2023/3/21 组会:ChatGPT 对数据增强的影响及 ChatGPT 的鲁棒性,Dense 和 Document 检索方法
前两个也许跟上了,后两个完全没跟上,以后再详细读读吧qwq
反正组会跟不上才是正常现象。
AugGPT: Leveraging ChatGPT for Text Data Augmentation
摘要、引言、相关工作
当下数据增强两个缺陷
- 真实性不足,有的跟原始 label 有偏移
- 生成的数据缺乏紧凑性
利用 ChatGPT 改进先前的数据增强方法
FSL(few shot learning):
- 下游上只有 1-2 个样本
RW
数据增强方法:
- character level
- OCR 这种自带的缺陷做数据增强,比如 O -> 0
- word level
- 随机替换、反转、删除
- 同义词替换
- contextual
- 利用预训练模型本身自有的知识做数据增强
- sequence
- 翻译过去再翻译回来
模型
AugGPT 的框架
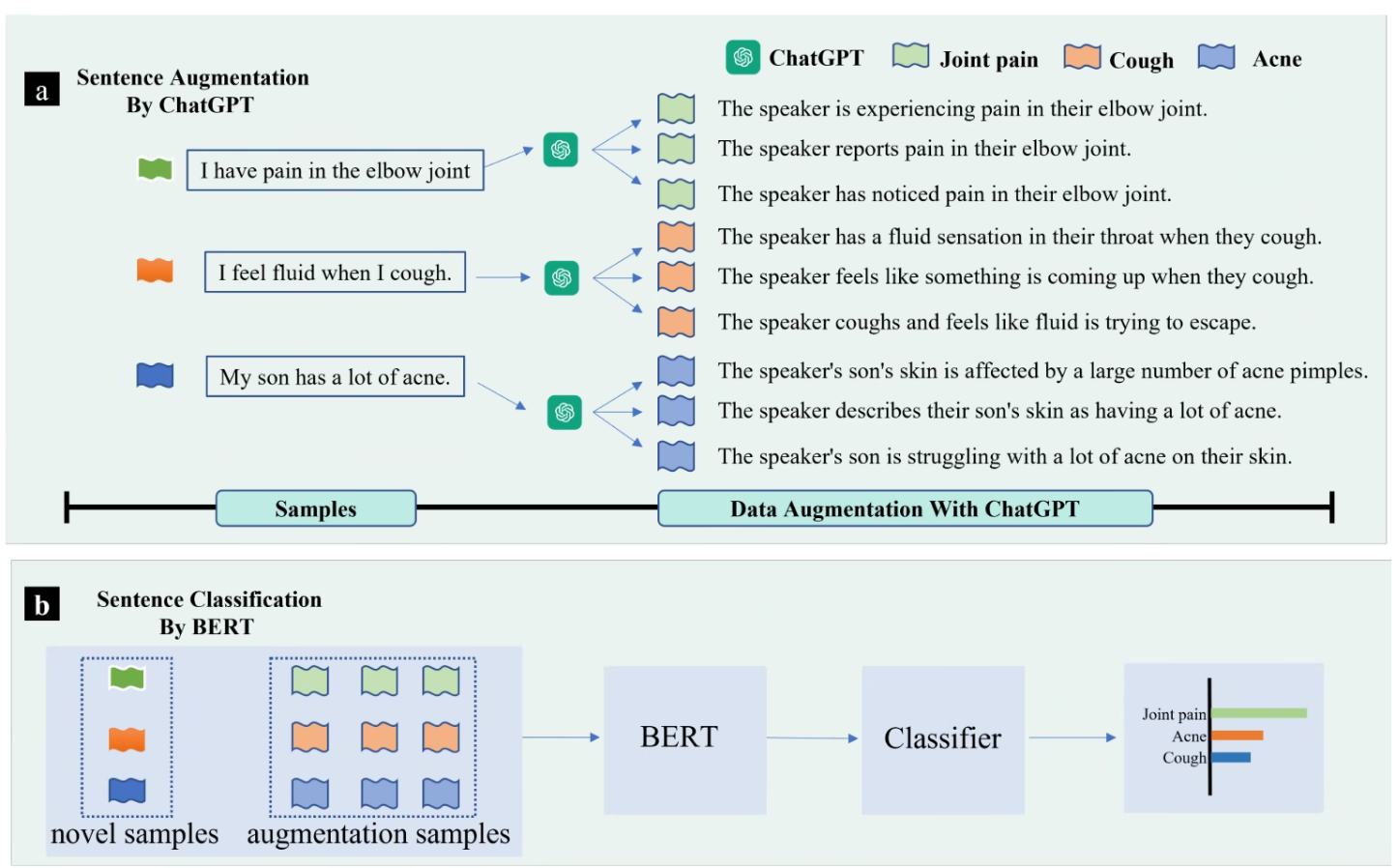
- 把原始的话输入 ChatGPT 中,然后让它改写。
- BERT 做 mask 的预测

Loss
做了对比损失
实验
数据集
- Amazon dataset:24 类,分类
- Symptoms Dataset:分类症状
- PubMed20k Dataset:分类
指标
- 余弦相似度
- 跟 BERT 类似,把 [CLS] 取出来,然后比较余弦相似度
- 信息熵相关的某个指标(Transrate)
结果
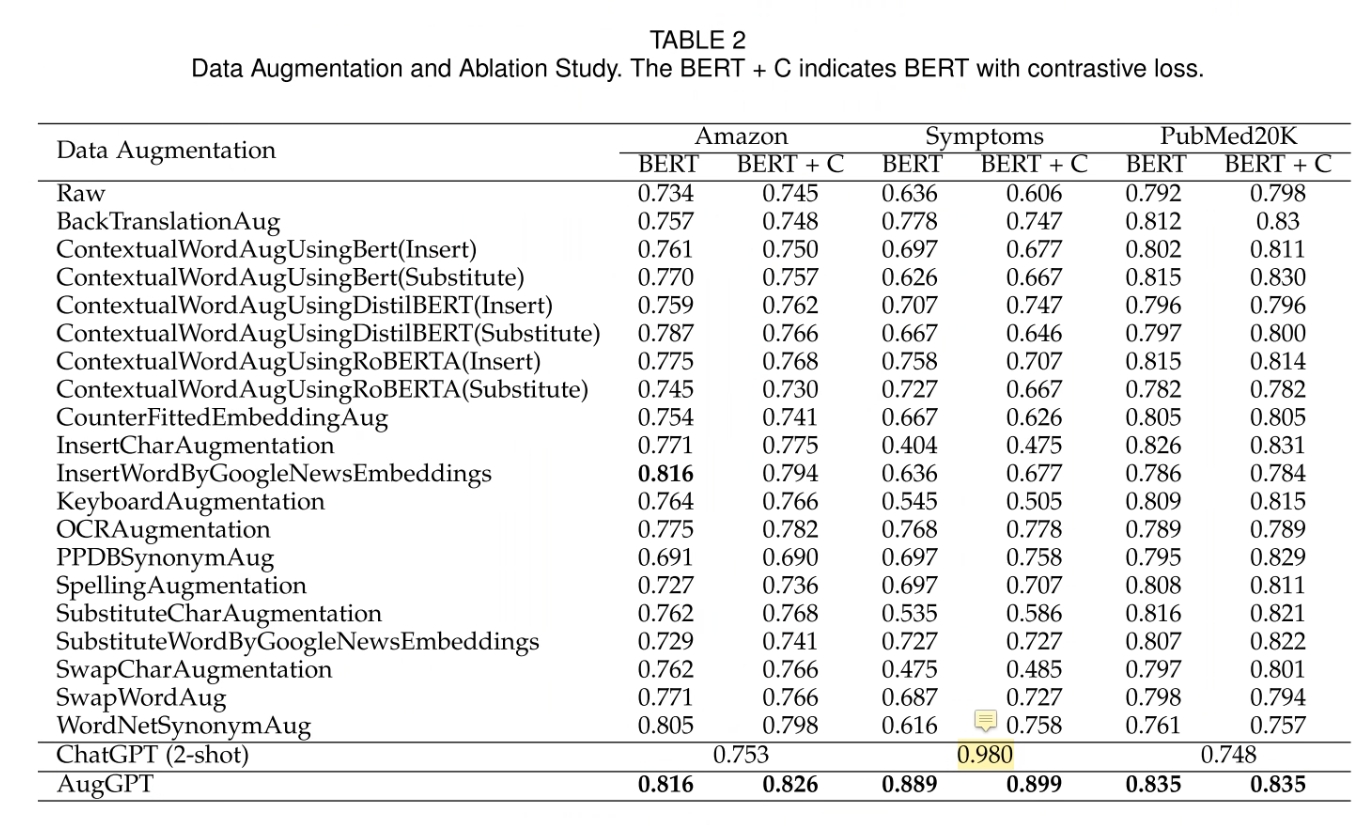
ChatGPT 在 Symptoms 上取得了爆炸的效果(我估计是练过),作者认为是这个数据集比较简单
prompt design
On the Robustness of ChatGPT: An Adversarial and Out-of-distribution Perspective
摘要、引言、相关工作
鲁棒性是可解释性的一个指标,因此本文从对抗和 OOD(这个 OOD 只能拿 22 年以后数据的测试)做分析。
例如,尝试用虚假新闻骗过 ChatGPT。
9 个任务,超过 2089 个样本上分析。
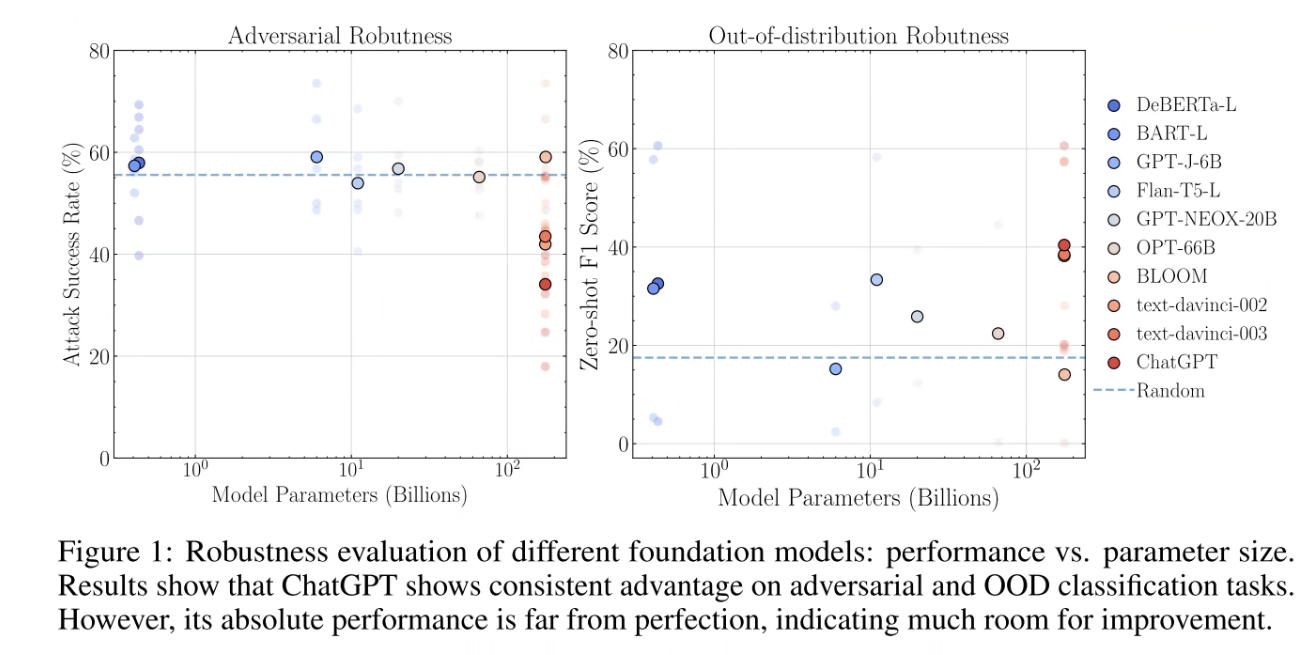
ChatGPT 在 Adverseral 和 OOD 上都优于先前的模型。
- ChatGPT 在哪些方面做的好
- ChatGPT 翻译任务上表现比较好
- ChatGPT 在 Adverseral 和 OOD 上都比较好
- 对话表现好
- 表现不好:
- ChatGPT 和人类认为它的水平有差距
- 翻译任务上不如 text-davinci-003
- ChatGPT 对于医学领域相关的问题无法给出确定答案,只能给出一些建议。
模型
两个任务的目标函数

实验
数据集
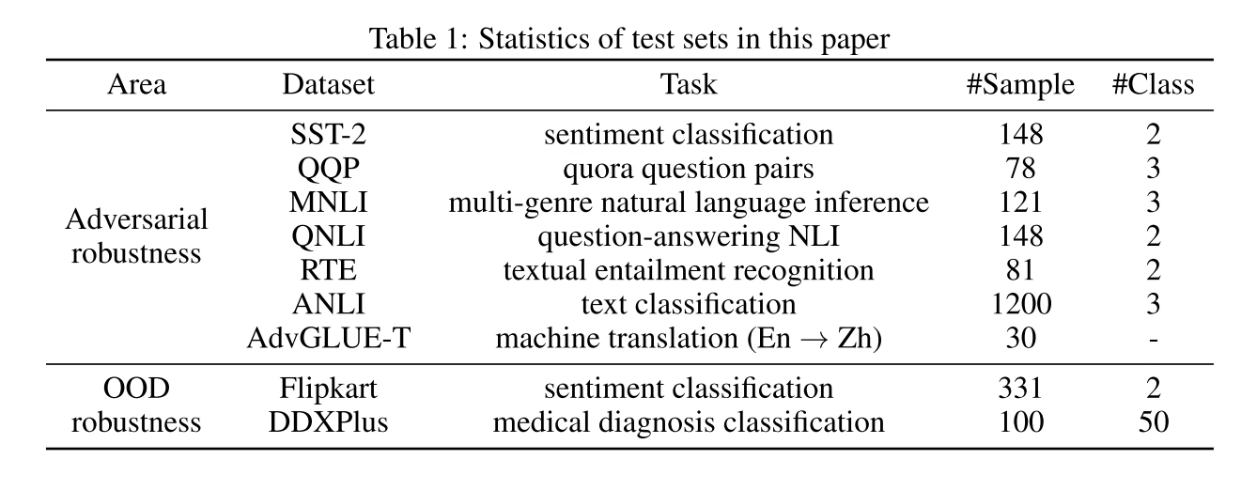
结果
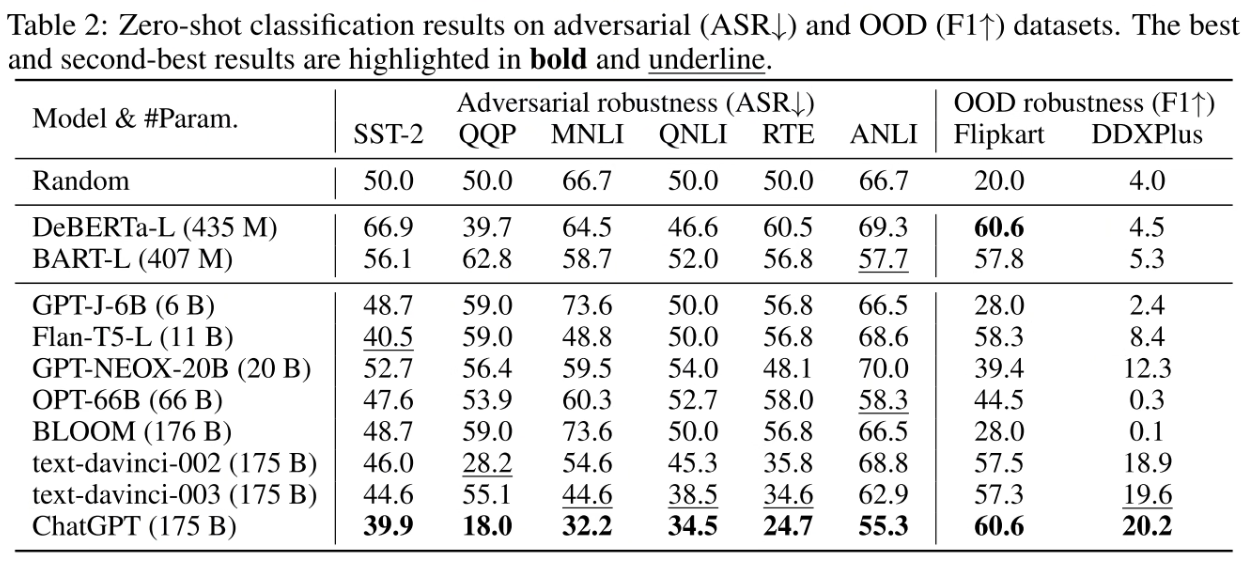
ChatGPT 表现最好
- ChatGPT 在对抗数据集上都表现很好
- 所有 GPT-2 这一系列的模型都在 OOD 数据集上表现很好
- ChatGPT 比较其他的大模型在基于对话的理解上表现更好
Dense Passage Retrieval for Open-Domain Question Answering
摘要、引言、相关工作
- Sparse Retrieval
- Dense Retrieval
- 自回归检索(Autoregressive retrieval)

作者提问:是否可以只用(问题,文章)对在没有额外的与训练是训练一个更好的 dense 潜入模型?
模型
Loss
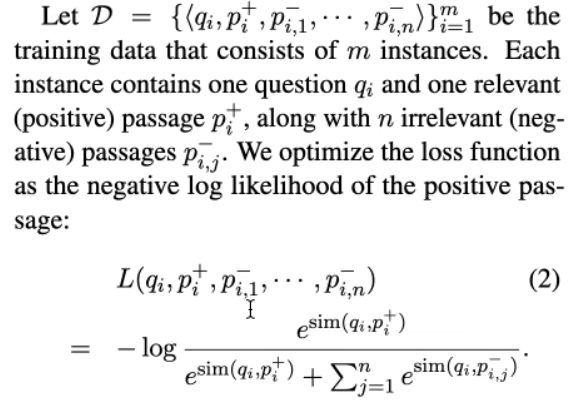
以下有几种负例构建方式:
- 随机从语料库中选负例
- BM25 找出来不包括答案但是匹配大多数问题词元的负例
- Gold:与训练集中出现的其他问题配对的积极段落
实验
结果
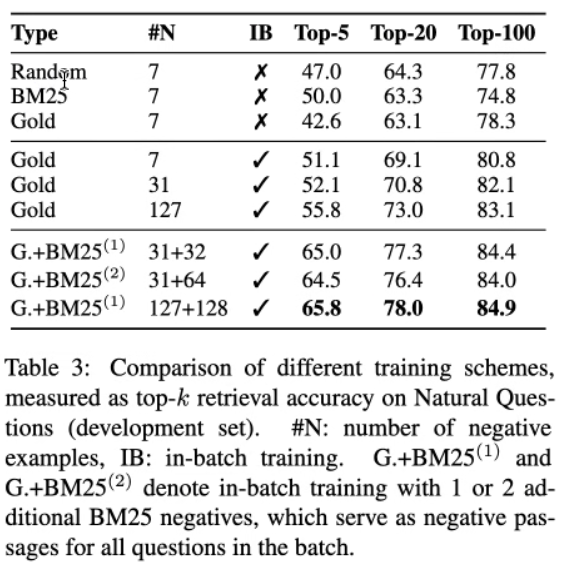
负例越多,效果可能越好
A Neural Corpus Indexer for Document Retrieval
据说本篇有很大争议
摘要、引言、相关工作
作者认为:
- dense retrieval 和 term-based retrieval 都没有办法充分利用神经网络的能力。
- 模型不能合成深度的 查询-文档 交互。
模型
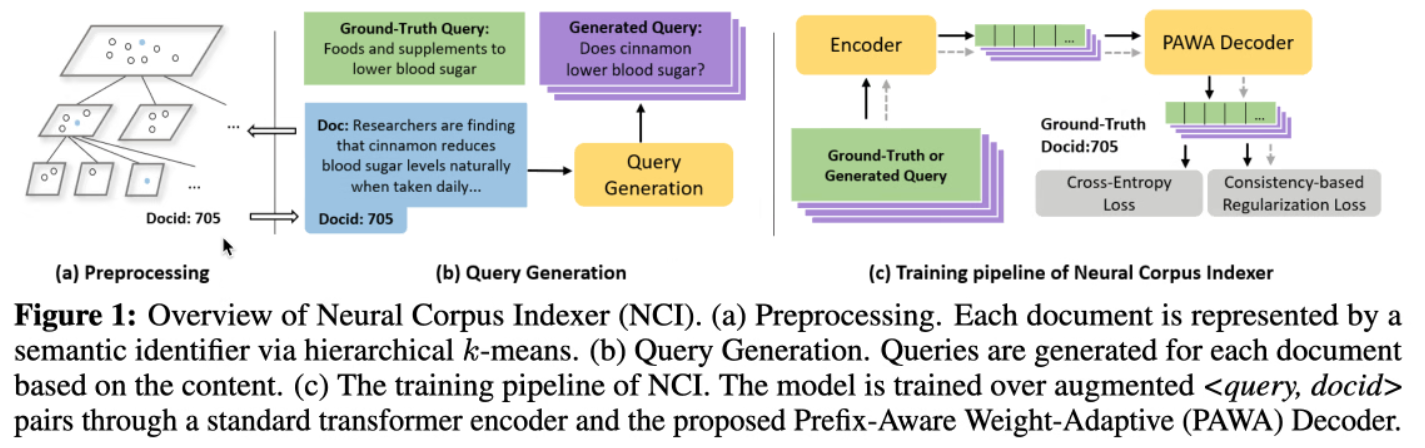
实验
后面跟不上了
2023/3/21 组会:ChatGPT 对数据增强的影响及 ChatGPT 的鲁棒性,Dense 和 Document 检索方法的更多相关文章
- SQL Server里在文件组间如何移动数据?
平常我不知道被问了几次这样的问题:“SQL Server里在文件组间如何移动数据?“你意识到这个问题:你只有一个主文件组的默认配置,后来围观了“SQL Server里的文件和文件组”后,你知道,有多 ...
- 将如下三组不同类型的数据利用DataInputStream和DataOutputStream写入文件,然后从文件中读出
三组数据如下: {19.99 , 9.99 , 15.99 , 3.99 , 4.99} {12 , 8 , 13 ,29 ,50} {"Java T-shirt" , " ...
- SQL分组排序后取每组最新一条数据的另一种思路
在hibernate框架和mysql.oracle两种数据库兼容的项目中实现查询每个id最新更新的一条数据. 之前工作中一直用的mybatis+oracle数据库这种,一般写这类分组排序取每组最新一条 ...
- 国内“谁”能实现chatgpt,短期穷出的类ChatGPT简评(算法侧角度为主),以及对MOSS、ChatYuan给出简评,一文带你深入了解宏观技术路线。
1.ChatGPT简介[核心技术.技术局限] ChatGPT(全名:Chat Generative Pre-trained Transformer),美国OpenAI 研发的聊天机器人程序 ,于202 ...
- (转)如何用TensorLayer做目标检测的数据增强
数据增强在机器学习中的作用不言而喻.和图片分类的数据增强不同,训练目标检测模型的数据增强在对图像做处理时,还需要对图片中每个目标的坐标做相应的处理.此外,位移.裁剪等操作还有可能使得一些目标在处理后只 ...
- HLJU 1046: 钓鱼(数据增强版) (贪心+优化)
1046: 钓鱼(数据增强版) Time Limit: 1 Sec Memory Limit: 128 MB Submit: 11 Solved: 3 [id=1046">Subm ...
- Deep Learning -- 数据增强
数据增强 在图像的深度学习中,为了丰富图像训练集,更好的提取图像特征,泛化模型(防止模型过拟合),一般都会对数据图像进行数据增强,数据增强,常用的方式,就是旋转图像,剪切图像,改变图像色差,扭曲图像特 ...
- Generalizing from a Few Examples: A Survey on Few-Shot Learning 小样本学习最新综述 | 三大数据增强方法
目录 原文链接:小样本学习与智能前沿 01 Transforming Samples from Dtrain 02 Transforming Samples from a Weakly Labeled ...
- ChatGPT国内镜像模板,国内使用ChatGPT中文版本
@ 目录 一.什么是ChatGPT国内镜像 二.ChatGPT国内镜像使用教程 免费ChatGPT镜像的功能: 三.ChatGPT中文版作用 四.怎么使用ChatGPT国内镜像 五.中文ChatGPT ...
- PCTUSED和PCTFREE对数据操作的影响
1概念理解 首先PCTUSED和PCTFREE都是针对数据块的存储属性,单位都是%.其中PCTFREE决定了数据块什么时候从free list中移除,系统就不可以再往该数据块中插入数据,对于数据块中已 ...
随机推荐
- dotnet OpenXML 读取 PPT 内嵌 xlsx 格式 Excel 表格的信息
在 Office 中,可以在 PPT 里面插入表格,插入表格有好多不同的方法,对应 OpenXML 文档存储的更多不同的方式.本文来介绍如何读取 PPT 内嵌 xlsx 格式的表格的方法 读取方法和 ...
- Uncaught (in promise) NavigationDuplicated: Avoided redundant navigation to current location: "/xxx". at createRouterError 的说明和解决
错误说明 Uncaught (in promise) NavigationDuplicated: Avoided redundant navigation to current location: & ...
- 深入理解Python协程:从基础到实战
title: 深入理解Python协程:从基础到实战 date: 2024/4/27 16:48:43 updated: 2024/4/27 16:48:43 categories: 后端开发 tag ...
- 在网页上直接运行Win11,5秒内用AI克隆自己的声音 | 蛮三刀酱的Github周刊第二期
大家好,这里是每周更新的Github精彩分享周刊,我是每周都在搬砖的蛮三刀酱. 我会从Github热门趋势榜里选出 高质量.有趣,牛B 的开源项目进行分享. 1. PowerShell:不止于Wind ...
- B/S 结构系统的 缓存机制(Cookie) 以及基于 cookie 机制实现 oa 十天免登录的功能
B/S 结构系统的 缓存机制(Cookie) 以及基于 cookie 机制实现 oa 十天免登录的功能 @ 目录 B/S 结构系统的 缓存机制(Cookie) 以及基于 cookie 机制实现 oa ...
- Solution - AGC060C
Link 简要题意:称一个长为 \(2^n-1\) 的排列 \(P\) 像堆,如果 \(P_i \lt P_{2i}\),且 \(P_i \lt P_{2i+1}\).给定 \(a,b\),设 \(u ...
- 使用openvp*-gui客户端连接多服务端,作为Windows服务部署
背景 多数公司都会用到VPN隧道技术链接服务器,保证服务器的安全,但多数情况下会存在多服务端的情况,这时就有客户端连接多个服务端的必要了,如果每次都要切换配置的话,对于有强迫症的兄弟当然忍不了了 思考 ...
- 免费的visual studio智能代码插件——CodeGeeX
CodeGeeX是什么?什么是CodeGeeX? CodeGeeX是一款基于大模型的智能编程助手,它可以实现代码的生成与补全,自动为代码添加注释,不同编程语言的代码间实现互译,针对技术和代码问题的智能 ...
- 【OpenVINO™】使用OpenVINO™ C# API 部署 YOLO-World实现实时开放词汇对象检测
YOLO-World是一个融合了实时目标检测与增强现实(AR)技术的创新平台,旨在将现实世界与数字世界无缝对接.该平台以YOLO(You Only Look Once)算法为核心,实现了对视频中物体的 ...
- 3种方法实现图片瀑布流的效果(纯JS,Jquery,CSS)
最近在慕课网上听如何实现瀑布流的效果:介绍了3种方法. 1.纯JS代码实现: HTML代码部分: <!DOCTYPE html> <html> <head> < ...