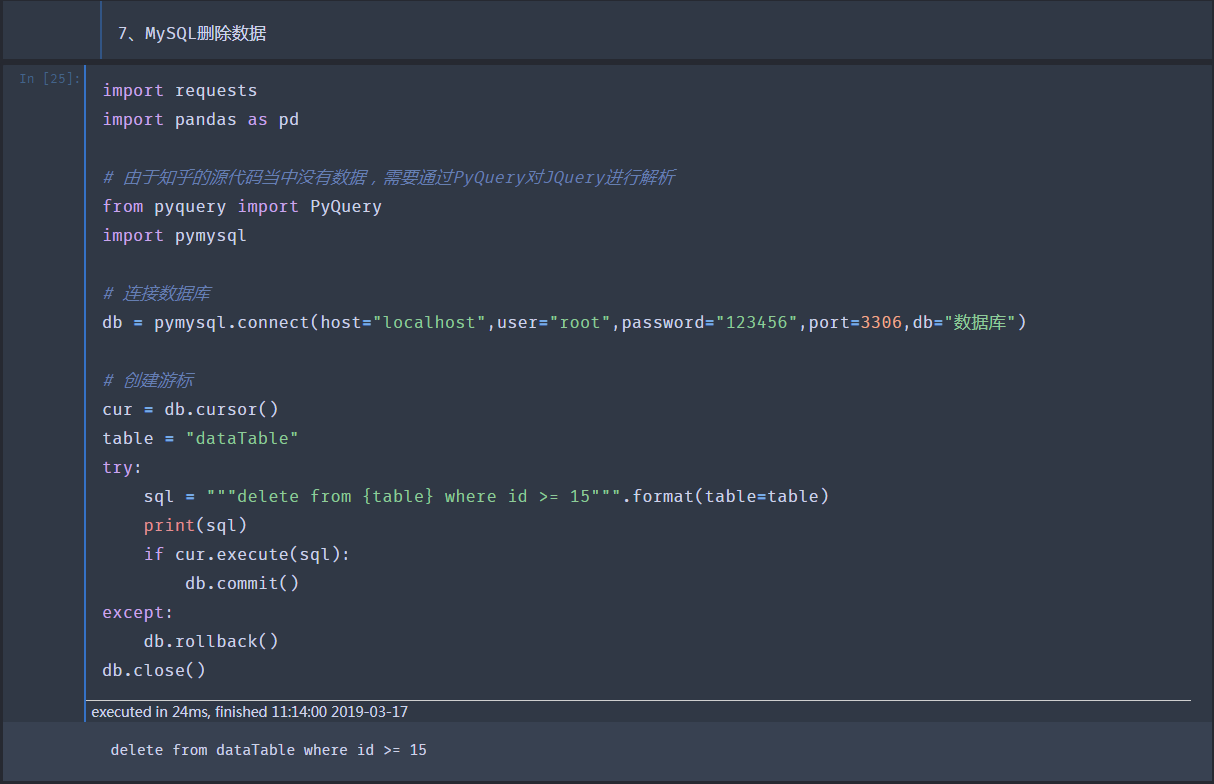
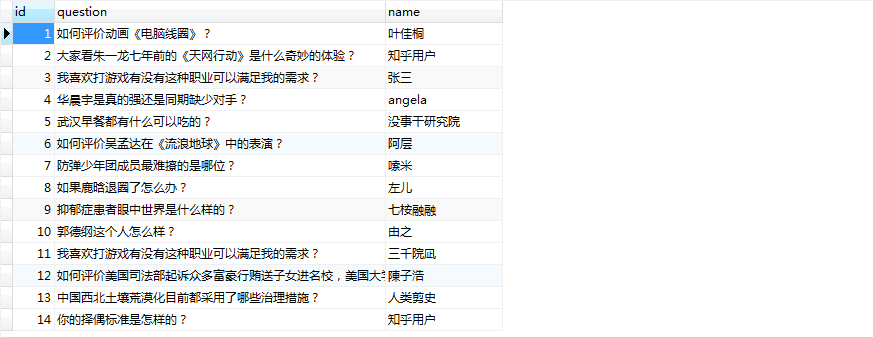
将id大于等于15的数据全部删去,结果如下
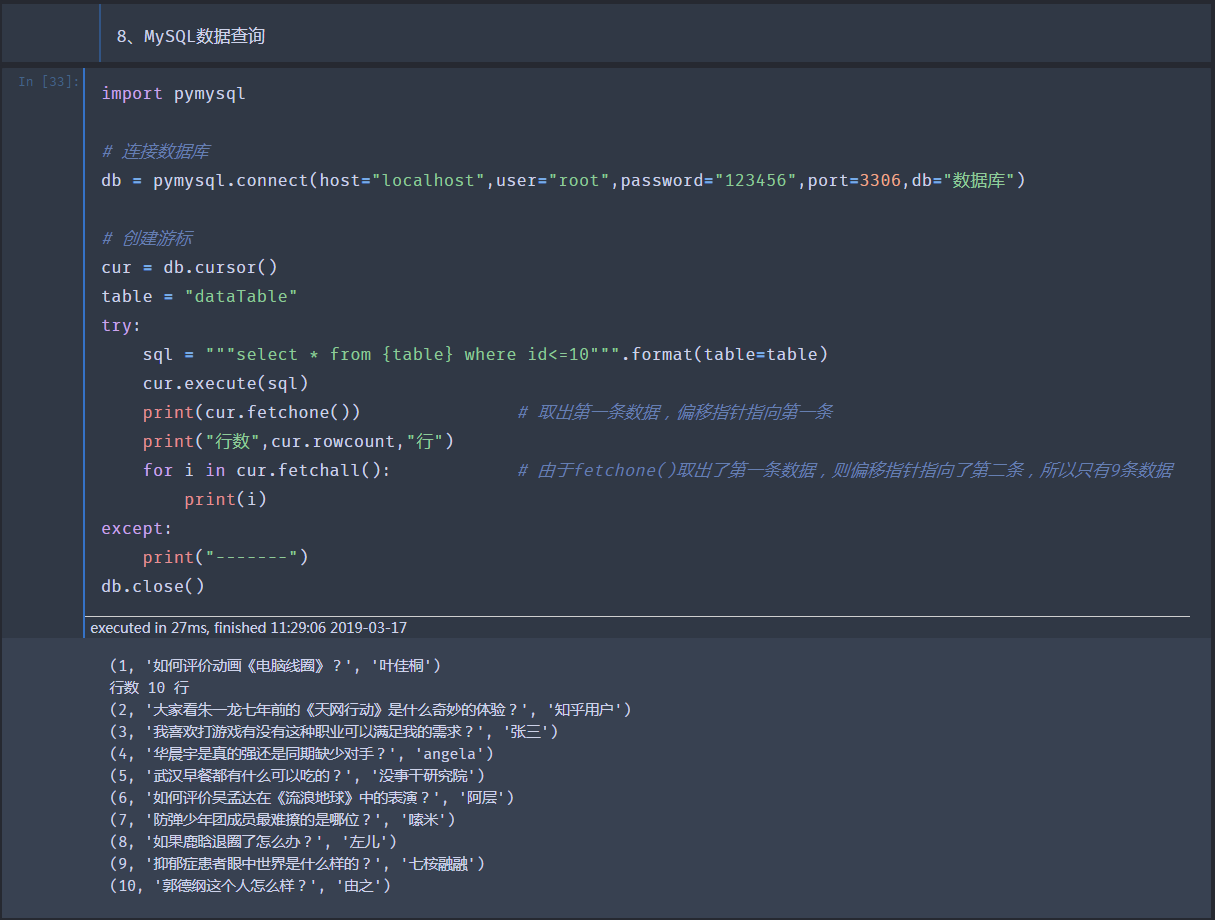
8、MySQL数据库查询
第十一节:Web爬虫之数据存储(数据更新、删除、查询)的更多相关文章
- 第十节:Web爬虫之数据存储与MySQL8.0数据库安装和数据插入
用解析器解析出数据之后,接下来就是存储数据了,保存的形式可以多种多样,最简单的形式是直接保存为文本文件,如 TXT.JSON.csv 另外,还可以保存到数据库中,如关系型数据库MySQL ,非关系型数 ...
- web sql database数据存储位置
Q1: 数据存储在哪儿? Web Storage / Web SQL Database / Indexed Database 的数据都存储在浏览器对应的用户配置文件目录(user profile di ...
- 爬虫实践——数据存储到Excel中
在进行爬虫实践时,我已经爬取到了我需要的信息,那么最后一个问题就是如何把我所爬到的数据存储到Excel中去,这是我没有学习过的知识. 如何解决这个问题,我选择先百度查找如何解决这个问题. 百度查到的方 ...
- Scrapy爬虫案例 | 数据存储至MySQL
首先,MySQL创建好数据库和表 然后编写各个模块 item.py import scrapy class JianliItem(scrapy.Item): name = scrapy.Field() ...
- Hibernate学习---第十一节:Hibernate之数据抓取策略&批量抓取
1.hibernate 也可以通过标准的 SQL 进行查询 (1).将SQL查询写在 java 代码中 /** * 查询所有 */ @Test public void testQuery(){ // ...
- Scrapy爬虫案例 | 数据存储至MongoDB
豆瓣电影TOP 250网址 要求: 1.爬取豆瓣top 250电影名字.演员列表.评分和简介 2.设置随机UserAgent和Proxy 3.爬取到的数据保存到MongoDB数据库 items.py ...
- Android笔记(四十一) Android中的数据存储——SQLite(三)select
SQLite 通过query实现查询,它通过一系列参数来定义查询条件. 各参数说明: query()方法参数 对应sql部分 描述 table from table_name 表名称 colums s ...
- Python3编写网络爬虫12-数据存储方式五-非关系型数据库存储
非关系型数据库存储 NoSQL 全称 Not Only SQL 意为非SQL 泛指非关系型数据库.基于键值对 不需要经过SQL层解析 数据之间没有耦合性 性能非常高. 非关系型数据库可细分如下: 键值 ...
- python5数据存储
1 txt文件存储 正常调用文件python文件操作 https://www.cnblogs.com/x2x3/p/9979919.html 2 json文件存储 在JavaScript语言中,一切都 ...
随机推荐
- bzoj 1370 Gang团伙
题目大意: 在某城市里住着n个人,任何两个认识的人不是朋友就是敌人,满足 1. 我朋友的朋友是我的朋友 2. 我敌人的敌人是我的朋友 所有是朋友的人组成一个团伙 告诉你关于这n个人的m条信息,即某两个 ...
- 10 探索其他Excel对象
10.1 产生一个好的第一印象 10.1.1 为我们的世界着色 rgb(red:=[0,225],green:=[0,225],blue:=[0,225]) 此函数生成一个表示颜色的整数.VBA预定义 ...
- SVN报错 Not Found In Revision 不支持空目录
如果你要初始化上传的SVN目录为空,有可能会报这个错误 解决方法:在SVN下新建一个目录即可
- bzoj 1755: [Usaco2005 qua]Bank Interest【模拟】
原来强行转int可以避免四舍五入啊 #include<iostream> #include<cstdio> using namespace std; int r,y; doub ...
- robotframework - 框架做接口自动化get请求
1.做get请求之前先安装 Request库,参考github上链接 :https://github.com/bulkan/robotframework-requests/#readme 2.请求&a ...
- 略微讲讲最近的 webpack 该如何加快编译
首先假设 基础的环境是有 creat-react-app 所创建的 即所有基础的loader,插件的 cache 都已经缓存了 在这种情况下想加速,真是很难 不过,有一个插件是可以观察 各个模块所花的 ...
- Kafka详解与总结(六)
索引 稀疏存储,每隔一定字节的数据建立一条索引(这样的目的是为了减少索引文件的大小). 下图为一个partition的索引示意图: 注: 现在对6.和8建立了索引,如果要查找7,则会先查找到8然后,再 ...
- open_basedir 报错
Warning: require(): open_basedir restriction in effect. File(/home/www/blog/vendor/autoload.php) is ...
- linux学习之路4 系统目录架构
linux树状文件系统结构 bin(binary) 保存可执行文件 也就是保存所有命令 boot 引导目录 保存所有跟系统有关的引导程序 其中Vmlinux文件最为重要,是系统内核 dev 保存所有的 ...
- NodeJs学习记录(三)vscode下启动一个nodejs的web工程
2017/01/23 星期一 前言:根据手上现成的一个web工程来学习 1.配置vscode使其可以识别nodejs的页面文件.ejs 2.先把项目拖拽至vscode的编辑界面,在"查看&q ...