字节跳动基于Doris的湖仓分析探索实践
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
Doris简介
Doris是一种MPP架构的分析型数据库,主要面向多维分析,数据报表,用户画像分析等场景。自带分析引擎和存储引擎,支持向量化执行引擎,不依赖其他组件,兼容MySQL协议。
Apache Doris具备以下几个特点:
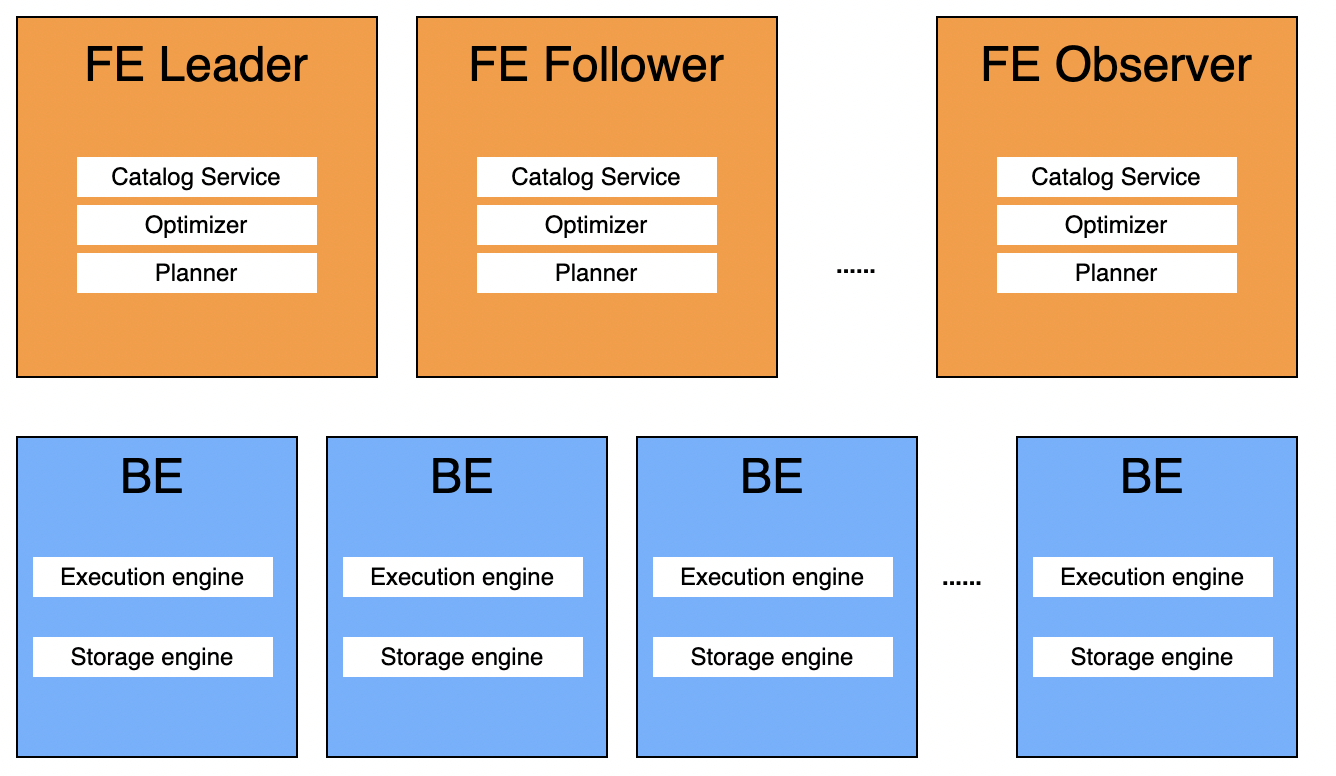
良好的架构设计,支持高并发低延时的查询服务,支持高吞吐量的交互式分析。多FE均可对外提供服务,并发增加时,线性扩充FE和BE即可支持高并发的查询请求。
支持批量数据load和流式数据load,支持数据更新。支持Update/Delete语法,unique/aggregate数据模型,支持动态更新数据,实时更新聚合指标。
提供了高可用,容错处理,高扩展的企业级特性。FE Leader错误异常,FE Follower秒级切换为新Leader继续对外提供服务。
支持聚合表和物化视图。多种数据模型,支持aggregate,replace等多种数据模型,支持创建rollup表,支持创建物化视图。rollup表和物化视图支持动态更新,无需用户手动处理。
MySQL协议兼容,支持直接使用MySQL客户端连接,非常易用的数据应用对接。
Doris由Frontend(以下简称FE)和Backend(以下简称BE)组成,其中FE负责接受用户请求,编译,优化,分发执行计划,元数据管理,BE节点的管理等功能,BE负责执行由FE下发的执行计划,存储和管理用户数据。
数据湖格式Hudi简介
Hudi是下一代流式数据湖平台,为数据湖提供了表格式管理的能力,提供事务,ACID,MVCC,数据更新删除,增量数据读取等功能。支持Spark,Flink,Presto,Trino等多种计算引擎。
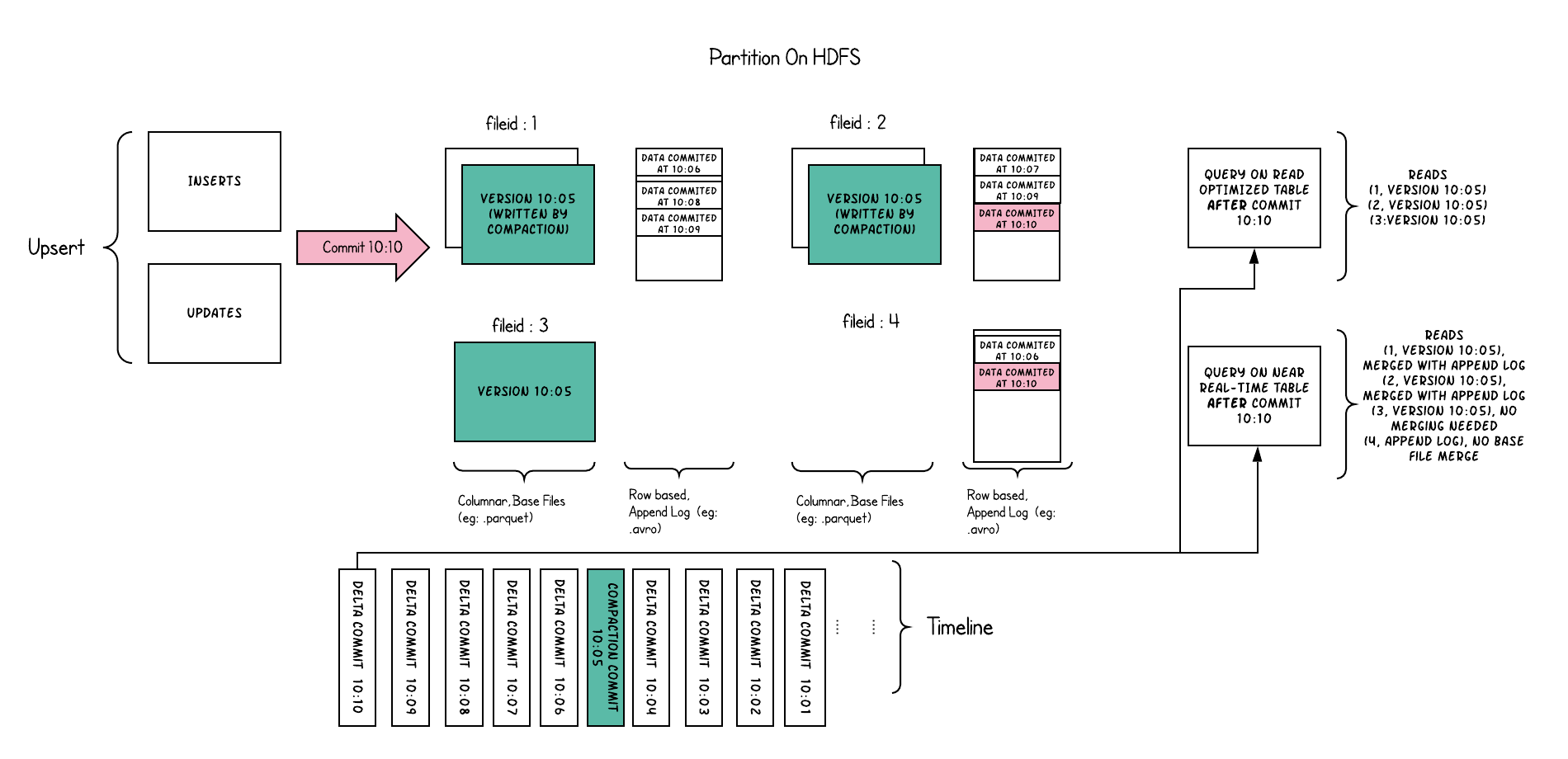
Hudi根据数据更新时行为不同分为两种表类型:

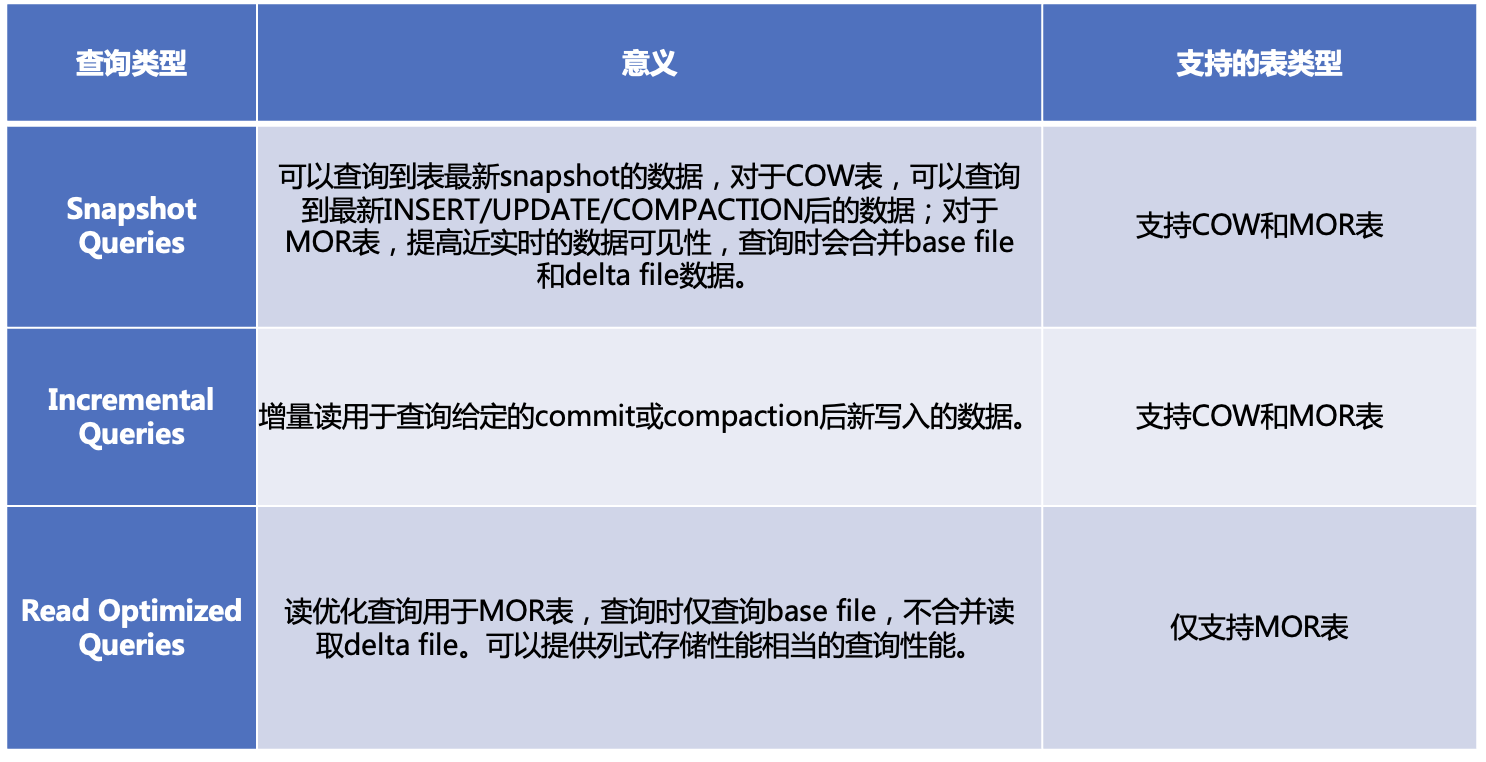
针对Hudi的两种表格式,存在3种不同的查询类型:
Doris分析Hudi数据的技术背景
在数仓业务中,随着业务对数据实时性的要求越来越高,T+1数仓业务逐渐往小时级,分钟级,甚至秒级演进。实时数仓的应用也越来越广,也经历了多个发展阶段。目前存在着多种解决方案。
Lambda架构
Lambda将数据处理流分为在线分析和离线分析分为两条不同的处理路径,两条路径互相独立,互不影响。
离线分析处理T+1数据,使用Hive/Spark处理大数据量,不可变数据,数据一般存储在HDFS等系统上。如果遇到数据更新,需要overwrite整张表或整个分区,成本比较高。
在线分析处理实时数据,使用Flink/Spark Streaming处理流式数据,分析处理秒级或分钟级流式数据,数据保存在Kafka或定期(分钟级)保存到HDFS中。
该套方案存在以下缺点:
同一套指标可能需要开发两份代码来进行在线分析和离线分析,维护复杂
数据应用查询指标时可能需要同时查询离线数据和在线数据,开发复杂
同时部署批处理和流式计算两套引擎,运维复杂
数据更新需要overwrite整张表或分区,成本高
Kappa架构
随着在线分析业务越来越多,Lambda架构的弊端就越来越明显,增加一个指标需要在线离线分别开发,维护困难,离线指标可能和在线指标对不齐,部署复杂,组件繁多。于是Kappa架构应运而生。
Kappa架构使用一套架构处理在线数据和离线数据,使用同一套引擎同时处理在线和离线数据,数据存储在消息队列上。
Kappa架构也有一定的局限:
流式计算引擎批处理能力较弱,处理大数据量性能较弱
数据存储使用消息队列,消息队列对数据存储有有效性限制,历史数据无法回溯
数据时序可能乱序,可能对部分对时序要求比较严格的应用造成数据错误
数据应用需要从消息队列中取数,需要开发适配接口,开发复杂
基于数据湖的实时数仓
针对Lambda架构和Kappa架构的缺陷,业界基于数据湖开发了Iceberg, Hudi, DeltaLake这些数据湖技术,使得数仓支持ACID, Update/Delete, 数据Time Travel, Schema Evolution等特性,使得数仓的时效性从小时级提升到分钟级,数据更新也支持部分更新,大大提高了数据更新的性能。兼具流式计算的实时性和批计算的吞吐量,支持的是近实时的场景。
以上方案中其中基于数据湖的应用最广,但数据湖模式无法支撑更高的秒级实时性,也无法直接对外提供数据服务,需要搭建其他的数据服务组件,系统较为复杂。基于此背景下,部分业务开始使用Doris来承接,业务数据分析师需要对Doris与Hudi中的数据进行联邦分析,此外在Doris对外提供数据服务时既要能查询Doris中数据,也要能加速查询离线业务中的数据湖数据,因此我们开发了Doris访问数据湖Hudi中数据的特性。
Doris分析Hudi数据的设计原理
基于以上背景,我们设计了Apache Doris中查询数据湖格式Hudi数据,因Hudi生态为java语言,而Apache Doris的执行节点BE为C++环境,而C++ 无法直接调用Hudi java SDK,针对这一点,我们有四种解决方案:
实现Hudi C++ client,在BE中直接调用Hudi C++ client去读写Hudi表。
该方案需要完整实现一套Hudi C++ client,开发周期较长,后期Hudi行为变更需要同步修改Hudi C++ client,维护较为困难。
BE通过thrift协议发送读写请求至Broker,由Broker调用Hudi java client读取Hudi表。
该方案需要在Broker中增加读写Hudi数据的功能,目前Broker定位仅为fs的操作接口,引入Hudi打破了Broker的定位。第二,数据需要在BE和Broker之间传输,性能较低。
在BE中使用JNI创建JVM,加载Hudi java client去读写Hudi表。
该方案需要在BE进程中维护JVM,有JVM调用Hudi java client对Hudi进行读写。读写逻辑使用Hudi社区java实现,可以维护与社区同步;同时数据在同一个进程中进行处理,性能较高。但需要在BE维护一个JVM,管理较为复杂。
使用BE arrow parquet c++ api读取hudi parquet base file,hudi表中的delta file暂不处理。
该方案可以由BE直接读取hudi表的parquet文件,性能最高。但当前不支持base file和delta file的合并读取,因此仅支持COW表Snapshot Queries和MOR表的Read Optimized Queries,不支持Incremental Queries。
综上,我们选择方案四,第一期实现了COW表Snapshot Queries和MOR表的Read Optimized Queries,后面联合Hudi社区开发base file和delta file合并读取的C++接口。
Doris分析Hudi数据的技术实现
Doris中查询分析Hudi外表使用步骤非常简单。
创建Hudi外表
建表时指定engine为Hudi,同时指定Hudi外表的相关信息,如hive metastore uri,在hive metastore中的database和table名字等。
建表仅仅在Doris的元数据中增加一张表,无任何数据移动。
建表时支持指定全部或部分hudi schema,也支持不指定schema创建hudi外表。指定schema时必须与hiveMetaStore中hudi表的列名,类型一致。
Example:
CREATE TABLE example_db.t_hudi
ENGINE=HUDI
PROPERTIES (
"hudi.database" = "hudi_db",
"hudi.table" = "hudi_table",
"hudi.hive.metastore.uris" = "thrift://127.0.0.1:9083"
);
CREATE TABLE example_db.t_hudi (
column1 int,
column2 string)
ENGINE=HUDI
PROPERTIES (
"hudi.database" = "hudi_db",
"hudi.table" = "hudi_table",
"hudi.hive.metastore.uris" = "thrift://127.0.0.1:9083"
);查询Hudi外表
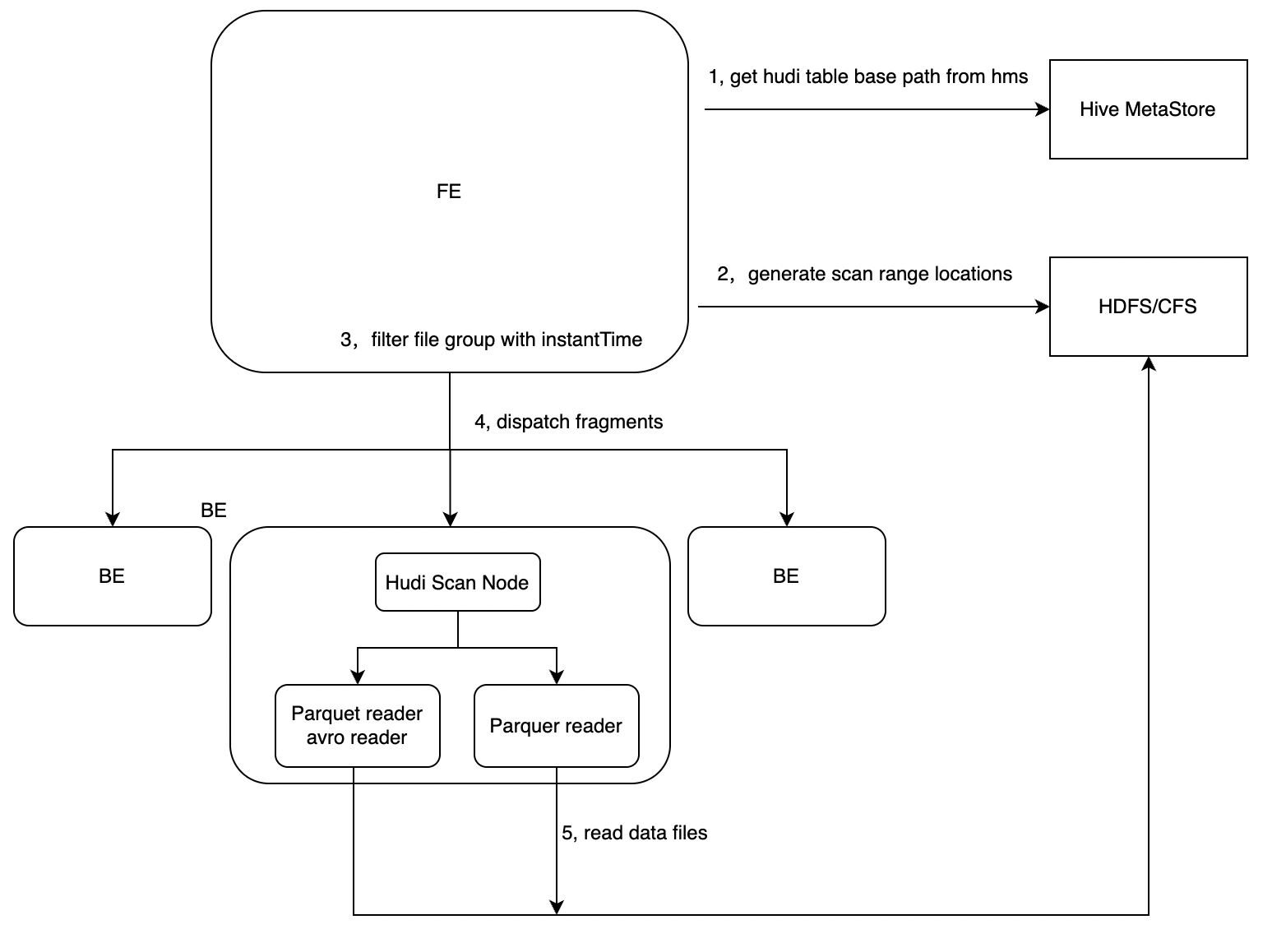
查询Hudi数据表时,FE在analazy阶段会查询元数据获取到Hudi外表的的hive metastore地址,从Hive metastore中获取hudi表的schema信息与文件路径。
获取hudi表的数据地址
FE规划fragment增加HudiScanNode。HudiScanNode中获取Hudi table对应的data file文件列表。
根据Hudi table获取的data file列表生成scanRange
下发HudiScan 任务至BE节点
BE节点根据HudiScanNode指定的Hudi外表文件路径调用native parquet reader进行数据读取。
后期规划
目前Apche Doris查询Hudi表已合入社区,当前已支持COW表的Snapshot Query,支持MOR表的Read Optimized Query。对MOR表的Snapshot Query暂时还未支持,流式场景中的Incremental Query也没有支持。
后续还有几项工作需要处理,我们和社区也在积极合作进行中:
MOR表的Snapshot Query。MOR表实时读需要合并读取Data file与对应的Delta file,BE需要支持Delta file AVRO格式的读取,需要增加avro的native读取方式。
COW/MOR表的Incremental Query。支持实时业务中的增量读取。
BE读取Hudi base file和delta file的native接口。目前BE读取Hudi数据时,仅能读取data file,使用的是parquet的C++ SDK。后期我们和联合Hudi社区提供Huid base file和delta file的C++/Rust等语言的读取接口,在Doris BE中直接使用native接口来查询Hudi数据。
本文为字节跳动数据平台研发工程师在DataFunSummit大会演讲实录,关注字节跳动数据平台微信公众号,回复【0929】,领取本次分享PPT。
立即跳转火山引擎E-MapReduce官网了解更多信息
字节跳动基于Doris的湖仓分析探索实践的更多相关文章
- 基于 Apache Hudi 极致查询优化的探索实践
摘要:本文主要介绍 Presto 如何更好的利用 Hudi 的数据布局.索引信息来加速点查性能. 本文分享自华为云社区<华为云基于 Apache Hudi 极致查询优化的探索实践!>,作者 ...
- 字节跳动基于Apache Hudi构建EB级数据湖实践
来自字节跳动的管梓越同学一篇关于Apache Hudi在字节跳动推荐系统中EB级数据量实践的分享. 接下来将分为场景需求.设计选型.功能支持.性能调优.未来展望五部分介绍Hudi在字节跳动推荐系统中的 ...
- 字节跳动基于ClickHouse优化实践之“多表关联查询”
更多技术交流.求职机会.试用福利,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 相信大家都对大名鼎鼎的ClickHouse有一定的了解了,它强大的数据分析性能让人印象深刻.但在字节大量 ...
- 华为云 MRS 基于 Apache Hudi 极致查询优化的探索实践
背景 湖仓一体(LakeHouse)是一种新的开放式架构,它结合了数据湖和数据仓库的最佳元素,是当下大数据领域的重要发展方向. 华为云早在2020年就开始着手相关技术的预研,并落地在华为云 Fusio ...
- 字节跳动流式数据集成基于Flink Checkpoint两阶段提交的实践和优化
背景 字节跳动开发套件数据集成团队(DTS ,Data Transmission Service)在字节跳动内基于 Flink 实现了流批一体的数据集成服务.其中一个典型场景是 Kafka/ByteM ...
- 刷到血赚!字节跳动内部出品:722页Android开发《360°全方面性能调优》学习手册首次外放,附项目实战!
前言 我们平时在使用软件的过程中是不是遇到过这样的情况:"这个 app 怎么还没下载完!"."太卡了吧!"."图片怎么还没加载出来!".&q ...
- 字节跳动数据平台技术揭秘:基于 ClickHouse 的复杂查询实现与优化
更多技术交流.求职机会.试用福利,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 ClickHouse 作为目前业内主流的列式存储数据库(DBMS)之一,拥有着同类型 DBMS 难以企及 ...
- Presto 在字节跳动的内部实践与优化
在字节跳动内部,Presto 主要支撑了 Ad-hoc 查询.BI 可视化分析.近实时查询分析等场景,日查询量接近 100 万条.本文是字节跳动数据平台 Presto 团队-软件工程师常鹏飞在 Pre ...
- 深度介绍Flink在字节跳动数据流的实践
本文是字节跳动数据平台开发套件团队在1月9日Flink Forward Asia 2021: Flink Forward 峰会上的演讲分享,将着重分享Flink在字节跳动数据流的实践. 字节跳动数据流 ...
- 在字节跳动,一个更好的企业级SparkSQL Server这么做
SparkSQL是Spark生态系统中非常重要的组件.面向企业级服务时,SparkSQL存在易用性较差的问题,导致难满足日常的业务开发需求.本文将详细解读,如何通过构建SparkSQL服务器实现使用效 ...
随机推荐
- k8s-服务网格实战-配置 Mesh(灰度发布)
在上一篇 k8s-服务网格实战-入门Istio中分享了如何安装部署 Istio,同时可以利用 Istio 实现 gRPC 的负载均衡. 今天我们更进一步,深入了解使用 Istio 的功能. 从 Ist ...
- 生命游戏(4.2leetcode每日打卡)
根据 百度百科 ,生命游戏,简称为生命,是英国数学家约翰·何顿·康威在 1970 年发明的细胞自动机. 给定一个包含 m × n 个格子的面板,每一个格子都可以看成是一个细胞.每个细胞都具有一个初始状 ...
- RPN FPN ROIPooling
RPN(Region Proposal Network)介绍---> 特点从backbone 生成的Feture Map中 用一个 3x3 的Conv卷积核 遍历FeatureMap的每个点然后 ...
- 为什么MySQL不建议使用delete删除数据?
MySQL并不直接建议禁止使用DELETE语句删除数据,但是在某些情况下,使用DELETE可能会带来一些潜在的问题,特别是在大型数据库中. 下面我将详细介绍为什么在某些情况下MySQL不建议过度使用D ...
- 有什么巨好用Excel数据分析技巧?
当涉及Excel数据分析时,以下是一些非常实用的技巧和功能,供您参考.这里将为您提供关于数据整理.数据清洗.统计分析.可视化和高级分析等方面的技巧. 一.数据整理与清洗: 导入数据:使用 Excel ...
- 《最新出炉》系列初窥篇-Python+Playwright自动化测试-35-处理web页面定位toast-上篇
1.简介 在使用appium写app自动化的时候介绍toast的相关元素的定位,在Web UI测试过程中,也经常遇到一些toast(出现之后一闪而过,不留下一点点痕迹),那么这个toast我们这边如何 ...
- jmeter-逻辑处理器while
测试工具:jmeter 业务逻辑:A接口上传文件,B接口查询文件上传状态,如果状态不为4,需要再次查询(上传文件后,需要有短暂时间的识别,压测时并发大导致识别时间不可控)当为4时,跳出循环, 思路:增 ...
- Windows 项目的 CMakeLists 编写
前言: 项目一直是以 .sln 解决方案打开和处理的,上传到 github 也是需要将 sln 文件包括到项目里,不太优雅(虽然方便),毕竟现在开源项目基本都是使用 CMake 做跨平台编译 因为项目 ...
- Aop限流实现解决方案
01.限流 在业务场景中,为了限制某些业务的并发,造成接口的压力,需要增加限流功能. 02.限流的成熟解决方案 guava (漏斗算法 + 令牌算法) (单机限流) redis + lua + ip ...
- Find a Number (记忆化+BFS)
题目来自"2018-2019 ICPC, NEERC, Southern Subregional Contest",codeforces上放置了此题:Find a Number 题 ...