关于飞桨UIE等模型预测推理时间很久的问题分析以及解决,蒸馏剪枝部署问题解决
1.关于飞桨UIE等模型预测推理时间很久的问题分析以及解决
1.1.原因分析
用uie做实体识别,Taskflow预测的时间与schema内的实体类别数量成正比,schema里面有多少个实体类别
实体识别中每次取一个类别作为prompt与原文本拼接作为模型的输入,所以schema中有多个实体类别时会预测多次。
1.2.解决方案
1.使用tiny系列模型进行提速
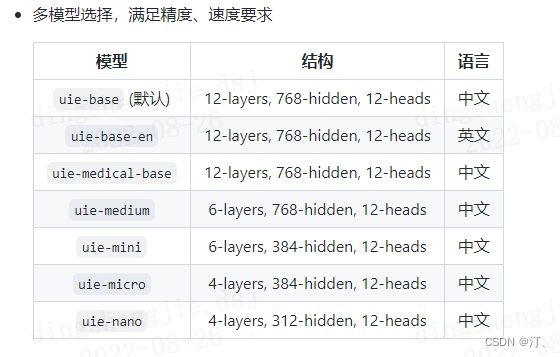
- 更多配置
from paddlenlp import Taskflow
ie = Taskflow('information_extraction',
schema="",
batch_size=1,
model='uie-base',
position_prob=0.5,
precision='fp16')schema:定义任务抽取目标,可参考开箱即用中不同任务的调用示例进行配置。batch_size:批处理大小,请结合机器情况进行调整,默认为1。model:选择任务使用的模型,默认为uie-base,可选有uie-base,uie-medium,uie-mini,uie-micro,uie-nano和uie-medical-base,uie-base-en。position_prob:模型对于span的起始位置/终止位置的结果概率在0~1之间,返回结果去掉小于这个阈值的结果,默认为0.5,span的最终概率输出为起始位置概率和终止位置概率的乘积。precision:选择模型精度,默认为fp32,可选有fp16和fp32。fp16推理速度更快。如果选择fp16,请先确保机器正确安装NVIDIA相关驱动和基础软件,确保CUDA>=11.2,cuDNN>=8.1.1,初次使用需按照提示安装相关依赖。其次,需要确保GPU设备的CUDA计算能力(CUDA Compute Capability)大于7.0,典型的设备包括V100、T4、A10、A100、GTX 20系列和30系列显卡等。更多关于CUDA Compute Capability和精度支持情况请参考NVIDIA文档:GPU硬件与支持精度对照表。
参考链接:https://github.com/PaddlePaddle/PaddleNLP/issues/3022
2. 问题:在使用PaddleSlim进行剪枝后,生成的是静态图,有什么办法可以再加载进模型进行训练,或者像正常训练完model一样进行预测
裁剪后的模型会导出为静态图模型,无法再通过动态图的方式加载再训练。预测的话可以在静态图下或者使用PaddleInference进行预测,这样可以直接加载.pdmodel, .pdiparams进行推理。预测可以参考
PaddleNLP/model_zoo/ernie-3.0/deploy/python at develop · PaddlePaddle/PaddleNLP · GitHub
关于飞桨UIE等模型预测推理时间很久的问题分析以及解决,蒸馏剪枝部署问题解决的更多相关文章
- NLP(十八)利用ALBERT提升模型预测速度的一次尝试
前沿 在文章NLP(十七)利用tensorflow-serving部署kashgari模型中,笔者介绍了如何利用tensorflow-serving部署来部署深度模型模型,在那篇文章中,笔者利用k ...
- 基于GPS数据建立隐式马尔可夫模型预测目的地
<Trip destination prediction based on multi-day GPS data>是一篇在2019年,由吉林交通大学团队发表在elsevier期刊上的一篇论 ...
- TensorFlow从1到2(七)线性回归模型预测汽车油耗以及训练过程优化
线性回归模型 "回归"这个词,既是Regression算法的名称,也代表了不同的计算结果.当然结果也是由算法决定的. 不同于前面讲过的多个分类算法或者逻辑回归,线性回归模型的结果是 ...
- 修正剑桥模型预测-用python3.4
下面是预测结果: #!/usr/bin/env python # -*- coding:utf-8 -*- # __author__ = "blzhu" ""& ...
- 时间序列深度学习:seq2seq 模型预测太阳黑子
目录 时间序列深度学习:seq2seq 模型预测太阳黑子 学习路线 商业中的时间序列深度学习 商业中应用时间序列深度学习 深度学习时间序列预测:使用 keras 预测太阳黑子 递归神经网络 设置.预处 ...
- 时间序列深度学习:状态 LSTM 模型预测太阳黑子
目录 时间序列深度学习:状态 LSTM 模型预测太阳黑子 教程概览 商业应用 长短期记忆(LSTM)模型 太阳黑子数据集 构建 LSTM 模型预测太阳黑子 1 若干相关包 2 数据 3 探索性数据分析 ...
- 【R实践】时间序列分析之ARIMA模型预测___R篇
时间序列分析之ARIMA模型预测__R篇 之前一直用SAS做ARIMA模型预测,今天尝试用了一下R,发现灵活度更高,结果输出也更直观.现在记录一下如何用R分析ARIMA模型. 1. 处理数据 1.1. ...
- tensorflow学习笔记——模型持久化的原理,将CKPT转为pb文件,使用pb模型预测
由题目就可以看出,本节内容分为三部分,第一部分就是如何将训练好的模型持久化,并学习模型持久化的原理,第二部分就是如何将CKPT转化为pb文件,第三部分就是如何使用pb模型进行预测. 一,模型持久化 为 ...
- SIR模型预测新冠病毒肺炎发病数据
大家还好吗? 背景就不用多说了吧?本来我是初四上班的,现在延长到2月10日了.这是我工作以来时间最长的一个假期了.可惜哪也去不了.待在家里,没啥事,就用python模拟预测一下新冠病毒肺炎的数据吧.要 ...
- kaggle赛题Digit Recognizer:利用TensorFlow搭建神经网络(附上K邻近算法模型预测)
一.前言 kaggle上有传统的手写数字识别mnist的赛题,通过分类算法,将图片数据进行识别.mnist数据集里面,包含了42000张手写数字0到9的图片,每张图片为28*28=784的像素,所以整 ...
随机推荐
- Tomcat--隐藏版本号
为何要隐藏版本号: tomcat默认报错页面信息会暴露出版本号 如果tomcat的版本号暴露出来,会有人利用该版本所存在的漏洞进行攻击,系统存在一定的风险,所以要对tomcat的版本号进行隐藏或者删除 ...
- MMSC 扩充物料库存地点
当涉及到物料的库存地点时,系统通常会做校验,该物料是否扩充了库存地点,没有扩充则报错.为了不使这样的错误干扰到程序逻辑,通常会在涉及时,先查询MARD表,判断是否存在对应的库存地点.如果没有存在,则直 ...
- 微软商店上架Windows&Office破解工具,并获5星好评?
大家好,我是DD! 最近真的除了俄乌冲突之外,其他消息似乎都被淹没了,连狗血的娱乐圈都哑火了. 但昨天在微信群(点击加入)里的这张图引起了我的注意... 据群友称Windows应用商店上架了一个破解W ...
- Codeforces Round #623 (Div. 2) A~D题,D题multiset使用
比赛链接:Here 1315A. Dead Pixel 签到题, 比较四个值 max(max(x, a - 1 - x) * b, a * max(y, b - 1 - y)) 1315B. Home ...
- 即学即会 Serverless | 如何解决 Serverless 应用开发部署的难题?
本文节选自<Serverless 开发速查手册>,关注Serverless 公众回复 手册 即可获得下载链接 作者 | 江昱(阿里云 Serverless 产品经理) 破局:工具链体系匮乏 ...
- vue监听滚动到底部加载更多
https://blog.csdn.net/qq_39762109/article/details/89354305 此方法有个bug
- C# 排序算法5:归并排序
归并排序,是将两个(或两个以上)有序表合并成一个新的有序表,即把待排序序列分为若干个有序的子序列,再把有序的子序列合并为整体有序序列.该算法是采用分治法. 原理: 1.申请空间,使其大小为两个已经排序 ...
- PMP2023
敏捷迭代周期过程中的会议 https://blog.csdn.net/xudahai513/article/details/125216704 https://img-blog.csdnimg.cn/ ...
- spring boot 整合kafka
本文为博主原创,未经允许不得转载: 1. 引入spring boot kafka依赖 <dependency> <groupId>org.springframework.kaf ...
- 基于java+springboot的图书借阅网站-在线图书借阅管理系统
该系统是基于java+springboot开发的图书借阅管理系统.是给师弟开发的课程作业.大家学习过程中,遇到问题可以github咨询作者. 系统演示地址 前台 http://book.gitapp. ...