Hive 2.3.2安装
一、安装mysql
- 安装MySQL服务器端和MySQL客户端;
•安装:
– yum install mysql
– yum install mysql-server
•启动:
– /etc/init.d/mysqld start
进入mysql:

5)给mysql的user用户表添加一个user 其中host为%允许任何ip访问,密码同上即可,添加语句如下:
5.1) update user set password = password(‘root’) where user = ‘root’;
5.2) GRANT ALL PRIVILEGES ON . TO ‘root’@’%’ IDENTIFIED BY ‘root’ WITH GRANT OPTION;
5.3) flush privileges;

6、mysql中表的中文乱码问题:
创建表结构:
create table userinfo(
uid int primary key auto_increment,
username varchar(20)
)engine=InnoDB DEFAULT CHARSET=utf8;
insert into userinfo(username)values('测试');
1)检查内部的编码:SHOW VARIABLES LIKE ‘character_set_%’;

SHOW VARIABLES LIKE ‘collation_%’;

2)修改编码:SET NAMES ‘utf8’;

效果如下:

二、安装Hive
1、下载、解压hive、在hive/conf 下 新建hive-site.xml,进行如下配置
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
以下可选配置,该配置信息用来指定 Hive 数据仓库的数据存储在 HDFS 上的目录
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/hive/warehouse</value>
<description>hive default warehouse, if nessecory, change it</description>
</property>
2、在环境变量配置HIVE_HOME,并且让环境变量生效
source /etc/profile
三、安装MySQL链接工具
1、下载、解压
https://cdn.mysql.com//Downloads/Connector-J/mysql-connector-java-5.1.47.tar.gz
2、复制数据库驱动到 hive的lib下
cp mysql-connector-java-5.1.47-bin.jar /home/bigdata/apache-hive-1.2.2-bin/lib
3、更新jline.jar包
cp jline-2.12.1.jar /home/bigdata/hadoop/share/hadoop/yarn/lib/
四、初始化元数据库(hive2.x之后必须手动初始化)
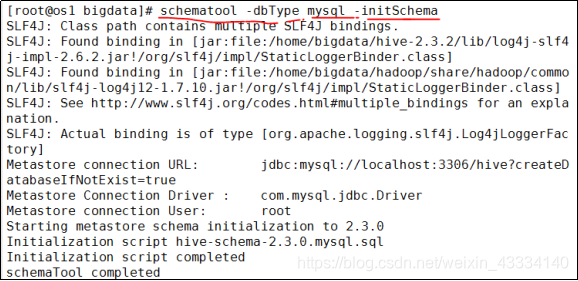
schematool -dbType mysql -initSchema
五、启动Hive (提前启动hdfs、mysql)
1、hive
2、hive --service cli

3、HiveServer2/beeline
3.1)修改hadoop的hdfs.site.xml文件:
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
3.2)修改hadoop集群的core-site.xml配置文件
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
配置解析:
hadoop.proxyuser.hadoop.hosts 配置成*的意义,表示任意节点使用 hadoop 集群的代理用户 root 都能访问 hdfs 集群,hadoop.proxyuser.hadoop.groups 表示代理用户的组所属
( 如果代理用户的组所属tong 则修改为:hadoop.proxyuser.tong.hosts
hadoop.proxyuser.tong.groups )
注意:启动之前,先启动hdfs,再启动hiveserver2,再beeline
3.3.1)先启动hiveserver2服务,启动后会多个【RunJar】进程

3.3.2)启动为后台:
nohup hiveserver2 1>/home/bigdata/hadoop/hiveserver.log 2>/home/bigdata/hadoop/hiveserver.err &
与地址有关系:
nohup hiveserver2 1>/opt/hadoop-2.7.5/hiveserver.log 2>/opt/hadoop-2.7.5/hiveserver.err &
//查看job hadoop job -list

解释:
1:表示标准日志输出
2:表示错误日志输出 如果我没有配置日志的输出路径,日志会生成在当前工作目录,
默认的日志名称叫做: nohup.xxx
PS:nohup 命令:如果你正在运行一个进程,而且你觉得在退出帐户时该进程还不会结束, 那么可以使用 nohup 命令。
该命令可以在你退出帐户/关闭终端之后继续运行相应的进程。 nohup 就是不挂起的意思(no hang up)。 该命令的一般
形式为:nohup command &
3.3.3) 启动beeline 客户端去连接
beeline -u jdbc:hive2//os1:10000 -n root
注意:u : 指定元数据库的链接信息 -n : 指定用户名和密码
3.3.4) 启动beeline ,然后输出!connect jdbc:hive2://os1:10000,输入用户名和密码
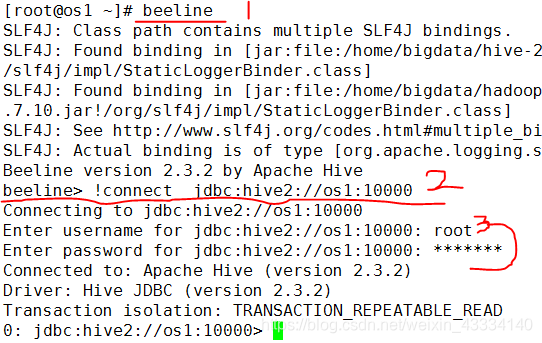
下面可以做hive操作。
Hive 2.3.2安装的更多相关文章
- Hive的三种安装方式(内嵌模式,本地模式远程模式)
一.安装模式介绍: Hive官网上介绍了Hive的3种安装方式,分别对应不同的应用场景. 1.内嵌模式(元数据保村在内嵌的derby种,允许一个会话链接,尝试多个会话链接时会报错) ...
- Hive学习之一 《Hive的介绍和安装》
一.什么是Hive Hive是建立在 Hadoop 上的数据仓库基础构架.它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储.查询和分析存储在 Hadoop 中的大规模数据 ...
- Hive基础概念、安装部署与基本使用
1. Hive简介 1.1 什么是Hive Hives是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能. 1.2 为什么使用Hive ① 直接使用 ...
- Hive/Hbase/Sqoop的安装教程
Hive/Hbase/Sqoop的安装教程 HIVE INSTALL 1.下载安装包:https://mirrors.tuna.tsinghua.edu.cn/apache/hive/hive-2.3 ...
- Hive 2.1.1安装配置
##前期工作 安装JDK 安装Hadoop 安装MySQL ##安装Hive ###下载Hive安装包 可以从 Apache 其中一个镜像站点中下载最新稳定版的 Hive, apache-hive-2 ...
- Hive的介绍及安装
简介 Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件 映射为一张数据库表,并提供类 SQL 查询功能. 本质是将 SQL 转换为 MapReduce 程序. Hive组件 ...
- HIVE 2.1.0 安装教程。(数据源mysql)
前期工作 安装JDK 安装Hadoop 安装MySQL 安装Hive 下载Hive安装包 可以从 Apache 其中一个镜像站点中下载最新稳定版的 Hive, apache-hive-2.1.0-bi ...
- Mac OSX系统中Hadoop / Hive 与 spark 的安装与配置 环境搭建 记录
Mac OSX系统中Hadoop / Hive 与 spark 的安装与配置 环境搭建 记录 Hadoop 2.6 的安装与配置(伪分布式) 下载并解压缩 配置 .bash_profile : ...
- Hive详解(02) - Hive 3.1.2安装
Hive详解(02) - Hive 3.1.2安装 安装准备 Hive下载地址 Hive官网地址:http://hive.apache.org/ 官方文档查看地址:https://cwiki.apac ...
- Hive[1] 初识 及 安装
本文前提是Hadoop & Java & mysql 数据库,已经安装配置好,并且 环境变量均已经配置到位 声明:本笔记参照 学习<Hive 编程指南>而来,如果有错误 ...
随机推荐
- 兼容sentry协议的轻量级监控,glitchtip
前言 上一篇文章说了重启 sentry 的事 因为过程太折腾了,一度想过放弃 sentry 换成其他比较轻量级的开源监控系统 这不就给我找到了另外俩个 https://glitchtip.com/ h ...
- static个人理解
static解:主要用于内存管理,static关键字的方法不需要new对象就可以直接在同static内进行调用,在其他类中可直接通过类名进行变量的访问.static关键字属于类,不是类的实例.成员分为 ...
- android实现多线程基础
//创建线程类 class Mythread extends Thread{ @Override public void run(){ //定义行为 } } //实例化线程类 MyThread mt= ...
- RESTful服务与swagger
一开始刚学springboot的时候 restful服务+swagger一点都看不懂,现在知识学了一些,再回头看这些东西就简单很多了. 自己跟视频做了一个零件项目,里面写了一些零零散散的模块,其中在视 ...
- windows10使用scp命令
windows10使用scp命令 windows自带scp命令 windows上传文件到linux//使用方法:scp 源文件路径 账户@地址:目的路径scp C:\Users\zbh\Deskt ...
- Postman汉化成中文版
postman安装默认是英文版,为使用方便使用汉化包转成中文版 1.查看本地安装的postman版本:Settings->About 2.根据postman的版本下载对应的汉化包,汉化包网址 3 ...
- 【JavaScript】下滑线命名转驼峰命名处理
同事写接口返回的JSON属性名称始终不一致,一会下划线一会驼峰 然后自己封装了一个: function toHump(name){ var newName = name.toLowerCase(); ...
- VcXsrv: 一个好用的Windows X11 Server
windows10没有系统自带的X11服务器,使用了几款X11的windows下X11服务器软件后发现了一个好用的软件--VcXsrv. 下载地址: https://sourceforge.net/p ...
- vscode中文环境配置
1.背景 2.配置 2.1.安装中文包 如果没有按照中文插件需要先按照中文插件 如果你是首次安装,安装完成后会引导你重启,就可以了 2.2.设置成中文环境 打开VSCode软件,按快捷键[Ctrl+S ...
- js 实现俄罗斯方块(三)
我又来啦!上一篇有点水,本篇我们来干货! 嘿嘿,首先我们先搭建游戏世界------网格 所有的操作包括左移右移下移旋转都是在这个网格中 既然是使用js来写当然跑不了html啦,实现网格最简单的 方法就 ...