【LeetCode哈希表#4】梦开始的地方:两数之和(map),以及关于容器map的一些代码技巧
两数之和
给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素不能使用两遍。
示例:
给定 nums = [2, 7, 11, 15], target = 9
因为 nums[0] + nums[1] = 2 + 7 = 9
所以返回 [0, 1]
思路
暴力法
两层for循环,一个一个加起来然后判断呗
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
for(int i = 0; i < nums.size(); i++){
for(int j = i + 1; j < nums.size(); j++){
if(nums[i] + nums[j] == target){
return {i, j};
}
}
}
//不满足条件返回空
return {};
}
};
哈希法
没错,这个题也可以用哈希法去解
只不过这里我们使用的哈希结构有所不同,先分析一下解题思路
题目要求我们找到数组中两个数,这两个数加起来要等于输入的target值
假设,现在遍历到数组的第一个数 A
C = target - A;
那么如果数组中存在 C 的话,我们就找到了两个符合条件的数{A, B},返回两者的下标即可
因此,我们需要有一个数据结构去存放已经遍历过的值和该值在数组中的下标
这是一个key-value的结构,对应到c++中可以通过map容器实现
C++中map,有三种类型:
| 映射 | 底层实现 | 是否有序 | 数值是否可以重复 | 能否更改数值 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|---|
| std::map | 红黑树 | key有序 | key不可重复 | key不可修改 | O(log n) | O(log n) |
| std::multimap | 红黑树 | key有序 | key可重复 | key不可修改 | O(log n) | O(log n) |
| std::unordered_map | 哈希表 | key无序 | key不可重复 | key不可修改 | O(1) | O(1) |
std::unordered_map 底层实现为哈希表,std::map 和std::multimap 的底层实现是红黑树。
因为本题并不需要key有序,所以使用unordered_map效率更高
那么key对应什么?value又对应什么呢?
我们想知道的是,某个值(当前遍历值与target作差之后的差值)是否被遍历过,即查找的对象是某个值,因此需要将遍历得到的数组元素值作为key,其下标作为value
流程
1、遍历数组,向unordered_map中查询当前遍历值对应的值是否被遍历过
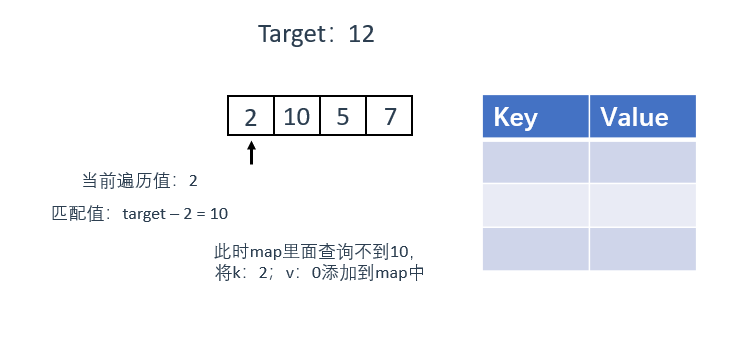
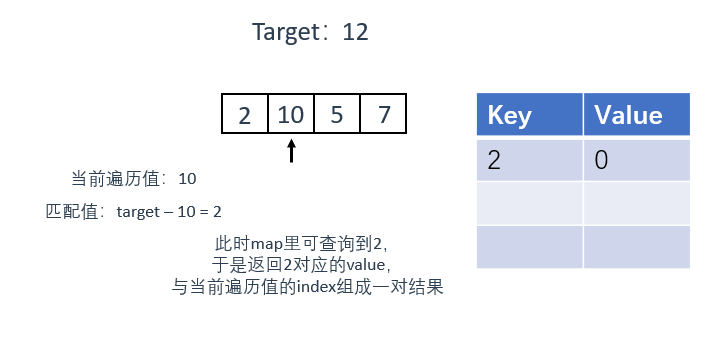
2、如果查询到匹配值,返回该值对应的value,与当前遍历值的index组成一对结果
代码
主要障碍是对c++里面一些容器的操作不熟练(比如这里的map容器),这里直接粘的卡哥的代码
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
//声明一个unordered_map
std::unordered_map <int,int> map;
for(int i = 0; i < nums.size(); i++) {
// 遍历当前元素,并在map中寻找是否有匹配的key
// auto用于自动给迭代对象一个相应的数据类型
auto iter = map.find(target - nums[i]); //这里是定义了一个map的iterator吗?没见过这种写法
//end()指向的最后一个元素的后一个位置
//iter != map.end()是什么意思?其常被用于map容器遍历时的判断条件
//
if(iter != map.end()) { //找到了
/*
(*it).first会得到key,
(*it).second会得到value。
这等同于it->first和it->second
*/
//{匹配值下标, 当前遍历值的下标}
return {iter->second, i};
}
// 如果没找到匹配对,就把访问过的元素和下标加入到map中
map.insert(pair<int, int>(nums[i], i));
}
return {};
}
};
后续需要对c++容器的使用做强化训练(专题:c++刷题常用容器简介,TBD)
关于iter != map.end()
这里需要从它的上一行代码开始说起
摘自《C++ Primer Plus第6版》:
C++11新增了一个工具,让编译器能够根据初始值的类型推断变量的类型。为此,它重新定义了auto的含义。auto是一个C语言关键字,但很少使用,有关其以前的含义,请参阅第9章。在初始化声明中,如果使用关键字auto,而不指定变量的类型,编译器将把变量的类型设置成与初始值相同:
那么auto iter = map.find(target - nums[i]);的含义是:
定义一个 迭代器iter 用于在 map 中寻找 target - nums[i]
如果 map.find(target - nums[i]) 等于 map.end() ,那么键就没有找到。
否则,find会返回一个指向找到的元素的迭代器。
上述题解中的代码可写为:
std::unordered_map <int,int> map;
unordered_map <int,int> ::iterator it = map.find(target - nums[i]);
if (i != m.end()) { /* 找到了, 此时i->first就是匹配值下标(key), i->second是当前遍历值的下标(value) */}
else { /* 没找到f */ }
参考:https://stackoverflow.com/a/1939962/15272780
二刷
简化了之前的代码
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
unordered_map<int, int> hashmap;
for(int i = 0; i < nums.size(); ++i){
if(hashmap.find(target - nums[i]) != hashmap.end()){
return {hashmap[target - nums[i]], i};
}
hashmap.insert(pair<int, int>(nums[i], i));
}
return {};
}
};
有一个关键点是:我们是使用遍历值与target作差,差值作为key,下标作为value
所以可以通过差值查询“差值是否在map中”
【LeetCode哈希表#4】梦开始的地方:两数之和(map),以及关于容器map的一些代码技巧的更多相关文章
- LeetCode 170. Two Sum III - Data structure design (两数之和之三 - 数据结构设计)$
Design and implement a TwoSum class. It should support the following operations: add and find. add - ...
- [LeetCode] 653. Two Sum IV - Input is a BST 两数之和之四 - 输入是二叉搜索树
Given a Binary Search Tree and a target number, return true if there exist two elements in the BST s ...
- leetcode 刷题(数组篇)1题 两数之和(哈希表)
题目描述 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 的那 两个 整数,并返回它们的数组下标. 你可以假设每种输入只会对应一个答案.但是,数组中同一个元 ...
- 【leetcode】170. Two Sum III - Data structure design 两数之和之三 - 数据结构设计
Design and implement a TwoSum class. It should support the following operations: add and find. add ...
- [LeetCode] 167. Two Sum II - Input array is sorted 两数和 II - 输入是有序的数组
Given an array of integers that is already sorted in ascending order, find two numbers such that the ...
- [LeetCode] 170. Two Sum III - Data structure design 两数之和之三 - 数据结构设计
Design and implement a TwoSum class. It should support the following operations:add and find. add - ...
- C++ undered_map哈希表用法——leetcode两数之和
undered_map 头文件:#include<undered_map> 创建表undered_map<key,value> Map_name; 插入元素 a[key]=va ...
- 【数据结构】Hash表简介及leetcode两数之和python实现
文章目录 Hash表简介 基本思想 建立步骤 问题 Hash表实现 Hash函数构造 冲突处理方法 leetcode两数之和python实现 题目描述 基于Hash思想的实现 Hash表简介 基本思想 ...
- LeetCode:乘法表中的第K小的数【668】
LeetCode:乘法表中的第K小的数[668] 题目描述 几乎每一个人都用 乘法表.但是你能在乘法表中快速找到第k小的数字吗? 给定高度m .宽度n 的一张 m * n的乘法表,以及正整数k,你需要 ...
- 167. 两数之和 II - 输入有序数组 + 哈希表 + 双指针
167. 两数之和 II - 输入有序数组 LeetCode_167 题目描述 方法一:暴力法(使用哈希表) class Solution { public int[] twoSum(int[] nu ...
随机推荐
- [转帖]台积电3nm成功量产,稳了吗?
https://docs.pingcode.com/info/13836.html?p=13836 2023-01-19 资讯 21 原标题:台积电3纳米成功量产:未来与三星仍将决战鳍式场效晶体管(F ...
- SPECJVM2008 再学习
SPECJVM2008 再学习 摘要 昨天的太水了 感觉今天有必要再水一点.. 存在的问题 默认进行启动 sunflow 必定过不去. 一般的解决办法要求进行重新编译 但是我不知道怎么下载源码... ...
- Oracle表数量对数据泵备份恢复速度的影响情况
Oracle表数量对数据泵备份恢复速度的影响情况 背景 随着公司产品交付后的时间越来越久. 数据库的备份恢复速度会越来越慢. 最开始一直认为是因为数据量导致的. 但是最近发现, 如果只是将数据库表的量 ...
- redis 6源码解析之 object
redis对象作为redis存储的基本单元,对应redisDb->dict 中的dictEntry->key和dictEntry->val. 更全面的图谱 源码解析参见:object ...
- vite多入口
创建多页面入口 1.在根目录下创建 demo1.htm1,demo2.htm1这两个文件 2.在vite.config.js文件中配置入口 3.在src下创建文件夹和文件,src/demo1/app. ...
- 在K8S中,静态、动态、自主式Pod有何区别?
在Kubernetes(简称K8s)中,静态Pod.自主式Pod和动态Pod是不同管理方式下的Pod类型,它们的区别主要体现在创建和管理方式上: 静态Pod: 静态Pod是由kubelet直接管理的, ...
- C#使用Elasticsearch入门
一.Elasticsearch 简介 Elasticsearch 是一个分布式.RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例.作为 Elastic Stack 的核心,它集中 ...
- 从零开始配置 vim(10)——快捷键配置
之前我们对neovim 进行了基础的配置,这篇主要介绍我比较常用的快捷键配置.到这篇开始我们的配置已经可以为两个大的模块--基础配置和快捷键配置.我们的目录也应该按照模块来进行组织.在正式配置之前让我 ...
- 强烈推荐:数据标注平台doccano----简介、安装、使用、踩坑记录
1.doccano的安装与初始配置 1.1 doccano的用途 document classification 文本分类 sequence labeling 序列标注,用于命名实体识别 sequen ...
- RSAToken 的签名算法 SHA256withRSA、数字签名
数字签名的意义,看下百科:数字签名sign可不是对数据的加密和解密,而是生成签名和验证签名. https://baike.baidu.com/item/%E6%95%B0%E5%AD%97%E7%AD ...