cmu15545笔记-Join算法(Join Algorithms)
Overview
输出形式:早物化与晚物化(OLAP一般都是晚物化)
代价分析:一般用IO次数计算(最终结果可能落盘,也可能不落盘,所以我们只计算输出结果之前的IO次数)。
Join左边称为外表(Outer Table),右边称为内表(Inner Join),外表一般是小表。

Nested Loop Join
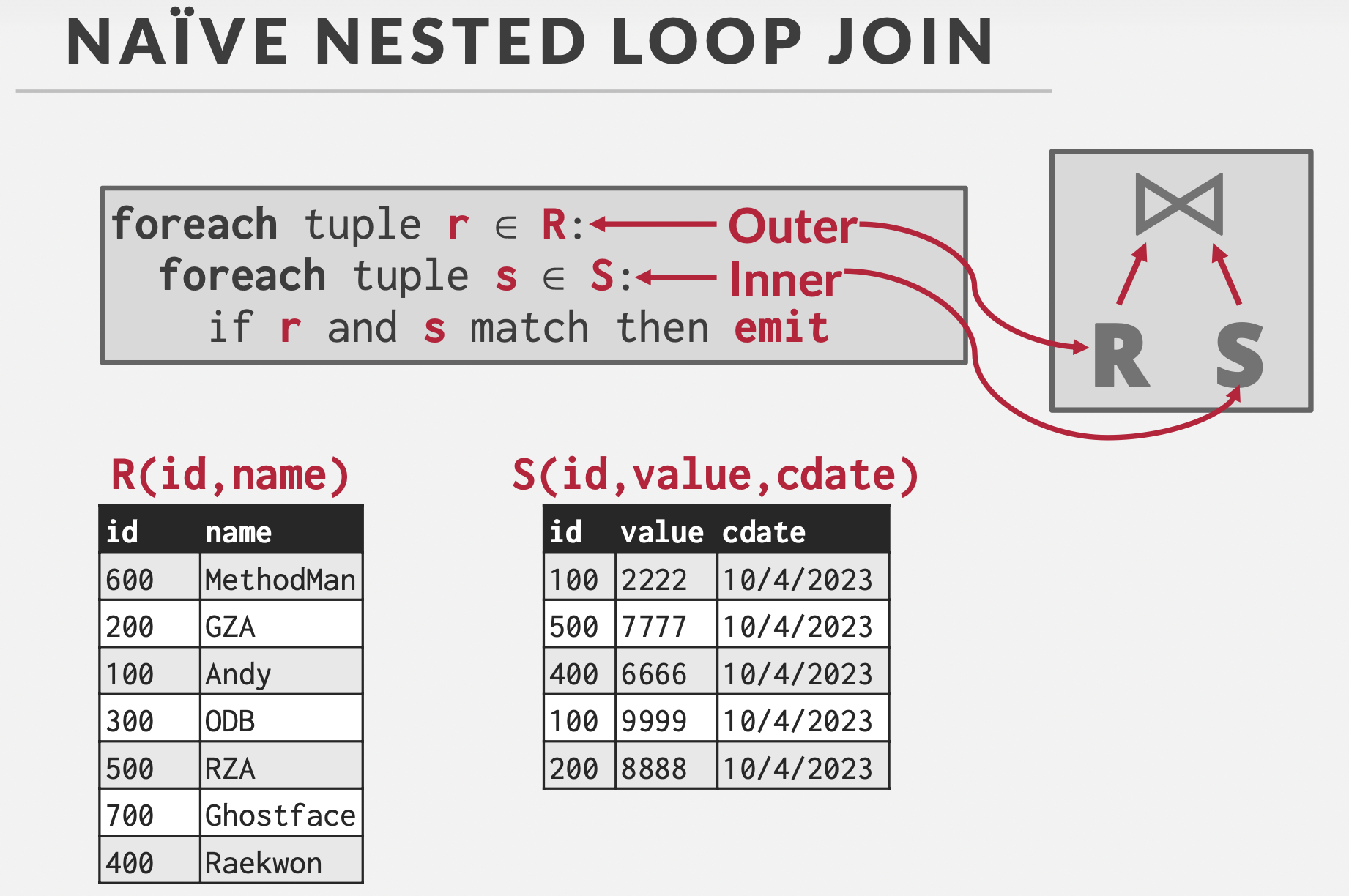
Naïve
前提:缓冲区大小为3,一个外表输入,一个内表输入,一个输出。
基本思想:双重循环,对每一个元组(Tuple)进行配对,读取S表m次。
Cost:\(M+(m*N)\)

Block
前提:缓冲区大小为3,一个外表输入,一个内表输入,一个输出。
基本思想:双重循环,对每一个块(Block,同页Page)内进行配对,所以读取S表M次。
Cost:\(M+(M*N)\)
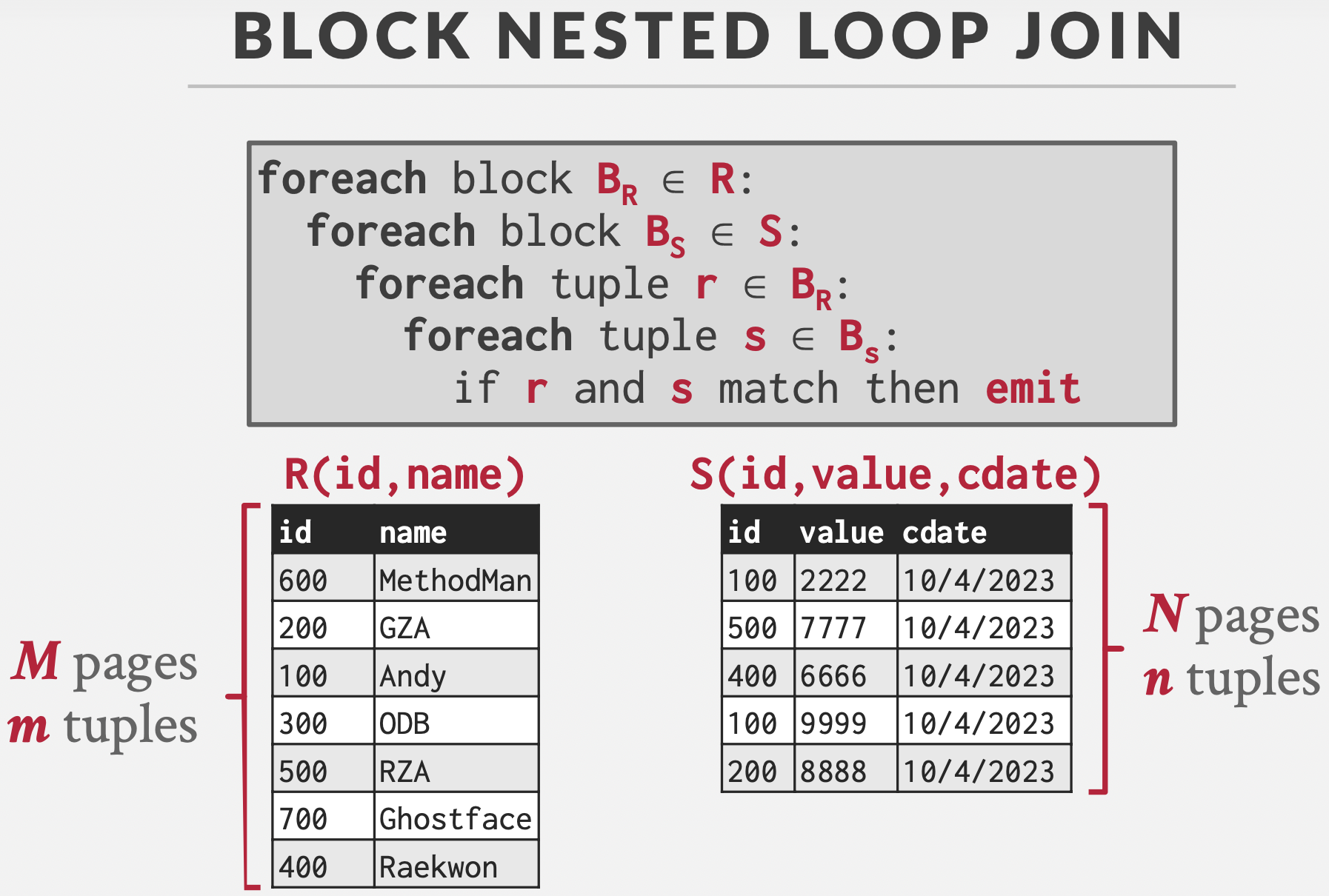
如果缓冲区容量为B,即可以容纳B个块(页),B-2个块用于外表输入,一个块用于内表输入,一个块用于输出。
Cost:\(M+(⌈M/(B-2)⌉*N)\)
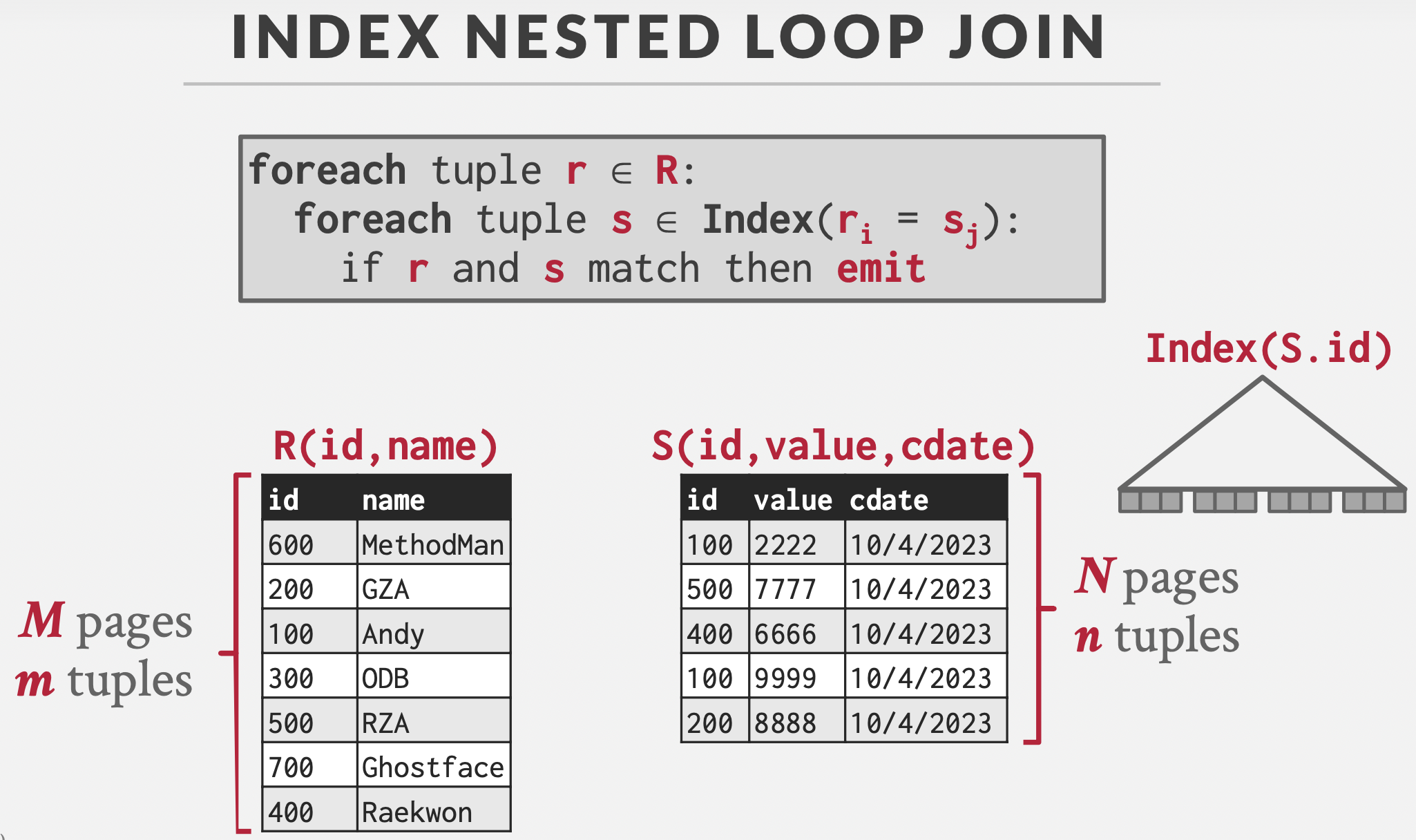
Index
前提:缓冲区大小为3,一个外表输入,一个内表输入,一个输出。
基本思想:如果外部表有索引,那么内层循环无需遍历,查询索引即可。
Cost:\(M+(m*C)\)
Sort-Merge Join
基本思想:排序后的序列更容易找到匹配项。
分为两个步骤:
- 排序:用任意排序方式,将R和S排序。
- 合并:移动两个指针寻找匹配项,过程中可能需要回退指针。
这两个步骤和上一节提到的外部归并排序思想相同,但不是同一个东西。
SortCost(R):\(2M*(1 + ⌈ log_{B-1} ⌈M / B⌉ ⌉)\)
SortCost(S):\(2N*(1 + ⌈ log_{B-1} ⌈N / B⌉ ⌉)\)
MergeCost:\(M+N\)
Total Cost:Sort + Merge
当R中存的是相同元素,且S中也是时,指针需要一直回退,Sort-Merge Join退化为Nest Loop Join。


Hash Join
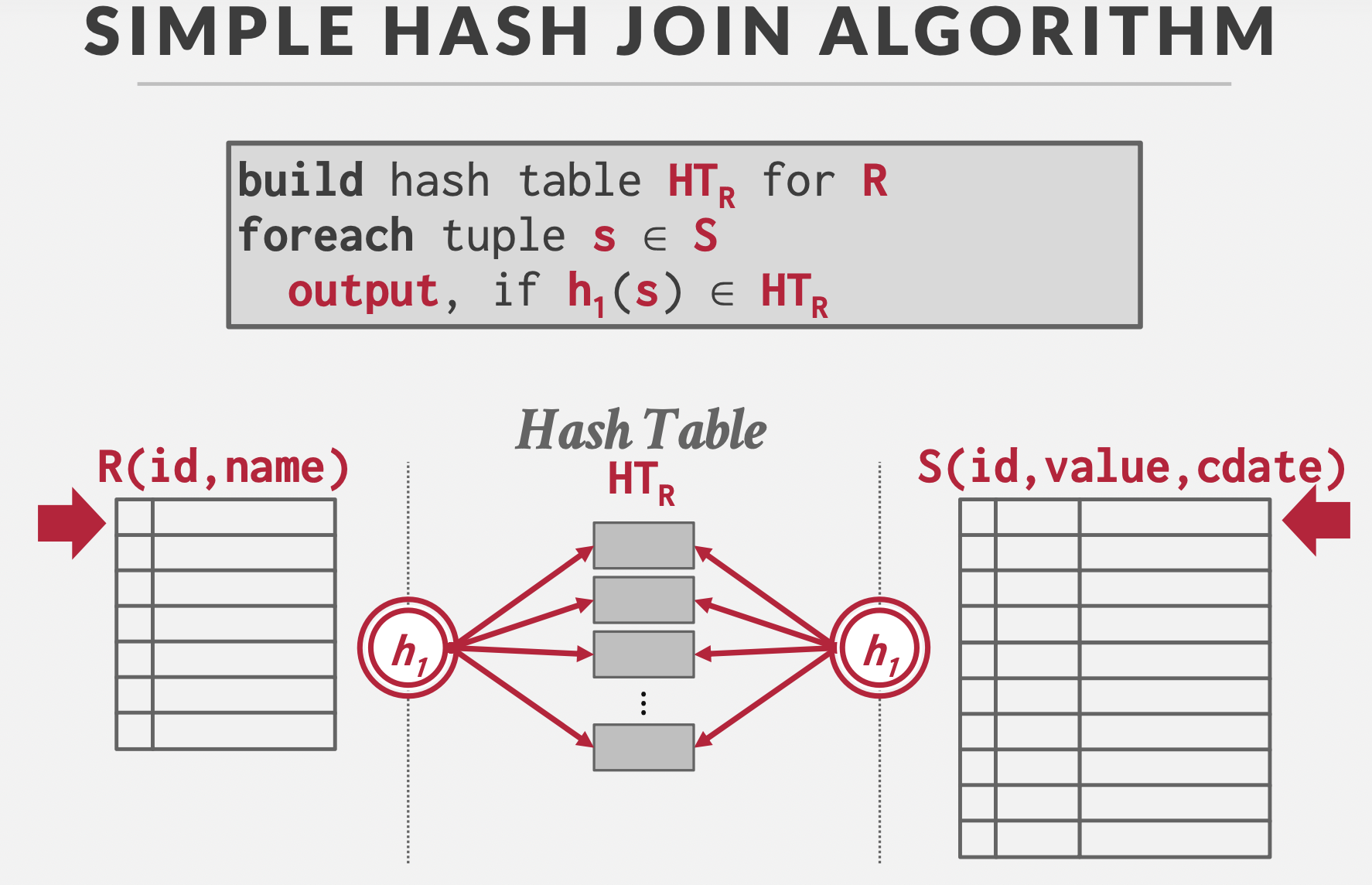
Simple Hash Join
基本思想:匹配项会被映射到同一个哈希桶。
分为两步骤:
- 构建哈希表:对R表采用哈希函数\(h_1\)进行哈希,得到哈希表,包含不同的哈希桶(可以采用不同的哈希表,但是链式哈希最符合需求)。
- 探测:把S表元组用哈希函数\(h_1\)进行哈希,得到对应的哈希桶位置,然后在哈希桶中寻找匹配项。
优化措施:布隆过滤器。
创建哈希表时顺带构建布隆过滤器,探测阶段先走布隆过滤器再走哈希桶。
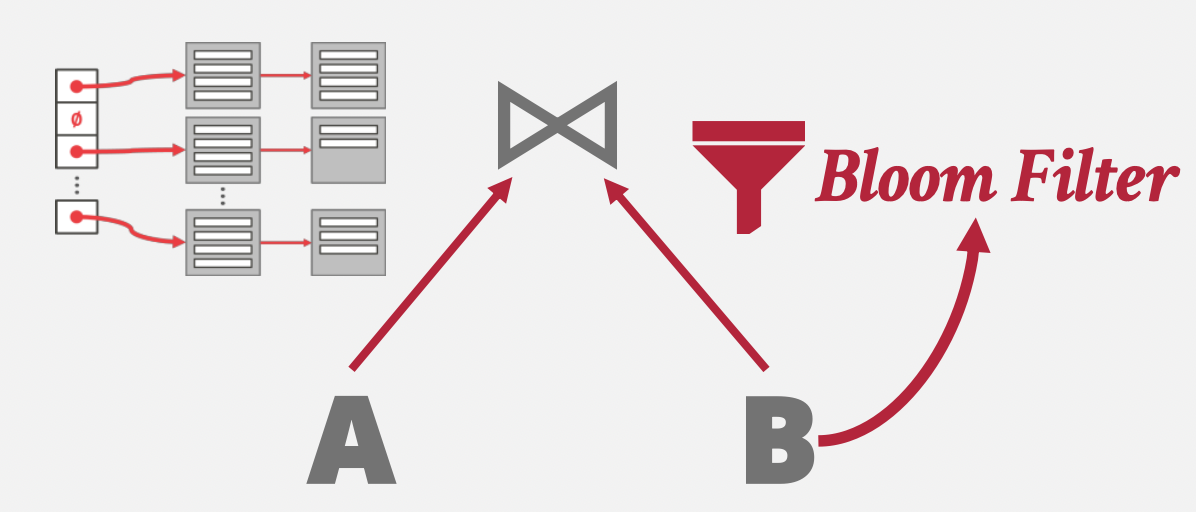
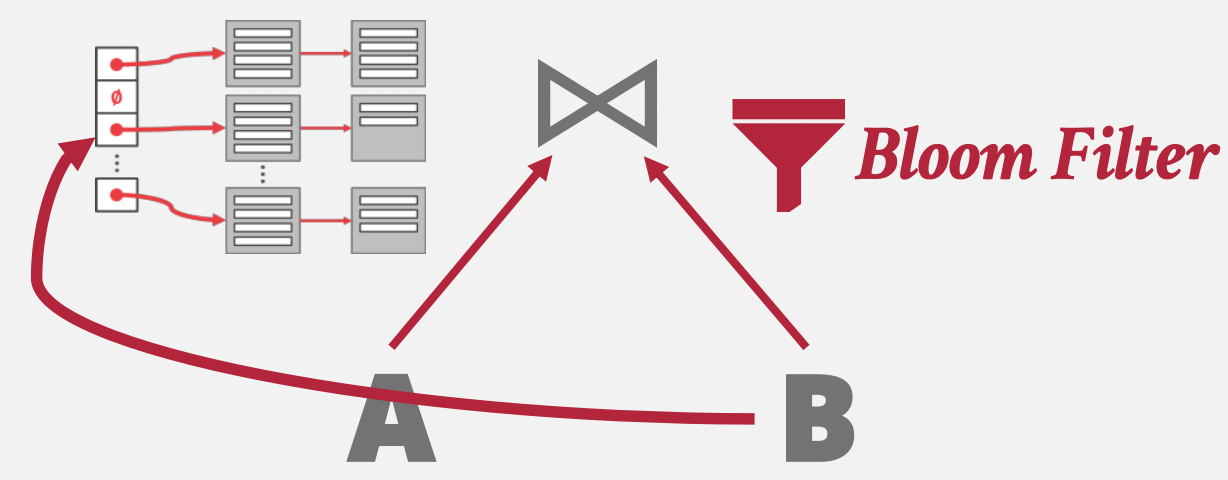
存在的问题i:该算法需要保证哈希表能存在内存中,如果哈希表太大导致无法存到内存中,需要不断地换入换出,影响效率。但不幸的是,大部分情况下,我们都不能保证内存能完全存下哈希表。
Partition Hash Join
基本思想:把两个表分别用同一个哈希函数哈希,相同哈希桶之间进行配对,如果哈希桶都存不下,就再哈希一次,直到能存下为止。
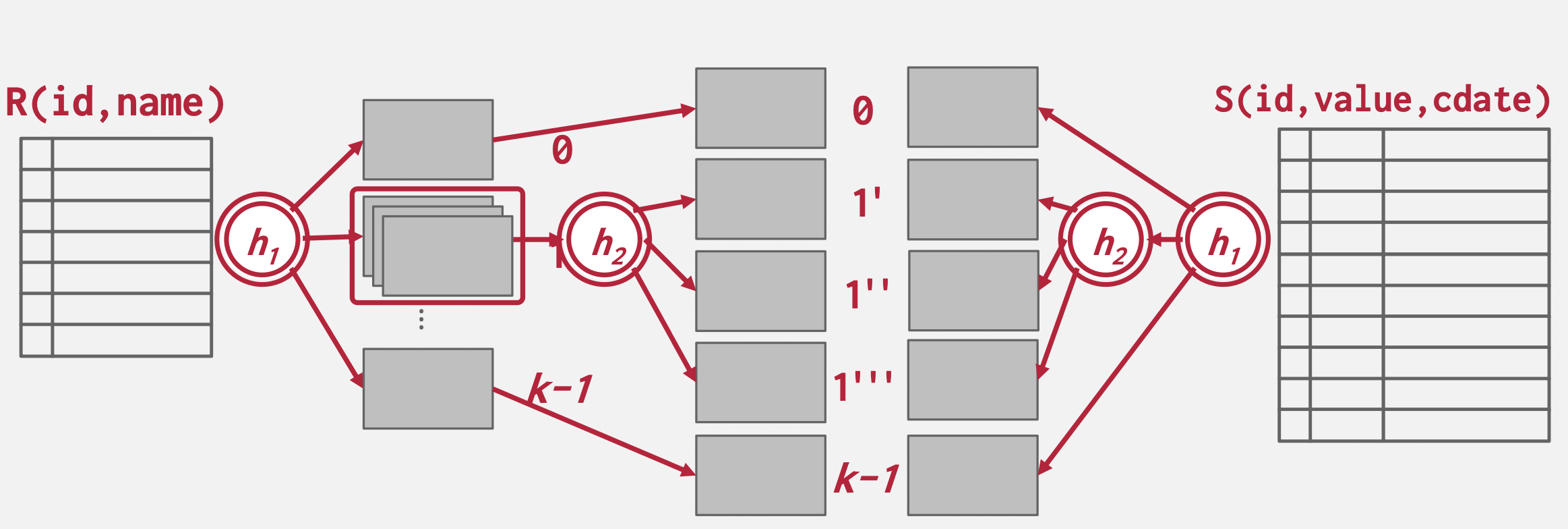
读取对应的哈希桶到内存中配对即可。
Partition Cost:\(2(M+N)\) 【读取数据+哈希桶落盘(哈希空间复杂度为\(O(n)\))】
Probe Cost:\(M+N\)
Total Cost:\(3(M+N)\)
总结
| Algorithm | IO Cost | Example |
|---|---|---|
| Naïve Nested Loop Join | \(M + (m \cdot N)\) | 1.3 hours |
| Block Nested Loop Join | $ M + (\lceil \frac{M}{B-2} \rceil \cdot N)$ | 0.55 seconds |
| Index Nested Loop Join | \(M + (m \cdot C)\) | Variable |
| Sort-Merge Join | $ M + N + (\text{sort cost})$ | 0.75 seconds |
| Hash Join | \(3 \cdot (M + N)\) | 0.45 seconds |
选择Partition Hash Join,出现下述情况时使用Sort-Merge Join:
数据偏斜严重:Hash Join退化为Sort-Merge Join
数据本身需要被排序:此时Sort-Merge Join只需要额外付出 \(M+N\) 即可实现Join
一般数据库中,Hash Join和Sort-Merge Join都会实现。
cmu15545笔记-Join算法(Join Algorithms)的更多相关文章
- MySQL Nested-Loop Join算法学习
不知不觉的玩了两年多的MySQL,发现很多人都说MySQL对比Oracle来说,优化器做的比较差,其实某种程度上来说确实是这样,但是毕竟MySQL才到5.7版本,Oracle都已经发展到12c了,今天 ...
- 1110Nested Loop Join算法
转自 http://blog.csdn.net/tonyxf121/article/details/7796657 join的实现原理 join的实现是采用Nested Loop Join算法,就是通 ...
- 关于join算法的四篇文章
MySQL Join算法与调优白皮书(一) MySQL Join算法与调优白皮书(二) MySQL Join算法与调优白皮书(三) MySQL Join算法与调优白皮书(四) MariaDB Join ...
- 使用map端连接结合分布式缓存机制实现Join算法
前面我们介绍了MapReduce中的Join算法,我们提到了可以通过map端连接或reduce端连接实现join算法,在文章中,我们只给出了reduce端连接的例子,下面我们说说使用map端连接结合分 ...
- HASH JOIN算法
哈希连接(HASH JOIN) 前文提到,嵌套循环只适合输出少量结果集.如果要返回大量结果集(比如返回100W数据),根据嵌套循环算法,被驱动表会扫描100W次,显然这是不对的.看到这里你应该明白为 ...
- 24.join算法/锁_1
一. JOIN算法1.1. JOIN 语法 mysql> select * from t4; +---+------+ | a | b | +---+------+ | | 11 | | | 5 ...
- MySQL Join算法与调优白皮书(一)
正文 Inside君发现很少有人能够完成讲明白MySQL的Join类型与算法,网上流传着的要提升Join性能,加大变量join_buffer_size的谬论更是随处可见.当然,也有一些无知的PGer攻 ...
- MySQL Join算法与调优白皮书(二)
Index Nested-Loop Join (接上篇)由于访问的是辅助索引,如果查询需要访问聚集索引上的列,那么必要需要进行回表取数据,看似每条记录只是多了一次回表操作,但这才是INLJ算法最大 ...
- 022:SQL优化--JOIN算法
目录 一. SQL优化--JOIN算法 1.1. JOIN 写法对比 2. JOIN的成本 3. JOIN算法 3.1. simple nested loop join 3.2. index nest ...
- 并发编程学习笔记(12)----Fork/Join框架
1. Fork/Join 的概念 Fork指的是将系统进程分成多个执行分支(线程),Join即是等待,当fork()方法创建了多个线程之后,需要等待这些分支执行完毕之后,才能得到最终的结果,因此joi ...
随机推荐
- P10884 [COCI 2017-2018#2] San
题目传送门:P10884 [COCI 2017-2018#2] San 看下标签 COCI(克罗地亚) 2017 啊 比我小4年的题 --------------------------------- ...
- draw.io 输入数学公式
首先我们要把数学排版功能打开: 然后输入数学公式: AsciiMath 公式由 ` 包裹,如:`a2+b2 = c^2` LaTeX 公式由 $$ 包裹,如:$$\sqrt{3×-1}+(1+x)^2 ...
- 【Mac + Python + Selenium】之获取验证码图片code并进行登录
自己新总结了一篇文章,对代码进行了优化,另外附加了静态图片提取文字方法,两篇文章可以结合着看:<[Python]Selenium自动化测试之动态识别验证码图片方法(附静态图片文字获取)> ...
- ERROR: Could not determine java version from 'JavaVersion.VERSION_1_8'.
写法原为: compileOptions { sourceCompatibility 'JavaVersion.VERSION_1_8' targetCompatibility 'JavaVersio ...
- nftables
RHEL 8 用 ntftable 替换 iptables, 新安装的 CentOS 8.3 是这样的: [root@net182-host113 ~]# nft list tablestable i ...
- 8.4linux定时任务-环境变量-数据库
配合SUID本地环境变量提权 思路原理:利用sh环境变量替换,使得/tmp/ps得到root权限:ps=sh 过程:手写调用文件-编译-复制文件-增加环境变量-执行 gcc demon1.c -o s ...
- OCR技术的昨天今天和明天!2023年最全OCR技术指南!
OCR是一项科技革新,通过自动化大幅减少人工录入的过程,帮助用户从图像或扫描文档中提取文字,并将这些文字转换为计算机可读格式.这一功能在许多需要进一步处理数据的场景中,如身份验证.费用管理.自动报销. ...
- 第5天:基础入门-反弹SHELL&不回显带外&正反向连接&防火墙出入站&文件下载
文件上传下载-解决无图形化&解决数据传输 命令生成:https://forum.ywhack.com/bountytips.php?download 反弹shell 以参照物为准,以Linux ...
- Hive----基本概念
Hive 基本概念 1. Hive:由 Facebook 开源用于解决海量结构化日志的数据统计. 2. Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类 ...
- 国产OS 中标麒麟下 C# 桌面应用开发环境搭建笔记
1.中标麒麟 7.0 x86 桌面版 默认安装创建用户时,如果没勾选 root 用户使用相同的口令,那么安装完成以后,root 是没有设置口令的,通过 sudo passwd root 输入当前普通用 ...