你的Parquet该升级了:IOException: totalValueCount == 0问题定位之旅
摘要:使用Spark SQL进行ETL任务,在读取某张表的时候报错:“IOException: totalValueCount == 0”,但该表在写入时,并没有什么异常。
本文分享自华为云社区《你的Parquet该升级了:IOException: totalValueCount == 0问题定位之旅》,原文作者:wzhfy 。
1. 问题描述
使用Spark SQL进行ETL任务,在读取某张表的时候报错:“IOException: totalValueCount == 0”,但该表在写入时,并没有什么异常。
2. 初步分析
该表的结果是由两表join后生成。经分析,join的结果产生了数据倾斜,且倾斜key为null。Join后每个task写一个文件,所以partition key为null的那个task将大量的null值写入了一个文件,null值个数达到22亿。
22亿这个数字比较敏感,正好超过int最大值2147483647(21亿多)。因此,初步怀疑parquet在写入超过int.max个value时有问题。
【注】本文只关注大量null值写入同一个文件导致读取时报错的问题。至于该列数据产生如此大量的null是否合理,不在本文讨论范围之内。
3. Deep dive into Parquet (version 1.8.3,部分内容可能需要结合Parquet源码进行理解)
入口:Spark(Spark 2.3版本) -> Parquet
Parquet调用入口在Spark,所以从Spark开始挖掘调用栈。
InsertIntoHadoopFsRelationCommand.run()/SaveAsHiveFile.saveAsHiveFile() -> FileFormatWriter.write()
这里分几个步骤:
- 启动作业前,创建outputWriterFactory: ParquetFileFormat.prepareWrite()。这里会设置一系列与parquet写文件有关的配置信息。其中主要的一个,是设置WriteSupport类:ParquetOutputFormat.setWriteSupportClass(job, classOf[ParquetWriteSupport]),ParquetWriteSupport是Spark自己定义的类。
- 在executeTask() -> writeTask.execute()中,先通过outputWriterFactory创建OutputWriter (ParquetOutputWriter):outputWriterFactory.newInstance()。
- 对于每行记录,使用ParquetOutputWriter.write(InternalRow)方法依次写入parquet文件。
- Task结束前,调用ParquetOutputWriter.close()关闭资源。
3.1 Write过程

在ParquetOutputWriter中,通过ParquetOutputFormat.getRecordWriter构造一个RecordWriter(ParquetRecordWriter),其中包含了:
- prepareWrite()时设置的WriteSupport:负责转换Spark record并写入parquet结构
- ParquetFileWriter:负责写入文件
ParquetRecordWriter中,其实是把write操作委托给了一个internalWriter(InternalParquetRecordWriter,用WriteSupport和ParquetFileWriter构造)。
现在让我们梳理一下,目前为止的大致流程为:
SingleDirectoryWriteTask/DynamicPartitionWriteTask.execute
-> ParquetOutputWriter.write -> ParquetRecordWriter.write -> InternalParquetRecordWriter.write
接下来,InternalParquetRecordWriter.write里面,就是三件事:

(1)writeSupport.write,即ParquetWriteSupport.write,里面分三个步骤:
- MessageColumnIO.MessageColumnIORecordConsumer.startMessage;
- ParquetWriteSupport.writeFields:写入一行中各个列的值,null值除外;
- MessageColumnIO.MessageColumnIORecordConsumer.endMessage:针对第二步中的missing fields写入null值。
ColumnWriterV1.writeNull -> accountForValueWritten:
1) 增加计数器valueCount (int类型)
2) 检查空间是否已满,需要writePage - 检查点1
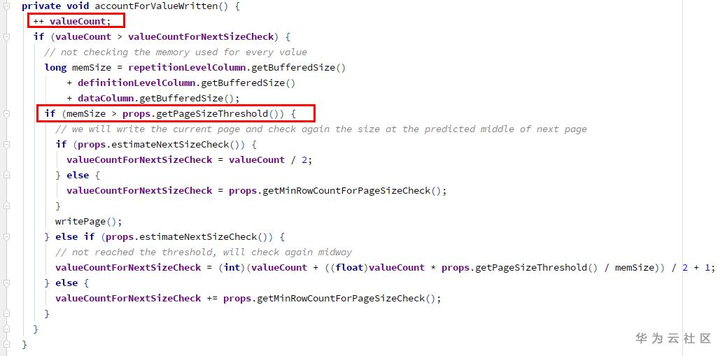
(2)增加计数器recordCount(long类型)
(3)检查block size,是否需要flushRowGroupToStore - 检查点2
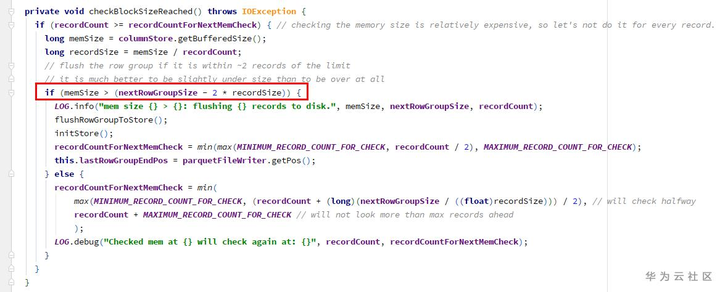
由于写入的值全是null,在1、2两个检查点的memSize都为0,所以不会刷新page和row group。导致的结果就是,一直在往同一个page里增加null值。而ColumnWriterV1的计数器valueCount是int类型,当超过int.max时,溢出,变为了一个负数。
因此,只有当调用close()方法时(task结束时),才会执行flushRowGroupToStore:
ParquetOutputWriter.close -> ParquetRecordWriter.close
-> InternalParquetRecordWriter.close -> flushRowGroupToStore
-> ColumnWriteStoreV1.flush -> for each column ColumnWriterV1.flush
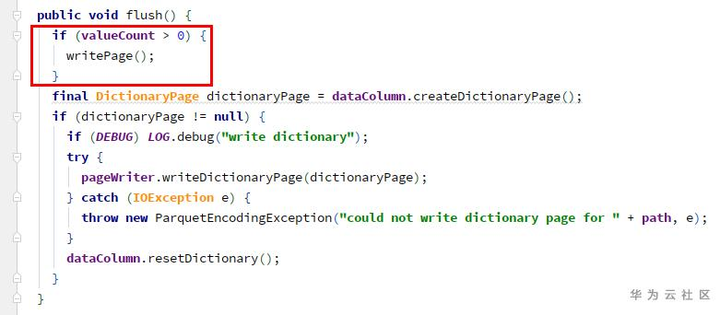
由于valueCount溢出为负,此处也不会写page。
因为未调用过writePage,所以此处的totalValueCount一直为0。
ColumnWriterV1.writePage -> ColumnChunkPageWriter.writePage -> 累计totalValueCount
在write结束时,InternalParquetRecordWriter.close -> flushRowGroupToStore -> ColumnChunkPageWriteStore.flushToFileWriter -> for each column ColumnChunkPageWriter.writeToFileWriter:
- ParquetFileWriter.startColumn:totalValueCount赋值给currentChunkValueCount
- ParquetFileWriter.writeDataPages
- ParquetFileWriter.endColumn:currentChunkValueCount(为0)和其他元数据信息构造出一个ColumnChunkMetaData,相关信息最终会被写入文件。
3.2 Read过程
同样以Spark为入口,进行查看。
初始化阶段:ParquetFileFormat.BuildReaderWithPartitionValues -> VectorizedParquetRecordReader.initialize -> ParquetFileReader.readFooter -> ParquetMetadataConverter.readParquetMetadata -> fromParquetMetadata -> ColumnChunkMetaData.get,其中包含valueCount(为0)。
读取时:VectorizedParquetRecordReader.nextBatch -> checkEndOfRowGroup:
1) ParquetFileReader.readNextRowGroup -> for each chunk, currentRowGroup.addColumn(chunk.descriptor.col, chunk.readAllPages())
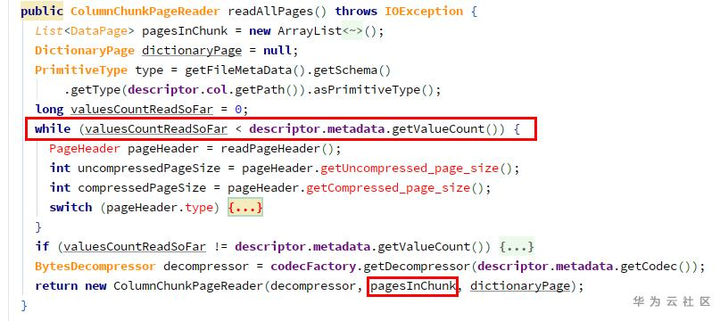
由于getValueCount为0,所以pagesInChunk为空。
2)构造ColumnChunkPageReader:
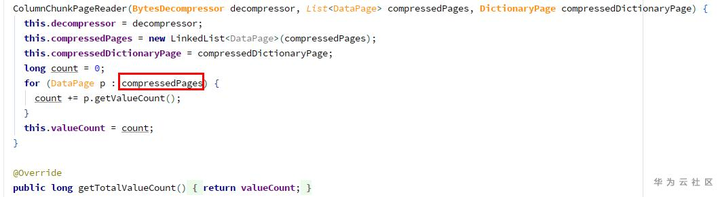
由于page列表为空,所以totalValueCount为0,导致在构造VectorizedColumnReader时报了问题中的错误。
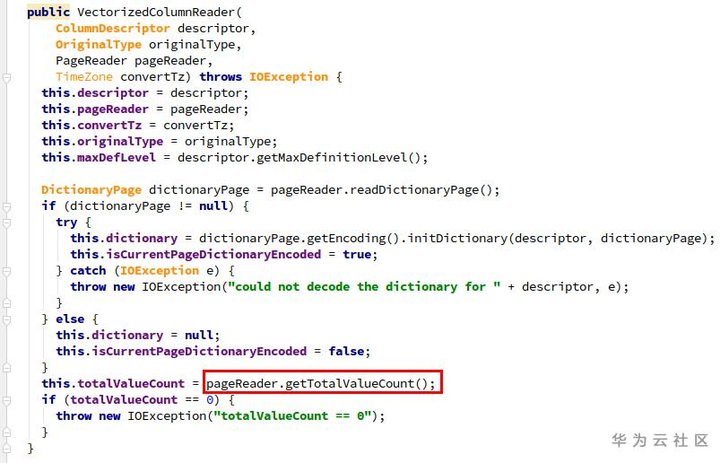
4. 解决方法:Parquet升级(version 1.11.1)
在新版本中,ParquetWriteSupport.write ->
MessageColumnIO.MessageColumnIORecordConsumer.endMessage ->
ColumnWriteStoreV1(ColumnWriteStoreBase).endRecord:
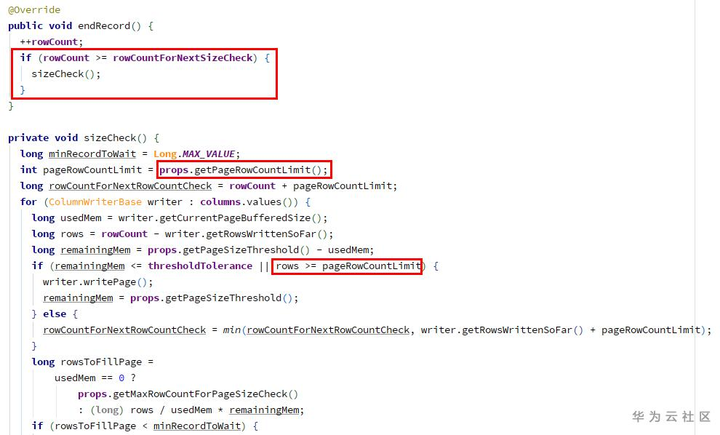
在endRecord中增加了每个page最大记录条数(默认2w条)的属性和检查逻辑,超出限制时会writePage,使得ColumnWriterV1的valueCount不会溢出(每次writePage后会清零)。
而对比老版本1.8.3中,ColumnWriteStoreV1.endRecord为空函数。

附:Parquet中的一个小trick
Parquet中为了节约空间,当一个long类型的值,在一定范围内时,会使用int来存储,其方法如下:
- 判断是否可以用int存储:

- 如果可以,用IntColumnChunkMetaData代替LongColumnChunkMetaData,构造时转换:

- 使用时,再转回来,IntColumnChunkMetaData.getValueCount -> intToPositiveLong():

普通的int范围是 -2^31 ~ (2^31 - 1),由于元数据信息(如valueCount等)都是非负整数,那么实际只能存储0 ~ (2^31 - 1) 范围的数。而用这种方法,可以表示0 ~ (2^32 - 1) 范围的数,表达范围也大了一倍。
附件:可用于复现的测试用例代码(依赖Spark部分类,可置于Spark工程中运行)
测试用例代码.txt 1.88KB
你的Parquet该升级了:IOException: totalValueCount == 0问题定位之旅的更多相关文章
- Hadoop-1.2.1 升级到Hadoop-2.6.0 HA
Hadoop-1.2.1到Hadoop-2.6.0升级指南 作者 陈雪冰 修改日期 2015-04-24 版本 1.0 本文以hadoop-1.2.1升级到hadoop-2.6.0 Z ...
- DPA 9.1.85 升级到DPA 10.0.352流程
SolarWinds DPA的升级其实是一件非常简单的事情,这里介绍一下从DPA 9.1.95升级到 DPA 10.0.352版本的流程.为什么要升级呢? DPA给用户发的邮件已经写的非常清楚了(如下 ...
- jackson2.5.0升级到2.7.0
开发环境:spring-mvc4.1.7.jackson2.7.0 问题描述:项目中将原来的jackson2.5.0升级到2.7.0,导致服务调用出错. mvc相关的配置文件如下: <?xml ...
- ORACLE 10升级到10.2.0.5 Patch Set遇到的内核参数检测失败问题
在测试ORACLE 10.2.0.4升级到10.2.0.5 Patch Set的过程中,遇到一个内核参数检查失败的问题,具体错误信息如下所示 实验环境: 操作系统:Oracle Linux Ser ...
- 探索Oracle数据库升级6 11.2.0.4.3 Upgrade12c(12.1.0.1)
探索Oracle数据库升级6 11.2.0.4.3 Upgrade12c(12.1.0.1) 一.前言: Oracle 12c公布距今已经一年有余了,其最大亮点是一个能够插拔的数据库(PD ...
- linux内核升级(ubuntu12.04从3.13.0升级到3.4.0 )
花了一天的时间,终于把ubuntu12.04 的linux内核版本从3.13.0升级到3.4.0 升级后,系统更加稳定.具体步骤:# wget http://www.kernel.org/pub/li ...
- mac版chrome升级到Version 65.0.3325.18后无法打开百度bing搜狗
mac版本chrome升级到Version 65.0.3325.18后发现突然无法访问百度,搜狗,bing,神马等一系列的国内搜索引擎网站.连百度的儿子们比如知道,百度百科都无法访问. 1.首先想到的 ...
- 【Android Studio安装部署系列】三十一、从Android studio3.0.0升级到Android studio3.0.1
版权声明:本文为HaiyuKing原创文章,转载请注明出处! 概述 突然想要升级到较高版本.要跟随潮流嘛,不然就落后了. 下载IDE http://www.wanandroid.com/tools/i ...
- CoreProfiler升级到.NetStandard 2.0
致所有感兴趣的朋友: CoreProfiler和相应的Sample项目cross-app-profiling-demo都已经升级到.NetStandrard 2.0和.NetCore 2.0. 有任何 ...
- maven私库nexus2.11.4迁移升级到nexus3.12.0
nexus简介 nexus是一个强大的maven仓库管理器,它极大的简化了本地内部仓库的维护和外部仓库的访问. nexus是一套开箱即用的系统不需要数据库,它使用文件系统加Lucene来组织数据 .n ...
随机推荐
- [ABC201E] Xor Distances 题解
Xor Distances 题目大意 给定一颗带边权无根树,定义 \(\text{dis}(i,j)\) 表示 \(i,j\) 两点在树上的最短路径的边权的异或和.求: \[\sum_{i=1}^n\ ...
- 自然数的拆分问题(lgP2404)
dfs.又调了一个小时,窝果然菜 需要传递的变量分别为目前搜索的数字:目前所有选中数字的和:目前所选数字个数. 见注释. #include<bits/stdc++.h> using nam ...
- Python 继承和子类示例:从 Person 到 Student 的演示
继承允许我们定义一个类,该类继承另一个类的所有方法和属性.父类是被继承的类,也叫做基类.子类是从另一个类继承的类,也叫做派生类. 创建一个父类 任何类都可以成为父类,因此语法与创建任何其他类相同: 示 ...
- 一些 trick 和思考收获
2023.1.7 P1117 优秀的拆分 对于一眼看上去只能直接求解的题可以设置一些节点变为求每个节点的贡献 *2023 7.24 补充:这个 trick 也被称为设置关键点,通常用于区间长度固定或是 ...
- 一文讲透DevOps理论体系的演进
一.前言 当前,我国处于以信息化.数字化.网络化.智能化为特征的科技变革浪潮中,企业数字化转型大势所趋,那么作为支撑企业IT运转的运营体系也在向多元方向发展,比如DevOps(研发运营一体化).AIO ...
- el-table 多表格弹窗嵌套数据显示异常错乱问题
1.业务背景 使用vue+element开发报表功能时,需要列表上某列的超链接按钮弹窗展示,在弹窗的el-table列表某列中再次使用超链接按钮点开弹窗,以此类推多表格弹窗嵌套,本文以弹窗两次为例 最 ...
- 【算法】状态之美,TCP/IP状态转换探索
最近城市里甲流肆虐,口罩已经成为了出门必备的物品.小悦也不得不开始采取防护措施,上下班过程中,将口罩戴起来以保护自己不受病毒的侵害. 每天下班后,小悦总是喜欢投入到自己的兴趣爱好中,她热衷于翻阅与IT ...
- IDEA安装与配置教程
一.下载并安装IDEA 1.下载 1.官网: 下载 IntelliJ IDEA (这里以Windows系统为例,其他系统类似) 2.安装 1.下载完成后,直接点击安装包安装,即可. 2.开始安装,然后 ...
- Gson和fastJson应用场景
如果有性能上面的要求可以使用Gson将bean转换json确保数据的正确,使用FastJson将Json转换Bean 二.Google的Gson包的使用简介. Gson类:解析json的最基础的工 ...
- 快速认识,前端必学编程语言:JavaScript
JavaScript是构建Web应用必学的一门编程语言,也是最受开发者欢迎的热门语言之一.所以,如果您还不知道JavaScript的用处.特点的话,赶紧补充一下这块基础知识. JavaScript 是 ...