《最新出炉》系列入门篇-Python+Playwright自动化测试-53- 处理面包屑(详细教程)
1.简介
面包屑(Breadcrumb),又称面包屑导航(BreadcrumbNavigation)这个概念来自童话故事“汉赛尔和格莱特”,当汉赛尔和格莱特穿过森林时,不小心迷路了,但是他们发现沿途走过的地方都撒下了面包屑,让这些面包屑来帮助他们找到回家的路。所以,面包屑导航的作用是告诉访问者他们在网站中的位置以及如何返回,是在用户界面中的一种导航辅助。它是用户一个在程序或文件中确定和转移他们位置的一种方法。和童话故事里的一样,面包屑是一个网站或者app中为用户指引其所处位置的第二导航系统。浏览者能够了解这个网站的层级结构,并且便于浏览高层级的内容。
2.什么是面包屑导航?
面包屑就是我们经常看到的“主分类>一级分类>二级分类>三级分类>……>最终内容页面”这样的方式,一种表达内容归属的界面元素,如下图所示:
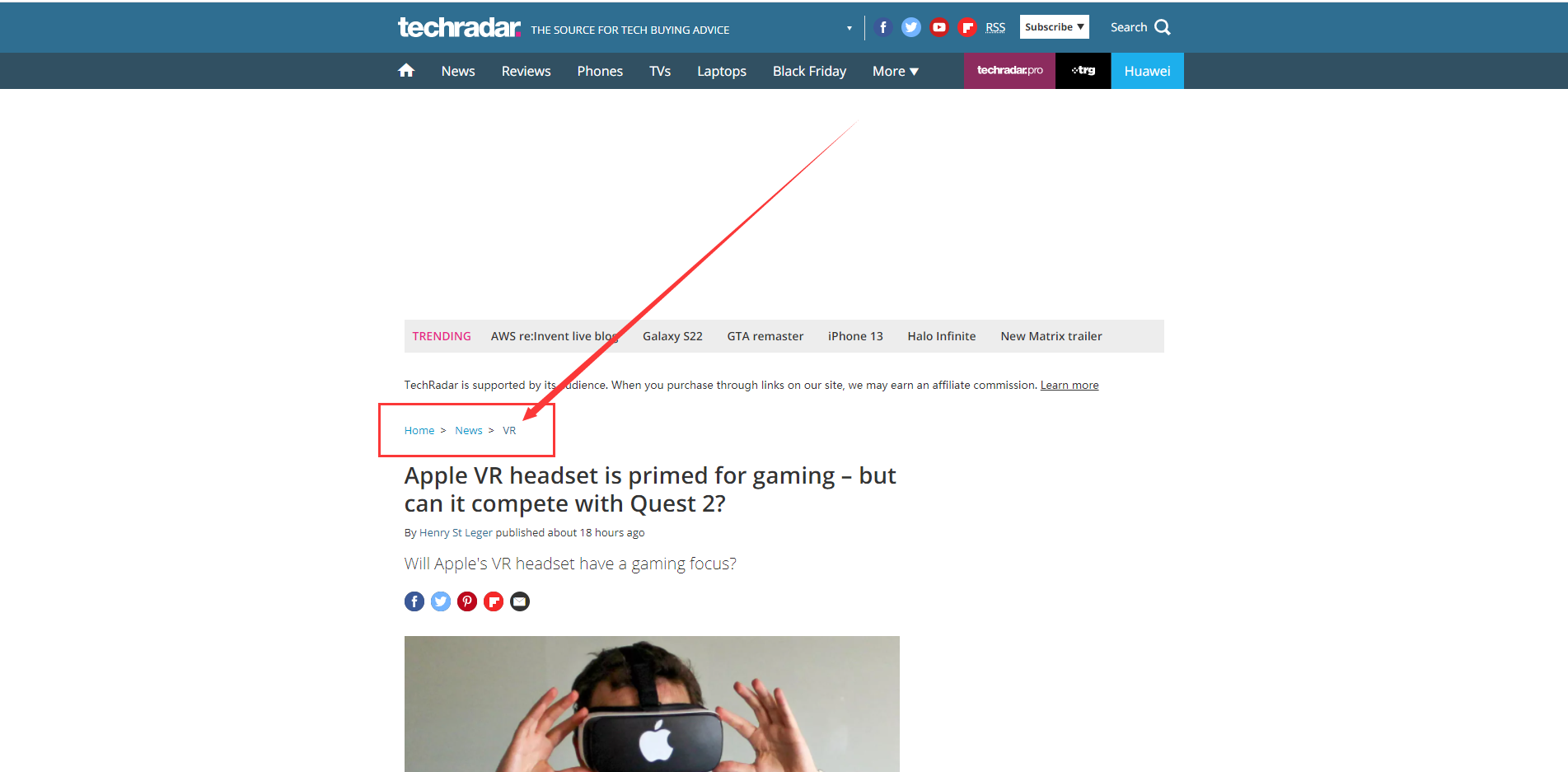
为了浏览体验,一般情况只有3级,首页>栏目页>内容页,3层目录结构可以让用户随时随地的找到自己所在的位置又能保证栏目分类后的各个栏目的权重不至于太分散。
3.为什么要用面包屑
面包屑被当作一种有效的视觉救援,指引用户在网站层级中所处的位置。以上这些特性使得用户通过面包屑导航获取到一大部分承上启下的信息资源,并且帮助用户找到以下问题的答案.
3.1它有哪些好处呢?
- 快速地知道我在哪儿
- 快速地知道我能去哪儿
- 减少操作次数
- 占用最少空间

4.测试场景
不仅在网页导航需要处理面包屑,在实际的测试脚本中,有可能需要处理面包屑。处理面包屑主要是获取其层级关系,以及获得当前的层级。一般来说当前层级都不会是链接,而父层级则基本是以链接,所以处理面包屑的思路就很明显了。找到面包屑所在的div或ul,然后再通过该div或ul找到下面的所有链接,这些链接就是父层级。最后不是链接的部分就应该是当前层级了。
5.项目实战
宏哥就参照网上的面包屑源码修改给一个小demo,进行自动化测试。
5.1demo页面的HTML代码
1.html代码:breadcrumb.html。如下:
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="content-type" content="text/html;charset=utf-8" />
<title>breadcrumb</title>
<link href="http://apps.bdimg.com/libs/bootstrap/3.3.0/css/bootstrap.min.css" rel="stylesheet" />
<script src="http://apps.bdimg.com/libs/jquery/2.0.0/jquery.min.js"></script>
<script src="http://apps.bdimg.com/libs/bootstrap/3.3.0/js/bootstrap.min.js"></script>
<style type="text/css">
.breadcrumb > li + li:before {
color: #CCCCCC;
content: "> ";
padding: 0 5px;
}
</style>
</head>
<body style="margin-top: 20px; margin-left: 20px;">
<h3>北京宏哥</h3>
<ol class="breadcrumb">
<li><a href="#">商品</a></li>
<li><a href="#">电子产品</a></li>
<li class="active">手机</li>
</ol>
</body>
<script src="http://netdna.bootstrapcdn.com/twitter-bootstrap/2.3.2/js/bootstrap.min.js"></script>
</html>
5.2代码设计
5.3参考代码
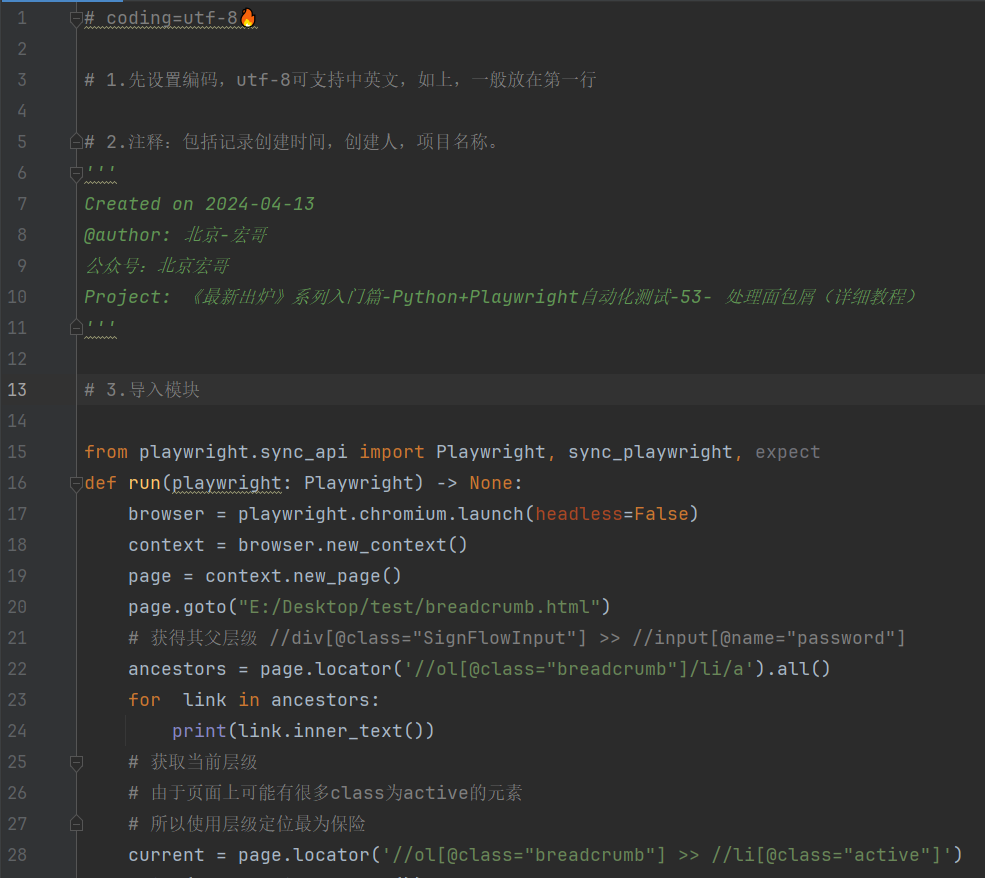
# coding=utf-8 # 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行 # 2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2024-04-13
@author: 北京-宏哥
公众号:北京宏哥(微信搜索:北京宏哥,关注宏哥,提前解锁更多测试干货!)
Project: 《最新出炉》系列入门篇-Python+Playwright自动化测试-53- 处理面包屑(详细教程)
''' # 3.导入模块 from playwright.sync_api import Playwright, sync_playwright, expect
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
page = context.new_page()
page.goto("E:/Desktop/test/breadcrumb.html")
# 获得其父层级 //div[@class="SignFlowInput"] >> //input[@name="password"]
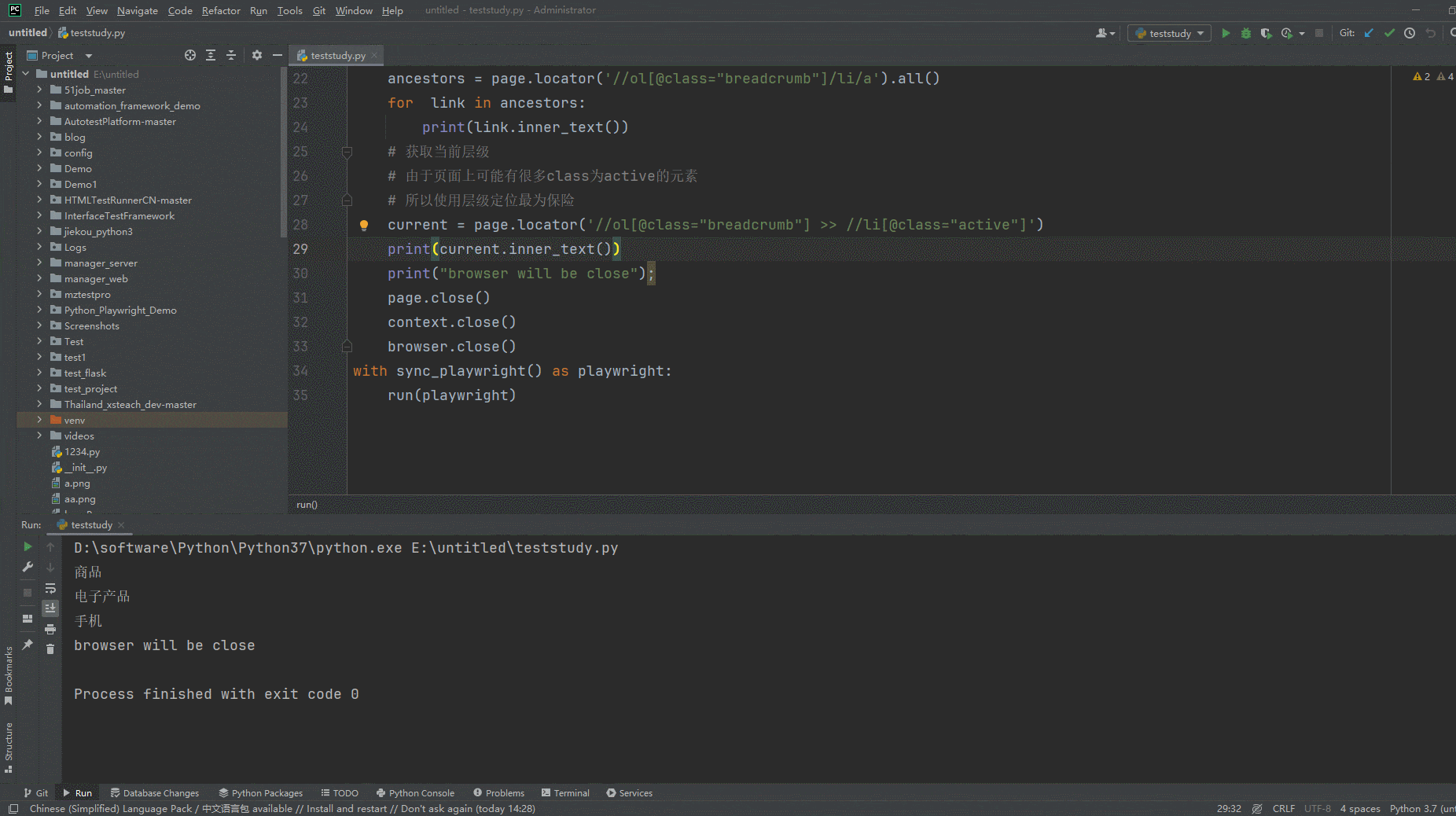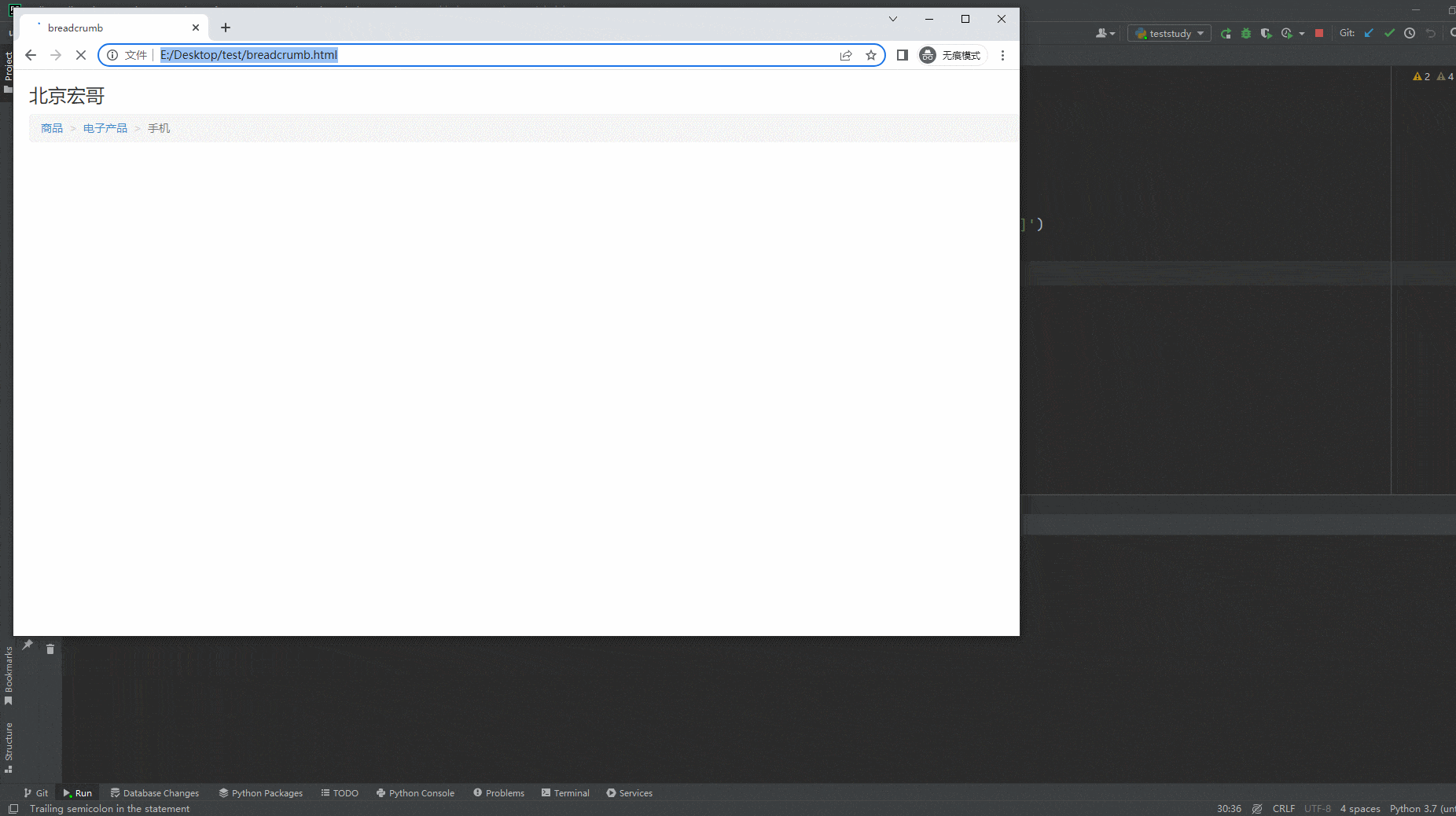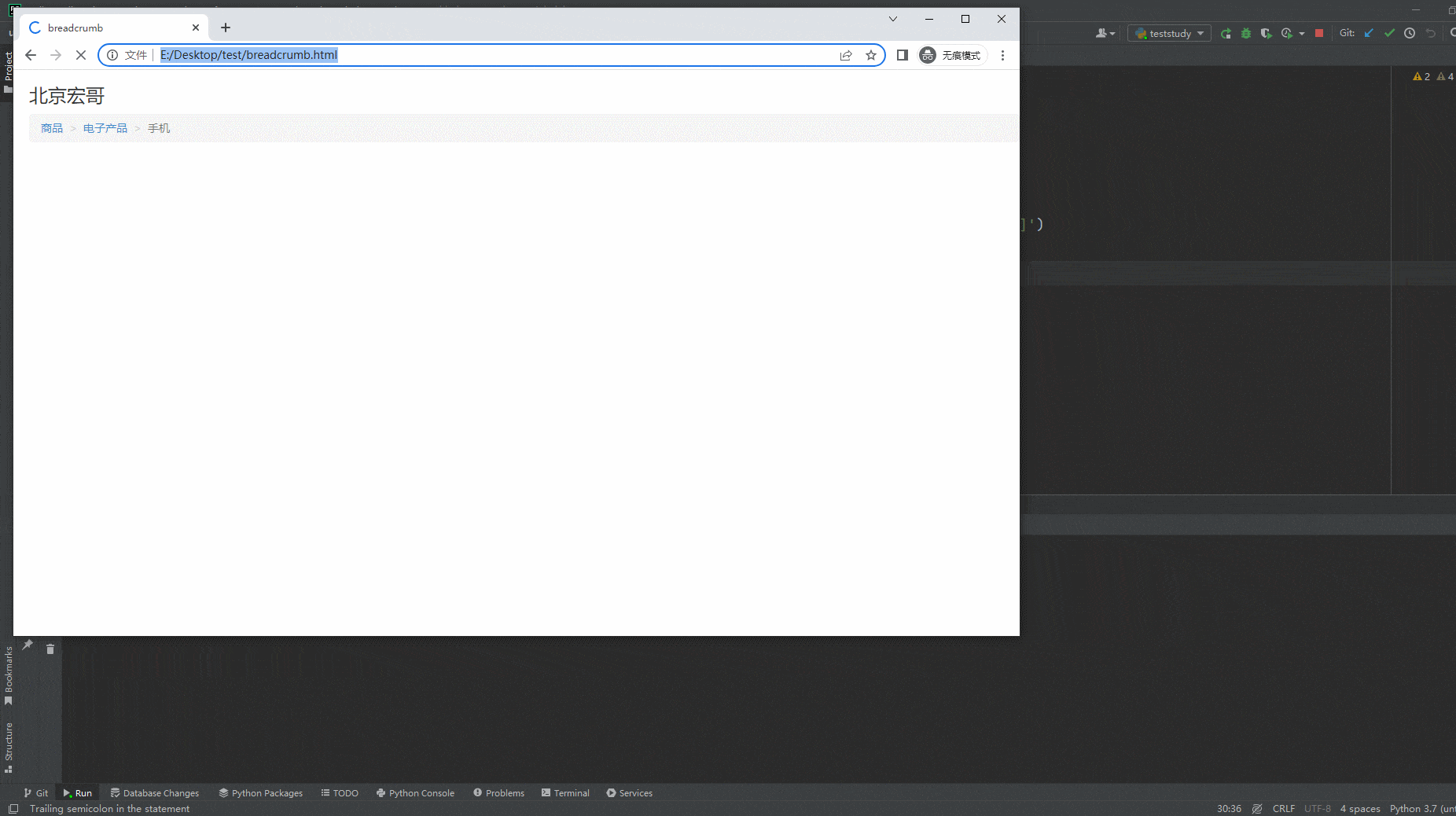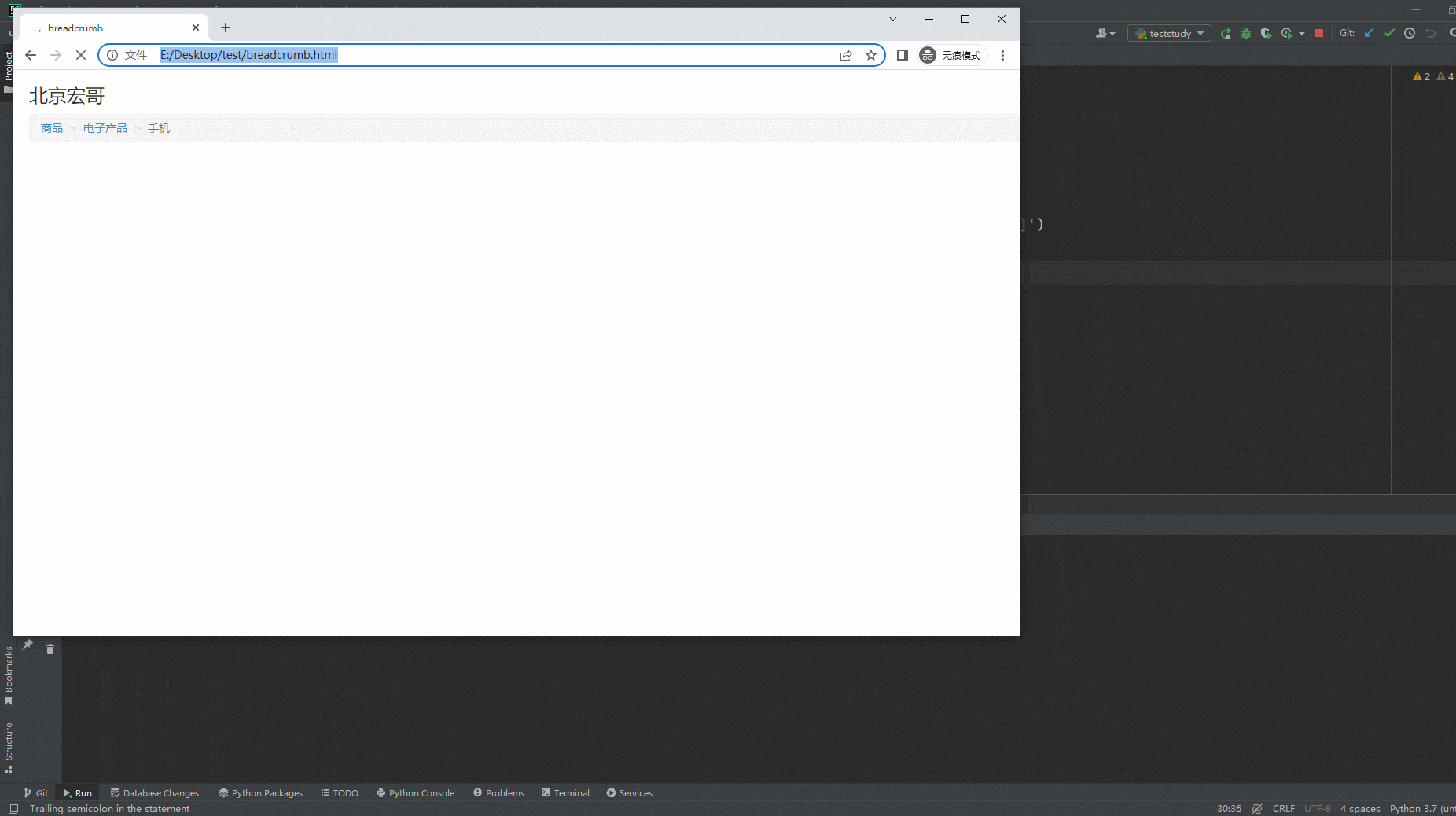
ancestors = page.locator('//ol[@class="breadcrumb"]/li/a').all()
for link in ancestors:
print(link.inner_text())
# 获取当前层级
# 由于页面上可能有很多class为active的元素
# 所以使用层级定位最为保险
current = page.locator('//ol[@class="breadcrumb"] >> //li[@class="active"]')
print(current.inner_text())
page.wait_for_timeout(1000)
print("browser will be close");
page.close()
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)
5.4运行代码
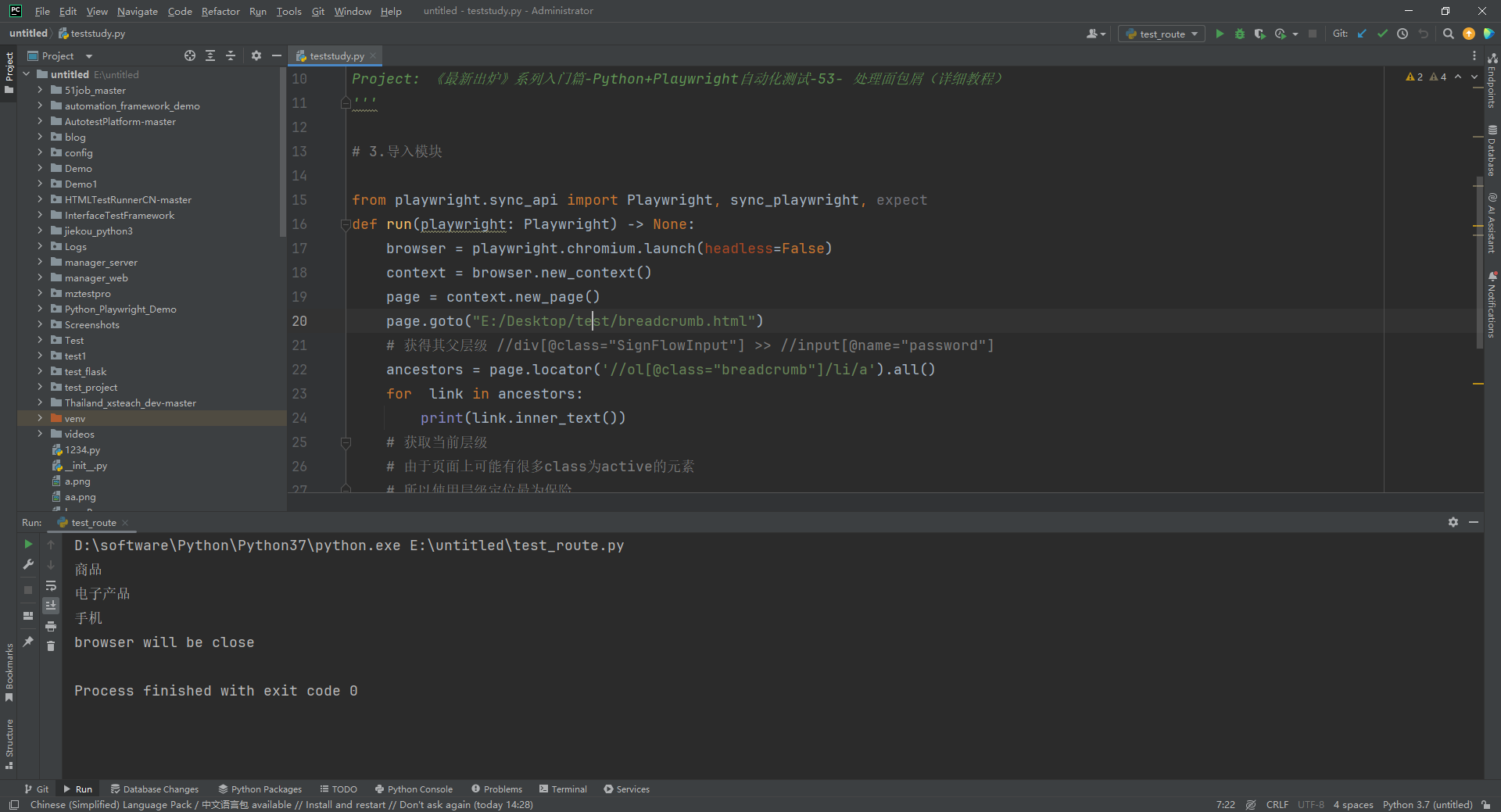
1.运行代码,右键Run'Test',就可以看到控制台输出,如下图所示:
2.运行代码后电脑端的浏览器的动作。如下图所示:
6.小结
因为现在这个导航比较流行,所以宏哥特地的拿出一篇文章的篇幅对其进行单独讲解一下,其实操作起来非常简单,只不过可能是之前没有遇到过,突然遇到了不知道一时之间如何处理,宏哥这里仅供小伙伴或者童鞋们参考学习。好了,时间不早了,今天就分享到这里!感谢您耐心的阅读。
《最新出炉》系列入门篇-Python+Playwright自动化测试-53- 处理面包屑(详细教程)的更多相关文章
- Spring实践系列-入门篇(一)
本文主要介绍了在本地搭建并运行一个Spring应用,演示了Spring依赖注入的特性 1 环境搭建 1.1 Maven依赖 目前只用到依赖注入的功能,故以下三个包已满足使用. <properti ...
- Google C++测试框架系列入门篇:第三章 基本概念
上一篇:Google C++测试框架系列入门篇:第二章 开始一个新项目 原始链接:Basic Concepts 词汇表 版本号:v_0.1 基本概念 使用GTest你肯定会接触到断言这个概念.断言是用 ...
- Google C++测试框架系列入门篇:第二章 开始一个新项目
上一篇:Google C++测试框架系列入门篇:第一章 介绍:为什么使用GTest? 原始链接:Setting up a New Test Project 词汇表 版本号:v_0.1 开始一个新项目 ...
- 《手把手教你》系列技巧篇(五十六)-java+ selenium自动化测试-下载文件-上篇(详细教程)
1.简介 前边几篇文章讲解完如何上传文件,既然有上传,那么就可能会有下载文件.因此宏哥就接着讲解和分享一下:自动化测试下载文件.可能有的小伙伴或者童鞋们会觉得这不是很简单吗,还用你介绍和讲解啊,不说就 ...
- 《手把手教你》系列技巧篇(五十七)-java+ selenium自动化测试-下载文件-下篇(详细教程)
1.简介 前边几篇文章讲解完如何上传文件,既然有上传,那么就可能会有下载文件.因此宏哥就接着讲解和分享一下:自动化测试下载文件.可能有的小伙伴或者童鞋们会觉得这不是很简单吗,还用你介绍和讲解啊,不说就 ...
- 《手把手教你》系列技巧篇(五十九)-java+ selenium自动化测试 - 截图三剑客 -上篇(详细教程)
1.简介 今天本来是要介绍远程测试的相关内容的,但是宏哥在操作服务器的时候干了件糊涂的事,事情经过是这样的:本来申请好的Windows服务器用来做演示的,可是服务器可能是局域网的,连百度都不能访问,宏 ...
- 《手把手教你》系列技巧篇(六十)-java+ selenium自动化测试 - 截图三剑客 -中篇(详细教程)
1.简介 前面我们介绍了Selenium中TakeScreenshot类来截图,得到的图片是浏览器窗口内的截图.有时候,只截浏览器窗口内的图是不够的,而且TakeScreenshot截图只针对浏览器的 ...
- 《手把手教你》系列技巧篇(六十一)-java+ selenium自动化测试 - 截图三剑客 -下篇(详细教程)
1.简介 按照计划宏哥今天将介绍java+ selenium自动化测试截图操作实现的第三种截图方法,也就是截图的第三剑客 - 截取某个元素(或者目标区域)的图片.在测试的过程中,有时候不需要截取整个屏 ...
- 转载:python + requests实现的接口自动化框架详细教程
转自https://my.oschina.net/u/3041656/blog/820023 摘要: python + requests实现的接口自动化框架详细教程 前段时间由于公司测试方向的转型,由 ...
- python + requests实现的接口自动化框架详细教程
前段时间由于公司测试方向的转型,由原来的web页面功能测试转变成接口测试,之前大多都是手工进行,利用postman和jmeter进行的接口测试,后来,组内有人讲原先web自动化的测试框架移驾成接口的自 ...
随机推荐
- 一个简易的录屏demo
MyScreenRecord.cpp //#define LOG_NODEBUG 0 #define LOG_TAG "myrecord" #include <signal. ...
- 一款功能强大的Python工具,一键打包神器,一次编写、多平台运行!
1.项目介绍 Briefcase是一个功能强大的工具,主要用于将Python项目转化为多种平台的独立本地应用.它支持多种安装格式,使得Python项目能够轻松打包并部署到不同的操作系统和设备上,如ma ...
- 系统镜像烧写及U-Boot编译
1 系统镜像烧写 1.1 工具介绍 烧写软件:使用NXP的MfgTool2工具烧写,工具路径:[正点原子]阿尔法Linux开发板(A盘)-基础资料\05.开发工具\04.正点原子MFG_TOOL出厂固 ...
- three.js高性能渲染室外场景
大家好,本文在相关文章的基础上,使用three.js渲染了高性能的室外场景,在移动端也有较好的性能,并给出了代码,分析了关键点,感谢大家~ 关键词:three.js.Web3D.WebGL.室外场景. ...
- SELinux(一) 简介
首发公号:Rand_cs 前段时间的工作遇到了一些关于 SELinux 的问题,初次接触不熟悉此概念,导致当时配置策略时束手束脚,焦头烂额,为此去系统的学习了下 SELinux 的东西.聊 SELin ...
- Ubuntu Server LTS 修改网卡ip地址、固定IP
Ubuntu Server LTS 修改网卡ip地址方式.固定IP. 18.04 之前版本通过修改/etc/network/interfaces 方式,18.04 版本开始通过netplan 方式: ...
- 编程语言界的丐帮 C#.NET FRAMEWORK 4.6 EF 连接MYSQL
1.nuget 引用 EntityFramework .和 MySql.Data.EntityFramework. EntityFramework 版本:6.4.4,MySql.Data.Entit ...
- 流程控制之case
1.case语句作用 case和if一样,都是用于处理多分支的条件判断 但是在条件较多的情况,if嵌套太多就不够简洁了 case语句就更简洁和规范了 2.case用法参考 常见用法就是如根据用户输入的 ...
- MoneyPrinterPlus:AI自动短视频生成工具,赚钱从来没有这么容易过
这是一个轻松赚钱的项目. 短视频时代,谁掌握了流量谁就掌握了Money! 所以给大家分享这个经过精心打造的MoneyPrinterPlus项目. 它可以:使用AI大模型技术,一键批量生成各类短视频. ...
- Kafka多维度调优
优化金字塔 应用程序层面 框架层面(Broker层面) JVM层面 操作系统层面 应用程序层面:应当优化业务代码合理使用kafka,合理规划主题,合理规划分区,合理设计数据结构: 框架层面:在不改动源 ...