轻松复现一张AI图片
轻松复现一张AI图片
现在有一个非常漂亮的AI图片,你是不是想知道他是怎么生成的?
今天我会交给大家三种方法,学会了,什么图都可以手到擒来了。
需要的软件
在本教程中,我们将使用AUTOMATIC1111 stable diffusion WebUI。这是一款流行且免费的软件。您可以在Windows、Mac或Google Colab上使用这个软件。
方法1: 通过阅读PNG信息从图像中获取提示
如果AI图像是PNG格式,你可以尝试查看提示和其他设置信息是否写在了PNG元数据字段中。
首先,将图像保存到本地。
打开AUTOMATIC1111 WebUI。导航到PNG信息页面。
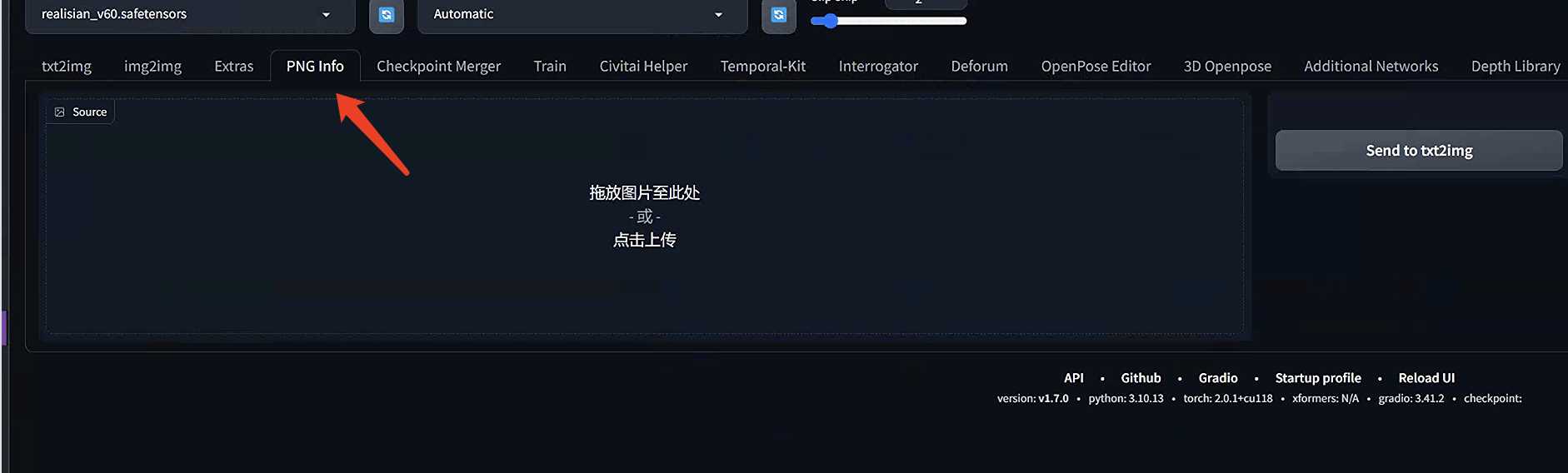
将图像拖放到左侧的源画布上。
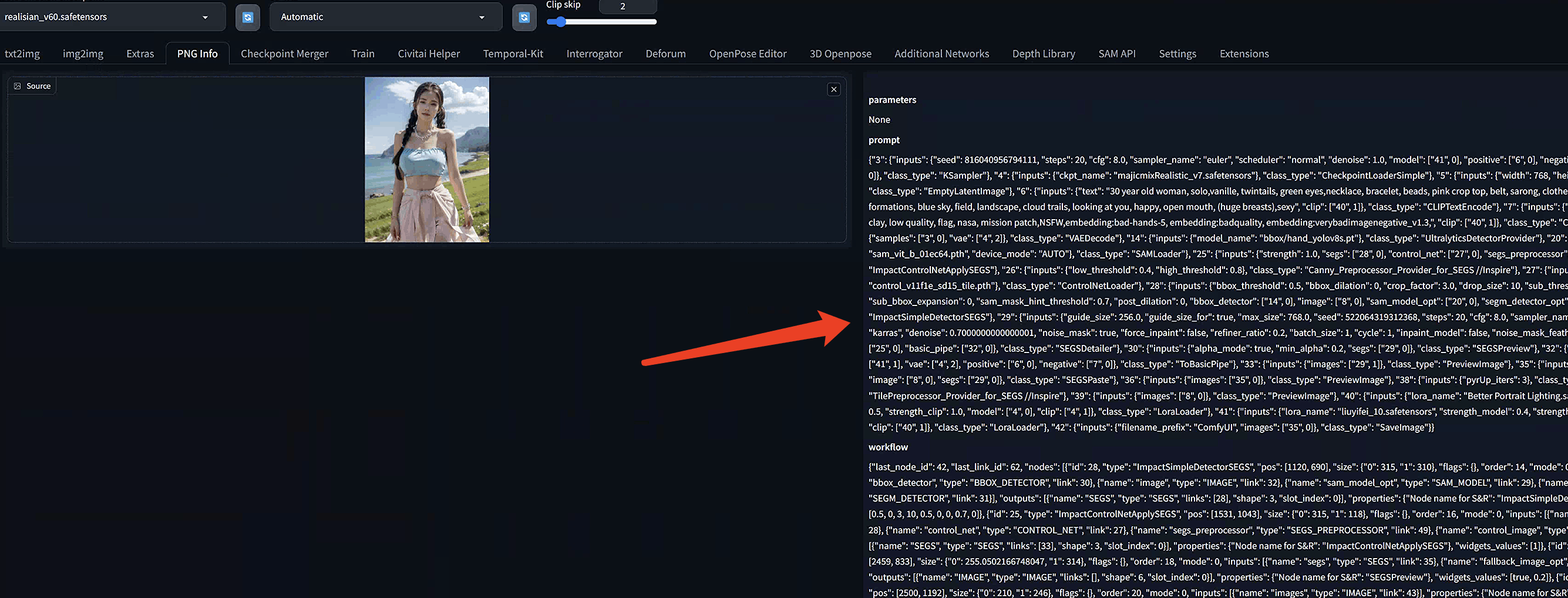
在右边你会找到关于提示词的有用信息。你还可以选择将提示和设置发送到txt2img、img2img、inpainting或者Extras页面进行放大。
方法2:使用CLIP interrogator从图像中推测Prompt
在处理图像信息时,我们常常会发现直接的方法并不总是有效。
有时候,信息并没有在最初就被记录在图像中,或者在后续的图像优化过程中被Web服务器去除。
也有可能这些信息并非由Stable diffusion这类AI技术生成。
面对这种情况,我们可以尝试使用CLIP interrogator作为替代方案。
CLIP interrogator是一种AI模型,它具备推测图像内容标题的能力。这个工具不仅适用于AI生成的图像,也能够应对各种类型的图像。通过这种方式,我们能够对图像内容进行更深入的理解和分析。
什么是CLIP?
CLIP(Contrastive Language–Image Pre-training)是一个神经网络,它将视觉概念映射到自然语言中。CLIP模型是通过大量的图像和图像信息对进行训练的。
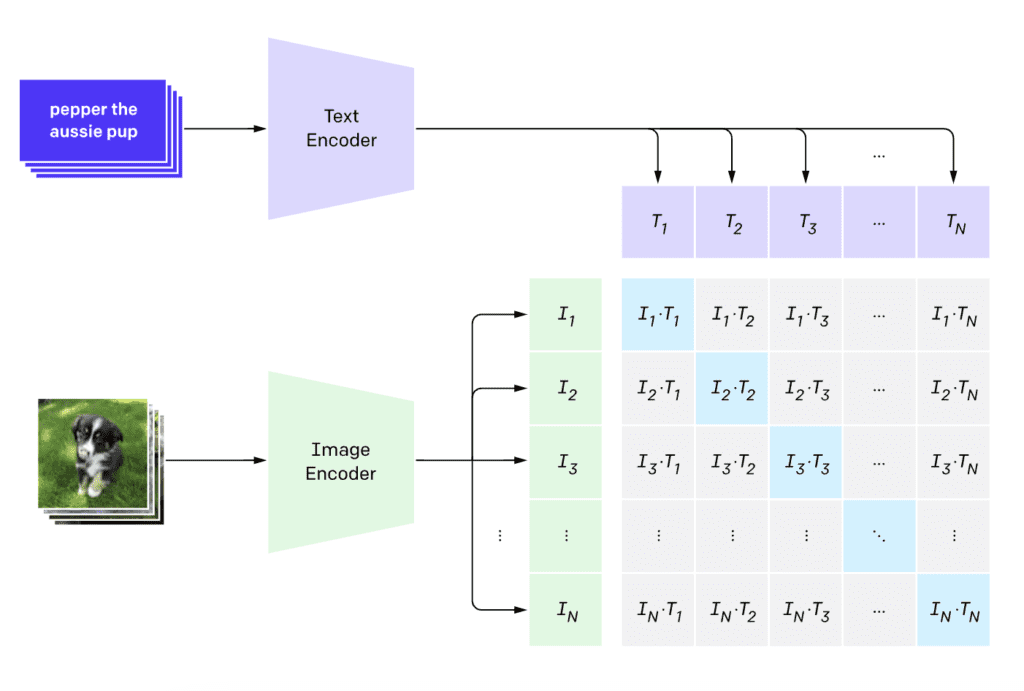
在我们的用例中,CLIP模型能够通过对给定图片的分析,推断出一个恰当的图片描述。
这个描述可以作为提示词,帮助我们进一步理解和描述图片的内容。CLIP模型通过学习大量的图像和相关文本数据,掌握了图像识别和语义理解的能力,因此它能够捕捉到图片中的关键元素,并将其转化为一个描述性的标题。
WebUI中自带的CLIP interrogator
如果你倾向于避免安装额外的扩展,可以选择使用AUTOMATIC1111提供的内置CLIP interrogator功能。
WebUI提供了两种识别图像信息的功能。一个是clip:这个功能底层基于BLIP模型,它是在论文《BLIP: 为统一的视觉语言理解和生成进行语言图像预训练》中由李俊楠以及其团队所提出的CLIP模型的一个变种。一个是DeepBooru, 这个比较适合识别二次元图片。
要利用这个内置的CLIP interrogator,你可以按照以下简单的步骤操作:
启动AUTOMATIC1111:首先,你需要打开AUTOMATIC1111的网站。
导航至img2img页面:在AUTOMATIC1111的界面中,找到并点击“img2img”这一选项。这是一个专门的页面,用于上传和处理图像。
上传图像到img2img画布:在这个页面上,你会找到一个用于上传图像的区域,通常被称为“画布”。点击上传按钮,选择你想要分析的图像文件,并将其上传到画布上。
上传之后在界面右边就可以找到两个interrogator工具了:
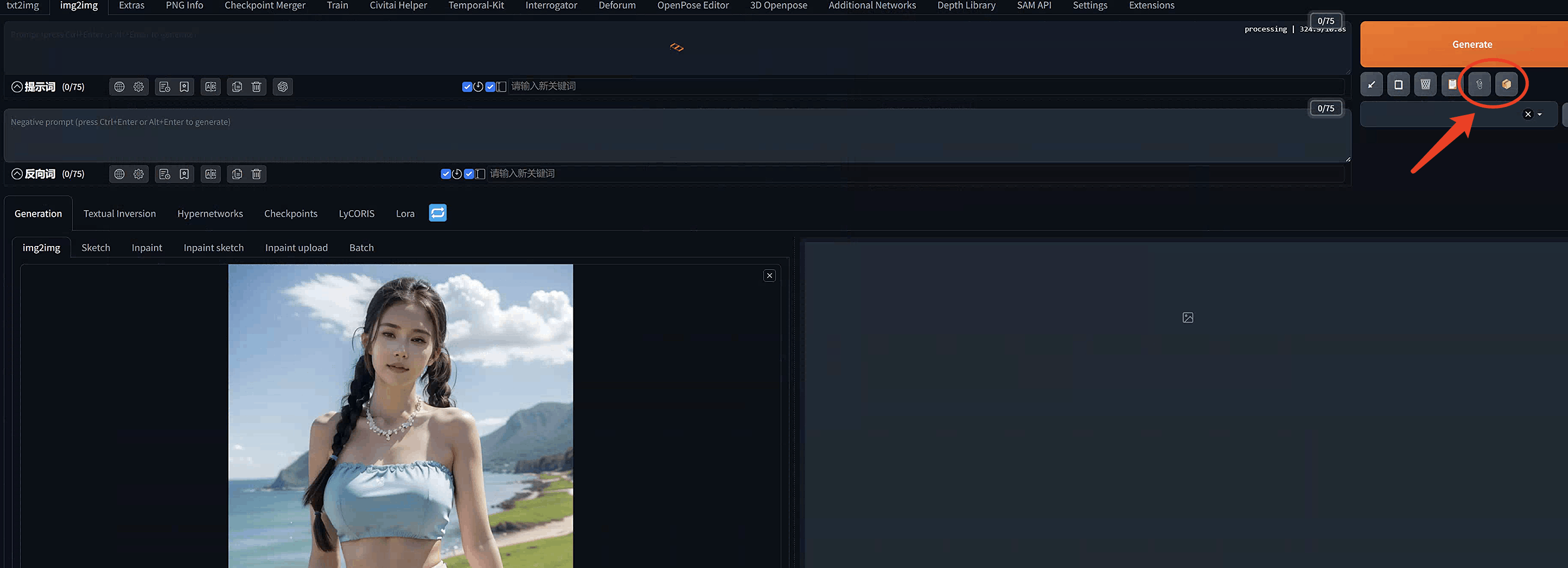
点击这两个按钮,就可以获得图像的描述信息了。
我们可以得到下面的信息:
a woman in a blue top and pink skirt standing on a hill near the ocean with a grassy area in the background,Ai Xuan,ocean,a statue,rococo,
我们用这段提示发到text2image中看看效果:

嗯....大体上还是有点相似的..... 因为图片跟我们的底模,种子还有采样多种因素有关。所以你想1比1复制,这个比较难。
CLIP扩展
如果您在使用AUTOMATIC1111的内置CLIP interrogator时发现其功能不足以满足您的需求,或者您希望尝试使用不同的CLIP模型来获得更多样化的结果,那么您可以考虑安装CLIP interrogator扩展。这个扩展将为您提供更多的选项和灵活性,以适应您特定的使用场景。
这个插件的下载地址如下:
https://github.com/pharmapsychotic/clip-interrogator-ext
要使用CLIP interrogator扩展。
打开AUTOMATIC1111 WebUI。
转到interrogator页面。
将图像上传到图像画布。
在CLIP模型下拉菜单中选择ViT-L-14-336/openai。这是Stable Diffusion v1.5中使用的语言嵌入模型。
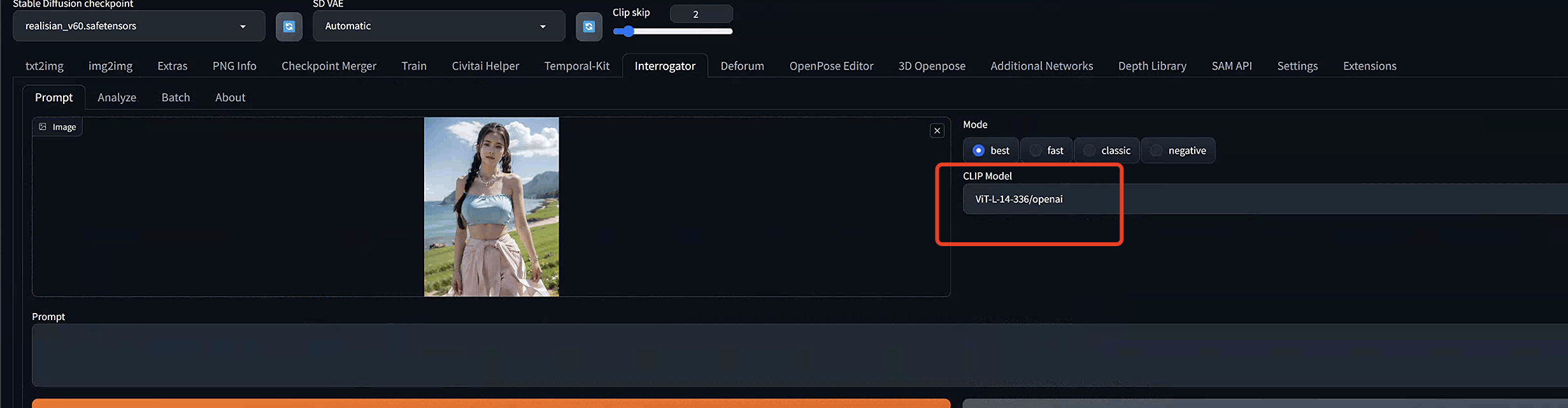
单击生成以生成提示。
对SDXL模型进行CLIP
如果你的目标是使用Stable Diffusion XL (SDXL)模型,那么我们需要选择不同的CLIP模型。
在“interrogator”页面上,你可以选择很多clip模型,如果要和SDXL模型一起工作的话,那么可以选择ViT-g-14/laion2b_s34b_b88k这个选项。
选择ViT-g-14/laion2b_s34b_b88k模型后,系统将会根据这个模型的特性生成相应的提示。你可以使用这个提示词作为SDXL的提示,从而可以更精确地生成与原始图像内容相符合的图像。
ViT-g-14/laion2b_s34b_b88k模型是一个基于Vision Transformer (ViT)架构的预训练模型,它在大型图像数据集laion2b上进行了训练,具有34亿个参数。这个模型在图像识别和理解方面表现出色,能够有效地捕捉图像的关键特征,并生成与原始图像内容紧密相关的提示。
通过这种方式,就可以确保在使用SDXL模型进行图像生成时,所得到的输出图像能够更好地反映原始图像的意图和风格。
总结一下
我们讲了三种方法来从图片信息中提取出对应的Prompt。
你应该首先尝试使用PNG信息方法。这种方法的优势在于,如果图像中包含了完整的元数据,那么您可以一次性获取到包括提示、使用的模型、采样方法、采样步骤等在内的所有必要信息。这对于重新创建图像非常有帮助。
如果PNG没有信息可用,那么可以考虑使用BLIP和CLIP模型。对于v1.5模型来说,ViT-g-14/laion2b_s34b_b88k模型可能是一个不错的选择,它不仅适用于SDXL模型,也可能在v1.5模型中表现出色。
另外,我们在构建提示词的时候,不要害怕对提示词进行修改。因为自动生成的提示可能并不完全准确,或者可能遗漏了一些图像中的关键对象。
所以需要根据自己的观察和需求,来修改提示词以确保它能准确地描述图像内容。这对于最终生成的图像质量和准确性至关重要。
同时,选择正确的checkpoint模型也非常关键。因为提示中可能并不总是包含正确的风格信息。
例如,如果您的目标是生成一个真实人物图像,那么你肯定不能选择一个卡通模型。
轻松复现一张AI图片的更多相关文章
- 1个小时!从零制作一个! AI图片识别WEB应用!
0 前言 近些年来,所谓的人工智能也就是AI. 在媒体的炒作下,变得神乎其神,但实际上,类似于图片识别的AI,其原理只不过是数学的应用. 线性代数,概率论,微积分(著名的反向传播算法). 大家觉得这些 ...
- Atitit.java图片图像处理attilax总结 BufferedImage extends java.awt.Image获取图像像素点image.getRGB(i, lineIndex); 图片剪辑/AtiPlatf_cms/src/com/attilax/img/imgx.javacutImage图片处理titit 判断判断一张图片是否包含另一张小图片 atitit 图片去噪算法的原理与
Atitit.java图片图像处理attilax总结 BufferedImage extends java.awt.Image 获取图像像素点 image.getRGB(i, lineIndex); ...
- Atitit 判断判断一张图片是否包含另一张小图片
Atitit 判断判断一张图片是否包含另一张小图片 1. keyword1 2. 模板匹配是在图像中寻找目标的方法之一(切割+图像相似度计算)1 3. 匹配效果2 4. 图片相似度的算法(感知哈希算 ...
- java图片处理——多张图片合成一张Gif图片并播放或Gif拆分成多张图片
1.多张jpg图合成gif动画 /** * 把多张jpg图片合成一张 * @param pic String[] 多个jpg文件名 包含路径 * @param newPic String 生成的gif ...
- 一张png图片 上面有多个图标,如何用CSS准确的知道其中某个图片的坐标
一张png图片 上面有多个图标,如何用CSS准确的知道其中某个图片的坐标 ,如下图 可以使用 background background:url(images/xx.png) 40px 10px n ...
- 【html+css3】在一张jpg图片上,显示多张透明的png图片
1.需求:在一个div布局里面放置整张jpg图片,然后在jpg图片上显示三张水平展示的透明png图片,且png外层用a标签包含菜单 2.效果图: 3.上图,底层使用蓝色jpg图片,[首页].[购物车] ...
- js将用户上传gif动图分解成多张帧图片
js将用户上传gif动图分解成多张帧图片 写在前面 工作中遇到一个这么一个需求:这是一个多图上传的场景,如果用户上传选择多张图片,则上传后直接展示多张图片,如果上传的图片是gif动图,则需要分解这张动 ...
- 用python爬取一张仓鼠图片
一. 找到一张仓鼠图片并复制一下它的url url='http://img.go007.com/2017/08/16/c407f5b732f4e748_2.jpg' 二. 调用urllib库 impo ...
- 小程序生成海报:通过 json 配置方式轻松制作一张海报图
背景 由于我们无法将小程序直接分享到朋友圈,但分享到朋友圈的需求又很多,业界目前的做法是利用小程序的 Canvas 功能生成一张带有二维码的图片,然后引导用户下载图片到本地后再分享到朋友圈.而小程序 ...
- 读取多张MNIST图片与利用BaseEstimator基类创建分类器
读取多张MNIST图片 在读取多张MNIST图片之前,我们先来看下读取单张图片如何实现 每张数字图片大小都为28 * 28的,需要将数据reshape成28 * 28的,采用最近邻插值,如下 def ...
随机推荐
- 浏览器的文件访问 API 入门(英文)- 资料
浏览器的文件访问 API 入门(英文)- 资料 浏览器现在提供了文件访问 API(File System Access API),允许网页 JS 脚本读写本地文件,本文是一个详细的介绍.另外,也可以参 ...
- FreeRTOS教程4 消息队列
1.准备材料 正点原子stm32f407探索者开发板V2.4 STM32CubeMX软件(Version 6.10.0) Keil µVision5 IDE(MDK-Arm) 野火DAP仿真器 XCO ...
- pfx文件导出pem和私钥,更换网站域名证书
openssl 路径: C:\Program Files\OpenSSL-Win64\bin -- 导出pem证书openssl pkcs12 -in C:\BackUp\Lightning\cert ...
- Android源码在线查看网站
一.aospxref http://aospxref.com/ 优点:更新速度快 缺点:历史版本较少 二.androidxref http://androidxref.com/ 优点:历史版本较多 缺 ...
- Linux 运维工程师面试真题-2-Linux 命令及文件操作
Linux 运维工程师面试真题-2-Linux 命令及文件操作 1.在/tmp/目录下创建 test.txt 文件,内容为: Hello,World! ,用一个命令写出来. 2.给 test.txt ...
- View之invalidate,requestLayout,postInvalidate
目录介绍 01.invalidate,requestLayout,postInvalidate区别 02.invalidate深入分析 03.postInvalidate深入分析 04.request ...
- 记录转载:Vite多环境配置--让项目拥有更高定制化能力
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 业务背景 近些年来,随着前端工程架构发展,使得前端项目中也能拥有如后端工程的模块能力.正所谓 "能力(越)越大(来),责任(越) ...
- 《Go程序设计语言》学习笔记之slice
<Go程序设计语言>学习笔记之slice 一. 环境 Centos8.5, go1.17.5 linux/amd64 二. 概念 1) slice 表示一个拥有相同类型元素的可变长度的序列 ...
- Dynamic ReLU:微软推出提点神器,可能是最好的ReLU改进 | ECCV 2020
论文提出了动态ReLU,能够根据输入动态地调整对应的分段激活函数,与ReLU及其变种对比,仅需额外的少量计算即可带来大幅的性能提升,能无缝嵌入到当前的主流模型中 来源:晓飞的算法工程笔记 公众号 ...
- KingbaseES V8R3 集群运维系列 -- failover切换后集群自动恢复
案例说明: KingbaseES V8R3集群默认在触发failover切换后,为保证数据安全,原主库需要通过人工介入后,恢复为新的备库加入到集群.在无人值守的现场环境,需要在触发failover ...