Spark面试题(六)——Spark资源调优
Spark系列面试题
- Spark面试题(一)
- Spark面试题(二)
- Spark面试题(三)
- Spark面试题(四)
- Spark面试题(五)——数据倾斜调优
- Spark面试题(六)——Spark资源调优
- Spark面试题(七)——Spark程序开发调优
- Spark面试题(八)——Spark的Shuffle配置调优
1、资源运行情况
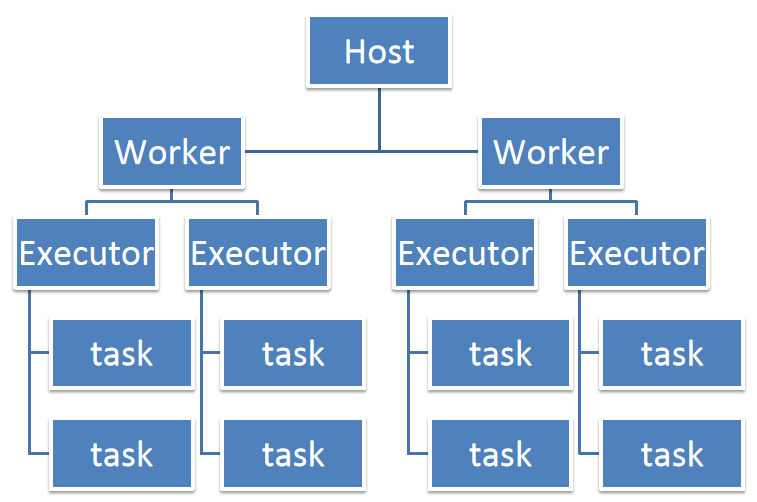
2、资源运行中的集中情况
(1)实践中跑的Spark job,有的特别慢,查看CPU利用率很低,可以尝试减少每个executor占用CPU core的数量,增加并行的executor数量,同时配合增加分片,整体上增加了CPU的利用率,加快数据处理速度。
(2)发现某job很容易发生内存溢出,我们就增大分片数量,从而减少了每片数据的规模,同时还减少并行的executor数量,这样相同的内存资源分配给数量更少的executor,相当于增加了每个task的内存分配,这样运行速度可能慢了些,但是总比OOM强。
(3)数据量特别少,有大量的小文件生成,就减少文件分片,没必要创建那么多task,这种情况,如果只是最原始的input比较小,一般都能被注意到;但是,如果是在运算过程中,比如应用某个reduceBy或者某个filter以后,数据大量减少,这种低效情况就很少被留意到。
3、运行资源优化配置
一个CPU core同一时间只能执行一个线程。而每个Executor进程上分配到的多个task,都是以每个task一条线程的方式,多线程并发运行的。
一个应用提交的时候设置多大的内存?设置多少Core?设置几个Executor?
./bin/spark-submit \
--master yarn-cluster \
--num-executors 100 \
--executor-memory 6G \
--executor-cores 4 \
--driver-memory 1G \
--conf spark.default.parallelism=1000 \
--conf spark.storage.memoryFraction=0.5 \
--conf spark.shuffle.memoryFraction=0.3
3.1 运行资源优化配置 -num-executors
参数说明:该参数用于设置Spark作业总共要用多少个Executor进程来执行。Driver在向YARN集群管理器申请资源时,YARN集群管理器会尽可能按照你的设置来在集群的各个工作节点上,启动相应数量的Executor进程。这个参数非常之重要,如果不设置的话,默认只会给你启动少量的Executor进程,此时你的Spark作业的运行速度是非常慢的。
参数调优建议:每个Spark作业的运行一般设置50~100个左右的Executor进程比较合适,设置太少或太多的Executor进程都不好。设置的太少,无法充分利用集群资源;设置的太多的话,大部分队列可能无法给予充分的资源。
3.2 运行资源优化配置 -executor-memory
参数说明:该参数用于设置每个Executor进程的内存。Executor内存的大小,很多时候直接决定了Spark作业的性能,而且跟常见的JVM OOM异常,也有直接的关联。
参数调优建议:每个Executor进程的内存设置4G~8G较为合适。但是这只是一个参考值,具体的设置还是得根据不同部门的资源队列来定。可以看看自己团队的资源队列的最大内存限制是多少,num-executors * executor-memory,是不能超过队列的最大内存量的。此外,如果你是跟团队里其他人共享这个资源队列,那么申请的内存量最好不要超过资源队列最大总内存的1/3~1/2,避免你自己的Spark作业占用了队列所有的资源,导致别的同事的作业无法运行。
3.3 运行资源优化配置 -executor-cores
参数说明:该参数用于设置每个Executor进程的CPU core数量。这个参数决定了每个Executor进程并行执行task线程的能力。因为每个CPU core同一时间只能执行一个task线程,因此每个Executor进程的CPU core数量越多,越能够快速地执行完分配给自己的所有task线程。
参数调优建议:Executor的CPU core数量设置为2~4个较为合适。同样得根据不同部门的资源队列来定,可以看看自己的资源队列的最大CPU core限制是多少,再依据设置的Executor数量,来决定每个Executor进程可以分配到几个CPU core。同样建议,如果是跟他人共享这个队列,那么num-executors * executor-cores不要超过队列总CPU core的1/3~1/2左右比较合适,也是避免影响其他同事的作业运行。
3.4 运行资源优化配置 -driver-memory
参数说明:该参数用于设置Driver进程的内存。
参数调优建议:Driver的内存通常来说不设置,或者设置1G左右应该就够了。唯一需要注意的一点是,如果需要使用collect算子将RDD的数据全部拉取到Driver上进行处理(或者是用map side join操作),那么必须确保Driver的内存足够大,否则会出现OOM内存溢出的问题。
3.5 运行资源优化配置 -spark.default.parallelism
参数说明:该参数用于设置每个stage的默认task数量,也可以认为是分区数。这个参数极为重要,如果不设置可能会直接影响你的Spark作业性能。
参数调优建议:Spark作业的默认task数量为500~1000个较为合适。很多人常犯的一个错误就是不去设置这个参数,那么此时就会导致Spark自己根据底层HDFS的block数量来设置task的数量,默认是一个HDFS block对应一个task。通常来说,Spark默认设置的数量是偏少的(比如就几十个task),如果task数量偏少的话,就会导致你前面设置好的Executor的参数都前功尽弃。试想一下,无论你的Executor进程有多少个,内存和CPU有多大,但是task只有1个或者10个,那么90%的Executor进程可能根本就没有task执行,也就是白白浪费了资源!因此Spark官网建议的设置原则是,设置该参数为num-executors * executor-cores的2~3倍较为合适,比如Executor的总CPU core数量为300个,那么设置1000个task是可以的,此时可以充分地利用Spark集群的资源。
3.6 运行资源优化配置 -spark.storage.memoryFraction
参数说明:该参数用于设置RDD持久化数据在Executor内存中能占的比例,默认是0.6。也就是说,默认Executor 60%的内存,可以用来保存持久化的RDD数据。根据你选择的不同的持久化策略,如果内存不够时,可能数据就不会持久化,或者数据会写入磁盘。
参数调优建议:如果Spark作业中,有较多的RDD持久化操作,该参数的值可以适当提高一些,保证持久化的数据能够容纳在内存中。避免内存不够缓存所有的数据,导致数据只能写入磁盘中,降低了性能。但是如果Spark作业中的shuffle类操作比较多,而持久化操作比较少,那么这个参数的值适当降低一些比较合适。此外,如果发现作业由于频繁的gc导致运行缓慢(通过spark web ui可以观察到作业的gc耗时),意味着task执行用户代码的内存不够用,那么同样建议调低这个参数的值。
3.7 运行资源优化配置 -spark.shuffle.memoryFraction
参数说明:该参数用于设置shuffle过程中一个task拉取到上个stage的task的输出后,进行聚合操作时能够使用的Executor内存的比例,默认是0.2。也就是说,Executor默认只有20%的内存用来进行该操作。shuffle操作在进行聚合时,如果发现使用的内存超出了这个20%的限制,那么多余的数据就会溢写到磁盘文件中去,此时就会极大地降低性能。
参数调优建议:如果Spark作业中的RDD持久化操作较少,shuffle操作较多时,建议降低持久化操作的内存占比,提高shuffle操作的内存占比比例,避免shuffle过程中数据过多时内存不够用,必须溢写到磁盘上,降低了性能。此外,如果发现作业由于频繁的gc导致运行缓慢,意味着task执行用户代码的内存不够用,那么同样建议调低这个参数的值。
总结:
1、num-executors:应用运行时executor的数量,推荐50-100左右比较合适
2、executor-memory:应用运行时executor的内存,推荐4-8G比较合适
3、executor-cores:应用运行时executor的CPU核数,推荐2-4个比较合适
4、driver-memory:应用运行时driver的内存量,主要考虑如果使用map side join或者一些类似于collect的操作,那么要相应调大内存量
5、spark.default.parallelism:每个stage默认的task数量,推荐参数为num-executors * executor-cores的2~3倍较为合适
6、spark.storage.memoryFraction:每一个executor中用于RDD缓存的内存比例,如果程序中有大量的数据缓存,可以考虑调大整个的比例,默认为60%
7、spark.shuffle.memoryFraction:每一个executor中用于Shuffle操作的内存比例,默认是20%,如果程序中有大量的Shuffle类算子,那么可以考虑其它的比例
Spark面试题(六)——Spark资源调优的更多相关文章
- Spark(六)Spark之开发调优以及资源调优
Spark调优主要分为开发调优.资源调优.数据倾斜调优.shuffle调优几个部分.开发调优和资源调优是所有Spark作业都需要注意和遵循的一些基本原则,是高性能Spark作业的基础:数据倾斜调优,主 ...
- Spark性能优化--开发调优与资源调优
参考: https://tech.meituan.com/spark-tuning-basic.html https://zhuanlan.zhihu.com/p/22024169 一.开发调优 1. ...
- Spark性能优化:数据倾斜调优
前言 继<Spark性能优化:开发调优篇>和<Spark性能优化:资源调优篇>讲解了每个Spark开发人员都必须熟知的开发调优与资源调优之后,本文作为<Spark性能优化 ...
- Spark数据本地化-->如何达到性能调优的目的
Spark数据本地化-->如何达到性能调优的目的 1.Spark数据的本地化:移动计算,而不是移动数据 2.Spark中的数据本地化级别: TaskSetManager 的 Locality L ...
- Spark机器学习——模型选择与参数调优之交叉验证
spark 模型选择与超参调优 机器学习可以简单的归纳为 通过数据训练y = f(x) 的过程,因此定义完训练模型之后,就需要考虑如何选择最终我们认为最优的模型. 如何选择最优的模型,就是本篇的主要内 ...
- Spark SQL概念学习系列之性能调优
不多说,直接上干货! 性能调优 Caching Data In Memory Spark SQL可以通过调用sqlContext.cacheTable("tableName") 或 ...
- CentOS7安装CDH 第十二章:YARN的资源调优
相关文章链接 CentOS7安装CDH 第一章:CentOS7系统安装 CentOS7安装CDH 第二章:CentOS7各个软件安装和启动 CentOS7安装CDH 第三章:CDH中的问题和解决方法 ...
- (转)WebSphere 中池资源调优 - 线程池、连接池和 ORB
WebSphere 中池资源调优 - 线程池.连接池和 ORB 来自:https://www.ibm.com/developerworks/cn/websphere/library/techartic ...
- (转)Spark性能优化:资源调优篇
在开发完Spark作业之后,就该为作业配置合适的资源了.Spark的资源参数,基本都可以在spark-submit命令中作为参数设置.很多Spark初学者,通常不知道该设置哪些必要的参数,以及如何 ...
- 【转载】 Spark性能优化:资源调优篇
在开发完Spark作业之后,就该为作业配置合适的资源了.Spark的资源参数,基本都可以在spark-submit命令中作为参数设置.很多Spark初学者,通常不知道该设置哪些必要的参数,以及如何设置 ...
随机推荐
- C?C++?
代码逆向 在这里需要注意的几个点: c#语言赋值号(=)右边的值同样会跟着左边的值改变,如array6=array2,array6+=2:这个时候array2也会变 如array7[num5] += ...
- 手把手教你如何扩展(破解)mybatisplus的sql生成
mybatisplus 的常用CRUD方法 众所周知,mybatisplus提供了强大的代码生成能力,他默认生成的常用的CRUD方法(例如插入.更新.删除.查询等)的定义,能够帮助我们节省很多体力劳动 ...
- 一键整合,万用万灵,Python3.10项目嵌入式一键整合包的制作(Embed)
我们知道Python是一门解释型语言,项目运行时需要依赖Python解释器,并且有时候需要安装项目中对应的三方依赖库.对于专业的Python开发者来说,可以直接通过pip命令进行安装即可.但是如果是分 ...
- 从管易云到MySQL通过接口配置打通数据
从管易云到MySQL通过接口配置打通数据 数据源平台:管易云 管易云是金蝶旗下专注提供电商企业管理软件服务的子品牌,先后开发了C-ERP.EC-OMS.EC-WMS.E店管家.BBC.B2B.B2C商 ...
- Postgres 和 MySQL 应该怎么选?
PostgreSQL和MySQL是两个流行的关系型数据库管理系统(DBMS).它们都具有一些相似的功能,但也有一些区别. 在选择使用哪个DBMS时,需要考虑多个因素,包括性能.可扩展性.安全性.功能丰 ...
- h5移动端使用video实现拍照、上传文件对象、选择相册,做手机兼容。
html部分 <template> <div class="views"> <video style="width: 100vw; heig ...
- 将 .NET Aspire 部署到 Kubernetes 集群
使用Aspirate可以将Aspire程序部署到Kubernetes 集群 工具安装 dotnet tool install -g aspirate --prerelease 注意:Aspirate ...
- 在.net中通过自定义LoggerProvider将日志保存到数据库方法(以mysql为例)
在.NET中,Microsoft.Extensions.Logging是一个灵活的日志库,它允许你将日志信息记录到各种不同的目标,包括数据库.在这个示例中,我将详细介绍如何使用Microsoft.Ex ...
- Springboot整合shiro,带你学会shiro,入门级别教程,由浅入深,完整代码案例,各位项目想加这个模块的人也可以看这个,又或者不会mybatis-plus的也可以看这个
如果你对shiro有问题的话,请看这篇文章:Springboot+shiro,完整教程,带你学会shiro-CSDN博客 第一步,先准备数据库: 数据库需要准备三个表,一个user表,一个role表, ...
- Winform 控件库 MaterialSkin.2 使用教程(鸿蒙字体版)
️MaterialSkin.2 控件库在之前的文章中已经介绍过了,就不啰嗦了 - > Winform 好看控件库推荐:MaterialSkin.2 ️官方库里使用的是 Google 的 Robo ...