AI新手语音入门:认识词错率WER与字错率CER
摘要:本文介绍了词错率WER和字错率CER的概念,引入了编辑距离的概念与计算方法,从而推导得到词错率或字错率的计算方法。
本文分享自华为云社区《新手语音入门(一):认识词错率WER与字错率CER | 编辑距离 | 莱文斯坦距离 | 动态规划》,作者:黄辣鸡。
1. 词/字错率的概念
1.1 词错率与字错率
词错率(Word Error Rate, WER)是一项用于评价ASR性能的重要指标,用来评价预测文本与标准文本之间错误率,因此词错率最大的特点是越小越好。像英语、阿拉伯语语音转文本或语音识别任务中研究者常用WER衡量ASR效果好坏。
因为英文语句中句子的最小单位是单词,而中文语句中的最小单位是汉字,因此在中文语音转文本任务或中文语音识别任务中使用字错率(Character Error Rate, CER)来衡量中文ASR效果好坏。
两者计算方式相同,为行文统一,下文统一使用WER表示该性能。
1.2 计算公式
它们的计算公式是:

假设有一个参考例句Ref和一段ASR系统转写语音后生成的预测文本Hyp。带入上面公式,S表示将Hyp转化为Ref时发生的替换数量,D表示将Hyp转化为Ref时发生的替换数量,I代表将Hypo转化为Ref时发生的插入数量,N代表Ref句子中总的字数或者英文单词数。C代表Hyp句子中识别正确的字数。即原参考句子总字数N = S+ D + C。
再说一句,根据维基百科里面的说法,N就是原样例文本总的字数。
举例1:
Ref: 你吃了吗
Hyp: 你吃了么
标准文本为“你吃了吗”,转写结果为“你吃了么”,上例发生了一次错误替换,Hyp将“吗”替换成了么,即S=1,D=0, I =0, 参考文本字数N=4, 因此本次转写结果WER= 1/4 = 25%.
举例2:
Ref: 你吃了吗
Hyp: 你吃了
预测文本为“你吃了”,相比标准文本错误删除1个“吗”,即S=0,D=1,I=0,N=4,因此本次转写结果WER = 1/4 = 25%。
举例3:
Ref: 今天天气很好
Hyp: 今天天气很好啊
举例3中,Hyp文本相比标准文本错误插入了一个“啊”,即S=0,D=0,I =1,N=6,因此字错率WER= 1/6 = 16.7%。
2. 字错率的实现
在参考文本给出的情况下,N可以很轻易统计出来,而编辑数量 S+I+DS+I+D的计算我们通过编辑距离的引入来计算。
2.1 编辑距离的概念
编辑距离,由前苏联数学家弗拉基米尔·莱温斯坦在1965年提出,通过计算两个字符串互相转换所需要的最小编辑数来描述两个字符串的差异,编辑操作包括替换,删除,插入。编辑距离也叫莱温斯基距离,当前被广泛用于字错率计算,DNA序列比对,拼写检测等领域。
编辑距离就等同于上文所述的S+D+IS+D+I。
编辑距离的公式为:
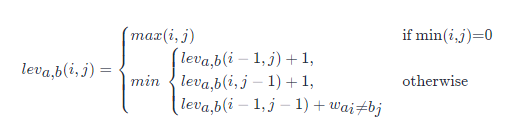
其中 ww为指示函数,当ai≠bj时,其值为1;当ai=aj时,其值为0。
作为一个新手,直接看这个公式,可能不明所以。但是如果可以用一个矩阵来表示这个公式,并自己在纸上推导一遍,回过头来再看这个公式就会相对比较容易理解。 可以参考2.2示例。
2.2 编辑距离的计算
假设我们有两个词,horse和ros,需要计算他们俩的编辑距离。我们假设horse是参考例句Ref,而ros是预测文本Hyp, 现在计算ros转换为horse所需要的最少操作数,即它俩的编辑距离。
参考Leetcode问题#71
我们首先定义一个距离矩阵,并且命名为cache。矩阵的行数为ros字符长度+1, 矩阵的列数为horse字符长度+1,因此cache为一个4️6的矩阵。下文中用i表示行数,用j表示列数。
矩阵大概长这个样子:
+------+------+---+---+---+---+---+
| | null | h | o | r | s | e |
+------+------+---+---+---+---+---+
| null | | | | | | |
| r | | | | | | |
| o | | | | | | |
| s | | | | | | |
+------+------+---+---+---+---+---+
多出来的一行和一列给了null。而矩阵中的每个元素将保存当前位置之前字符的互相转换所需要的操作数。例如cache[2][3]表示ro转换成为hor所需要的最小操作数。
如果可以得到最右下角的矩阵元素的值,那么就可以得到ros和horse之间互相转换所需要的编辑数。
因为我们可以较为容易的计算出来null转换为null或null转换为任何字符所需要的操作数,例如null转换成null的操作数为0,即cache[0][0]=0;null转换为h的操作数为1,即cache[0][1]=1,null转换为ho的操作数为2,即cache[0][2]=2。null转换为hor、hors、horse的操作数分别为3、4、5。
因此可以得到距离矩阵:
+------+------+---+---+---+---+---+
| | null | h | o | r | s | e |
+------+------+---+---+---+---+---+
| null | 0 | 1 | 2 | 3 | 4 | 5 | ️
| r | | | | | | |
| o | | | | | | |
| s | | | | | | |
+------+------+---+---+---+---+---+
同时可以发现一种模式,当i=0, cache[i][j] = j,
同理,竖列r、ro、ros转换为null的操作数分别为1、2、3,即分别删除1、2、3个字符。
得到以下距离矩阵:
+------+------+---+---+---+---+---+
| | null | h | o | r | s | e |
+------+------+---+---+---+---+---+
| null | 0 | 1 | 2 | 3 | 4 | 5 |
| r | 1 | | | | | |
| o | 2 | | | | | |
| s | 3 | | | | | |
+------+------+---+---+---+---+---+
️
并发现,当j=0, cache[i][j] = i。
计算距离矩阵中剩余的部分,我们首先定义两个矩阵规则,
当r \neq cr=c时,右下角的矩阵值为周边三个值最小值+1:
+---------+----------------------------------+
| replace | remove |
+---------+----------------------------------+
| insert | min(replace, remove, insert) + 1 |
+---------+----------------------------------+
当r = cr=c时,右下角的矩阵值为左上角对角矩阵的值。
+---+------------------------------+
|️ | |
+---+------------------------------+
| | just copy the diagonal value |
+---+------------------------------+
对于未填满的左上角第一个元素,r需要转换为h,根据上面第一种情况,周边三个值最小值+1,即0+1=1, 因此距离矩阵如下图:
+------+------+---+---+---+---+---+
| | null | h | o | r | s | e |
+------+------+---+---+---+---+---+
| null | 0 | 1 | 2 | 3 | 4 | 5 |
| r | 1 | 1 | | | | |
| o | 2 | | | | | |
| s | 3 | | | | | |
+------+------+---+---+---+---+---+
按照上述两个规则我们可以填满距离矩阵:
+------+------+---+---+---+---+---+
| | null | h | o | r | s | e |
+------+------+---+---+---+---+---+
| null | 0 | 1 | 2 | 3 | 4 | 5 |
| r | 1 | 1 | 2 | 2 | 3 | 4 |
| o | 2 | 2 | 1 | 2 | 3 | 4 |
| s | 3 | 2 | 2 | 2 | 2 | 3 |
+------+------+---+---+---+---+---+
得到右下角的值即ros转换成为horse的最小编辑数,即ros和horse的编辑距离为3。
这时,我们可以用公式语言描述上述两个规则:
当r \neq cr=c时,右下角的矩阵值为周边三个值最小值+1:
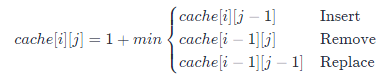
当r = cr=c时,右下角的矩阵值为左上角对角矩阵的值:
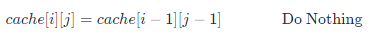
现在我们可以将上述计算过程再用合并一下:

不难发现这个公式就是来温斯坦公式,同时也是通过动态规划方法计算编辑距离的状态方程。
使用Python代码实现:
def min_distance(word1: str, word2: str) -> int:
row = len(word1) + 1
column = len(word2) + 1
cache = [ [0]*column for i in range(row) ]
for i in range(row):
for j in range(column):
if i ==0 and j ==0:
cache[i][j] = 0
elif i == 0 and j!=0:
cache[i][j] = j
elif j == 0 and i!=0:
cache[i][j] = i
else:
if word1[i-1] == word2[j-1]:
cache[i][j] = cache[i-1][j-1]
else:
replace = cache[i-1][j-1] + 1
insert = cache[i][j-1] + 1
remove = cache[i-1][j] + 1
cache[i][j] = min(replace, insert, remove)
return cache[row-1][column-1]
if __name__ == "__main__":
min_distance("ros", "horse")
如果将上述字符换成汉字或是单词,再计算两句话的S+D+IS+D+I的值,就很容易计算WER了。
参考
- Wikipedia: Word Error Rate
- Minimum Edit distance (Dynamic Programming) for converting one string to another string
- Leetcode: 72. Edit Distance
- Multiple lines one side of equation with a Curly Bracket
AI新手语音入门:认识词错率WER与字错率CER的更多相关文章
- 语音识别ASR - HTK(HResults)计算字错率WER、句错率SER
HResults计算字错率(WER).句错率(SER) 前言 好久没发文,看到仍有这么多关注的小伙伴,觉得不发篇文对不住.确实好久没有输出经验总结相关的文档,抽了个时间,整理了下笔记,发一篇关于ASR ...
- ASR测试方法---字错率(WER)、句错率(SER)统计
一.基础概念 1.1.语音识别(ASR) 语音识别(speech recognition)技术,也被称为自动语音识别(英语:Automatic Speech Recognition, ASR), 狭隘 ...
- 新手如何入门pytorch?
我最近的文章中,专门为想学Pytorch的新手推荐了一些学习资源,包括教程.视频.项目.论文和书籍.希望能对你有帮助:一.PyTorch学习教程.手册 (1)PyTorch英文版官方手册:https: ...
- 离线语音Snowboy热词唤醒+ 树莓派语音交互实现开关灯
离线语音Snowboy热词唤醒 语音识别现在有非常广泛的应用场景,如手机的语音助手,智能音响(小爱,叮咚,天猫精灵...)等. 语音识别一般包含三个阶段:热词唤醒,语音录入,识别和逻辑控制阶段. 热词 ...
- 【第1篇】人工智能(AI)语音测试原理和实践---宣传
前言 本文主要介绍作者关于人工智能(AI)语音测试的各方面知识点和实战技术. 本书共分为9章,第1.2章详细介绍人工智能(AI)语音测试各种知识点和人工智能(AI)语音交互原理:第3.4章介绍人工智 ...
- 贝叶斯公式由浅入深大讲解—AI基础算法入门
1 贝叶斯方法 长久以来,人们对一件事情发生或不发生的概率,只有固定的0和1,即要么发生,要么不发生,从来不会去考虑某件事情发生的概率有多大,不发生的概率又是多大.而且概率虽然未知,但最起码是一个确定 ...
- 贝叶斯公式由浅入深大讲解—AI基础算法入门【转】
本文转载自:https://www.cnblogs.com/zhoulujun/p/8893393.html 1 贝叶斯方法 长久以来,人们对一件事情发生或不发生的概率,只有固定的0和1,即要么发生, ...
- GitHub新手快速入门日常操作流程
GitHub新手快速入门日常操作流程 1. 注册帐号 打开https://github.com/,填写注册信息并提交. 2. 登录帐号 打开https://github.com/login,输入注册的 ...
- Django2.1新手图文入门教程
第一个django Web Django2.1新手图文入门教程 http://www.liujiangblog.com/blog/36/
- Sql Server新手学习入门
Sql Server新手学习入门 http://www.tudou.com/home/_117459337
随机推荐
- QPainter和QPainterPath理解
QPainter和QPainterPath QPainterPath (一)简介 (二)常用函数 1.addEllipse() 2.addPath() 3.addPolygon() 4.addRect ...
- mysql练习案例(实操)
最近想要在回去复习mysql语句,就在网上找了一些案例练习,起初找得都是零零散散的,后面参考这篇博客做出了一个实操案例.Eric_Squirrel:mysql学生表经典案例50题. 首先是建表,我用的 ...
- Java比赛常用API总结
1.栈和队列 1.1 栈的常用方法 //1.栈顶插入元素 push(element) //2.返回栈顶元素并弹出栈顶元素 pop() //3.返回栈顶元素但不弹出 peek() //4.清空栈 cle ...
- JAVA架构师
https://github.com/zq99299/note-architect https://zq99299.github.io/note-architect/hc/ https://zq992 ...
- DNS 服务 docker-bind 的部署使用
前言 前面使用 nginx 代理转发了几个域名到服务器,但是每次添加一个域名都需要在客户端添加一行 hosts 文件,无疑是繁琐的,其中也提到可以使用 DNS 来实现自动解析域名 到指定服务器的功能, ...
- excel表格怎么设置数据超链接?
在Excel表格中,可以设置超链接来快速导航到其他单元格.工作表.文件.网页等.下面我将详细介绍如何设置数据超链接. 1. 在Excel表格中选择要添加超链接的单元格或文本. 2. 使用鼠标右键点击选 ...
- [CF1748E] Yet Another Array Counting Problem
题目描述 The position of the leftmost maximum on the segment $ [l; r] $ of array $ x = [x_1, x_2, \ldots ...
- Lucas定理 、斯特灵公式
斯特灵公式是一条用来取n阶乘的近似值的数学公式. 公式为: 用该公式我们可以用来估算n阶乘的值:估算n阶乘的在任意进制下的位数. 如何计算在R进制下的位数:我们可以结合对数来计算,比如十进制就是lg( ...
- 华企盾DSC邮箱服务器测试连接提示Undefined error id(端口不通)
解决方法:由于云服务器没有开25端口,telnet不通(telnet smtp.163.com 25),允许一下25端口即可,如果不能启用25端口,则开启465或者587
- Kernel Memory 入门系列:文档的管理
Kernel Memory 入门系列: 文档的管理 在Quick Start中我们了解到如何快速直接地上传文档.当时实际中,往往会面临更多的问题,例如文档如何更新,如何划定查询范围等等.这里我们将详细 ...