Hive 2.3.2安装
一、安装mysql
- 安装MySQL服务器端和MySQL客户端;
•安装:
– yum install mysql
– yum install mysql-server
•启动:
– /etc/init.d/mysqld start
进入mysql:

5)给mysql的user用户表添加一个user 其中host为%允许任何ip访问,密码同上即可,添加语句如下:
5.1) update user set password = password(‘root’) where user = ‘root’;
5.2) GRANT ALL PRIVILEGES ON . TO ‘root’@’%’ IDENTIFIED BY ‘root’ WITH GRANT OPTION;
5.3) flush privileges;

6、mysql中表的中文乱码问题:
创建表结构:
create table userinfo(
uid int primary key auto_increment,
username varchar(20)
)engine=InnoDB DEFAULT CHARSET=utf8;
insert into userinfo(username)values('测试');
1)检查内部的编码:SHOW VARIABLES LIKE ‘character_set_%’;

SHOW VARIABLES LIKE ‘collation_%’;

2)修改编码:SET NAMES ‘utf8’;

效果如下:

二、安装Hive
1、下载、解压hive、在hive/conf 下 新建hive-site.xml,进行如下配置
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
以下可选配置,该配置信息用来指定 Hive 数据仓库的数据存储在 HDFS 上的目录
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/hive/warehouse</value>
<description>hive default warehouse, if nessecory, change it</description>
</property>
2、在环境变量配置HIVE_HOME,并且让环境变量生效
source /etc/profile
三、安装MySQL链接工具
1、下载、解压
https://cdn.mysql.com//Downloads/Connector-J/mysql-connector-java-5.1.47.tar.gz
2、复制数据库驱动到 hive的lib下
cp mysql-connector-java-5.1.47-bin.jar /home/bigdata/apache-hive-1.2.2-bin/lib
3、更新jline.jar包
cp jline-2.12.1.jar /home/bigdata/hadoop/share/hadoop/yarn/lib/
四、初始化元数据库(hive2.x之后必须手动初始化)
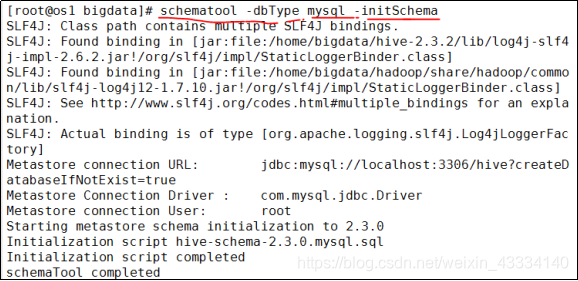
schematool -dbType mysql -initSchema
五、启动Hive (提前启动hdfs、mysql)
1、hive
2、hive --service cli

3、HiveServer2/beeline
3.1)修改hadoop的hdfs.site.xml文件:
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
3.2)修改hadoop集群的core-site.xml配置文件
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
配置解析:
hadoop.proxyuser.hadoop.hosts 配置成*的意义,表示任意节点使用 hadoop 集群的代理用户 root 都能访问 hdfs 集群,hadoop.proxyuser.hadoop.groups 表示代理用户的组所属
( 如果代理用户的组所属tong 则修改为:hadoop.proxyuser.tong.hosts
hadoop.proxyuser.tong.groups )
注意:启动之前,先启动hdfs,再启动hiveserver2,再beeline
3.3.1)先启动hiveserver2服务,启动后会多个【RunJar】进程

3.3.2)启动为后台:
nohup hiveserver2 1>/home/bigdata/hadoop/hiveserver.log 2>/home/bigdata/hadoop/hiveserver.err &
与地址有关系:
nohup hiveserver2 1>/opt/hadoop-2.7.5/hiveserver.log 2>/opt/hadoop-2.7.5/hiveserver.err &
//查看job hadoop job -list

解释:
1:表示标准日志输出
2:表示错误日志输出 如果我没有配置日志的输出路径,日志会生成在当前工作目录,
默认的日志名称叫做: nohup.xxx
PS:nohup 命令:如果你正在运行一个进程,而且你觉得在退出帐户时该进程还不会结束, 那么可以使用 nohup 命令。
该命令可以在你退出帐户/关闭终端之后继续运行相应的进程。 nohup 就是不挂起的意思(no hang up)。 该命令的一般
形式为:nohup command &
3.3.3) 启动beeline 客户端去连接
beeline -u jdbc:hive2//os1:10000 -n root
注意:u : 指定元数据库的链接信息 -n : 指定用户名和密码
3.3.4) 启动beeline ,然后输出!connect jdbc:hive2://os1:10000,输入用户名和密码
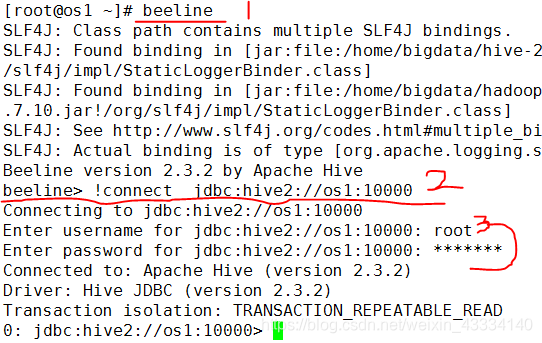
下面可以做hive操作。
Hive 2.3.2安装的更多相关文章
- Hive的三种安装方式(内嵌模式,本地模式远程模式)
一.安装模式介绍: Hive官网上介绍了Hive的3种安装方式,分别对应不同的应用场景. 1.内嵌模式(元数据保村在内嵌的derby种,允许一个会话链接,尝试多个会话链接时会报错) ...
- Hive学习之一 《Hive的介绍和安装》
一.什么是Hive Hive是建立在 Hadoop 上的数据仓库基础构架.它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储.查询和分析存储在 Hadoop 中的大规模数据 ...
- Hive基础概念、安装部署与基本使用
1. Hive简介 1.1 什么是Hive Hives是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能. 1.2 为什么使用Hive ① 直接使用 ...
- Hive/Hbase/Sqoop的安装教程
Hive/Hbase/Sqoop的安装教程 HIVE INSTALL 1.下载安装包:https://mirrors.tuna.tsinghua.edu.cn/apache/hive/hive-2.3 ...
- Hive 2.1.1安装配置
##前期工作 安装JDK 安装Hadoop 安装MySQL ##安装Hive ###下载Hive安装包 可以从 Apache 其中一个镜像站点中下载最新稳定版的 Hive, apache-hive-2 ...
- Hive的介绍及安装
简介 Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件 映射为一张数据库表,并提供类 SQL 查询功能. 本质是将 SQL 转换为 MapReduce 程序. Hive组件 ...
- HIVE 2.1.0 安装教程。(数据源mysql)
前期工作 安装JDK 安装Hadoop 安装MySQL 安装Hive 下载Hive安装包 可以从 Apache 其中一个镜像站点中下载最新稳定版的 Hive, apache-hive-2.1.0-bi ...
- Mac OSX系统中Hadoop / Hive 与 spark 的安装与配置 环境搭建 记录
Mac OSX系统中Hadoop / Hive 与 spark 的安装与配置 环境搭建 记录 Hadoop 2.6 的安装与配置(伪分布式) 下载并解压缩 配置 .bash_profile : ...
- Hive详解(02) - Hive 3.1.2安装
Hive详解(02) - Hive 3.1.2安装 安装准备 Hive下载地址 Hive官网地址:http://hive.apache.org/ 官方文档查看地址:https://cwiki.apac ...
- Hive[1] 初识 及 安装
本文前提是Hadoop & Java & mysql 数据库,已经安装配置好,并且 环境变量均已经配置到位 声明:本笔记参照 学习<Hive 编程指南>而来,如果有错误 ...
随机推荐
- Vue 基于vue-codemirror实现的代码编辑器
基于vue-codemirror实现的代码编辑器 开发环境 jshint 2.11.1 jsonlint 1.6.3 script-loader 0.7.2 vue 2.6.11 vue-codemi ...
- 【转载】手动DIY制作机械臂
相关链接: https://news.cnblogs.com/n/703664/ https://www.bilibili.com/video/BV12341117rG https://www.cnb ...
- 【转载】 tensorflow变量默认是如何进行初始化的?
版权声明:本文为CSDN博主「TahoeWang」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明.原文链接:https://blog.csdn.net/sinat_3 ...
- 使用tensorbaoardx报错——Descriptors cannot not be created directly. If this call came from a _pb2.py file, your generated code is out of date and must be regenerated with protoc >= 3.19.0.
运行代码报错: from tensorboardX import SummaryWriter 报错内容: 发生异常: TypeError Descriptors cannot not be creat ...
- 拈花云科基于 Apache DolphinScheduler 在文旅业态下的实践
作者|云科NearFar X Lab团队 左益.周志银.洪守伟.陈超.武超 一.导读 无锡拈花云科技服务有限公司(以下简称:拈花云科)是由拈花湾文旅和北京滴普科技共同孵化的文旅目的地数智化服务商.20 ...
- Meissel_Lehmer模板
复杂度 \(O(n^\frac 23)\),计算 \(1\sim n\) 的素数个数 #define div(a, b) (1.0 * (a) / (b)) #define half(x) (((x) ...
- AtCoder Beginner Contest 318
AtCoder Beginner Contest 318 A - Full Moon (atcoder.jp) 以\(M\)为首项,\(P\)为公差,看\(1 \sim N\)里包含了多少项的个数 # ...
- OpenHarmony编译构建系统详解,从零搭建windows下开发环境,巨方便!
自从OpenHarmony更新了dev-tool,就可以在windows下构建鸿蒙(轻量型)系统了,这对于进行MCU开发的朋友们,学习鸿蒙OS会友好许多!我们可以更快的构建出系统,方便快速学习和验证. ...
- git使用问题记录
hint: Updates were rejected because the remote contains work that you do 问题原因: 远程仓库中含有本地仓库没有的文件 直接拉取 ...
- C#/.NET/.NET Core技术前沿周刊 | 第 2 期(2024年8.19-8.25)
前言 C#/.NET/.NET Core技术前沿周刊,你的每周技术指南针!记录.追踪C#/.NET/.NET Core领域.生态的每周最新.最实用.最有价值的技术文章.社区动态.优质项目和学习资源等. ...