快速定位MySQL 8.0中的慢查询语句详细步骤
步骤一、启用慢查询日志
慢查询日志是MySQL记录执行时间超过指定阈值的SQL语句
配置慢查询日志
在MySQL配置文件(如my.cnf或my.ini)中设置以下参数:

slow_query_log:是否启用慢查询日志
slow_query_log_file:指定慢查询日志文件的保存位置
long_query_time:设置慢查询阈值(单位:秒),如1秒
修改后重启MySQL服务 或 执行以下命令生效:

步骤二、通过工具分析慢查询日志
慢查询日志会记录执行时间超过阈值的SQL语句,可以通过工具或手动分析日志
三、使用mysqldumpslow工具分析慢查询日志
1、使用mysqldumpslow工具
mysqldumpslow 的主要功能是:
解析慢查询日志文件
将相似的查询归类(通过去除具体参数,提取 SQL 模板)
汇总查询的执行次数、总时间、平均时间、最大时间等信息
生成一个简洁的报告,便于分析慢查询
2、mysqldumpslow 是 MySQL 自带的工具,通常位于 MySQL 的安装目录中。如果已经安装了 MySQL,可以直接使用
检查工具是否存在:
which mysqldumpslow
如果返回路径(如 /usr/bin/mysqldumpslow),说明工具已安装
3、基本用法
语法:
mysqldumpslow [选项] [慢查询日志文件]
示例:
mysqldumpslow /var/log/mysql/slow.log
该命令会解析慢查询日志文件,并输出一个汇总报告
4、常用选项
mysqldumpslow 提供了多种选项,用于控制输出的内容和格式。以下是一些常用选项:

5、使用示例
示例 1:按总执行时间排序,输出最慢的 10 条查询
mysqldumpslow -s t -t 10 /var/log/mysql/slow.log
示例 2:按执行次数排序,输出执行次数最多的 5 条查询
mysqldumpslow -s c -t 5 /var/log/mysql/slow.log
示例 3:按平均锁定时间排序,输出平均锁定时间最长的查询
mysqldumpslow -s al /var/log/mysql/slow.log
示例 4:过滤包含 SELECT 的查询
mysqldumpslow -g "SELECT" /var/log/mysql/slow.log
示例 5:显示完整的 SQL 语句
mysqldumpslow -a /var/log/mysql/slow.log
6、输出内容解读
mysqldumpslow 的输出通常包括以下信息:
Count:该查询的执行次数
Time:该查询的总执行时间
Lock:该查询的总锁定时间
Rows:该查询的总返回行数
SQL 模板:抽象化后的 SQL 语句(去除具体参数)
示例输出:
Count: 5 Time=10.12s (50s) Lock=0.00s (0s) Rows=100.0 (500), user1[user1]@localhost SELECT * FROM users WHERE id = N
该查询执行了 5 次
总执行时间为 50 秒(平均每次 10.12 秒)
总锁定时间为 0 秒
总返回行数为 500 行(平均每次 100 行)
查询模板为 SELECT * FROM users WHERE id = N
7、注意事项
a、慢查询日志格式:
确保慢查询日志的格式是标准的 MySQL 慢查询日志格式
如果日志格式不匹配,mysqldumpslow 可能无法正确解析
b、日志文件权限:
- 确保运行 mysqldumpslow 的用户有权限读取慢查询日志文件
c、日志文件大小:
- 如果慢查询日志文件非常大,解析可能会消耗较多时间和资源
d、抽象化问题:
- mysqldumpslow 默认会抽象化 SQL 语句中的参数(如数字和字符串),这可能导致某些查询被错误地归类
四、pt-query-digest工具分析慢查询日志
1、工具的作用
pt-query-digest 的主要功能包括:
解析 MySQL 慢查询日志、general log 或 binary log
将相似的查询归类(通过 SQL 指纹技术)
生成详细的性能分析报告,包括执行时间、锁定时间、返回行数等
支持多种输出格式(如报告、JSON、表格等)
支持将分析结果存储到数据库中,便于进一步分析
2、安装
pt-query-digest 是 Percona Toolkit 的一部分,需要单独安装
在 Debian/Ubuntu 上安装:
sudo apt-get install percona-toolkit
在 CentOS/RHEL 上安装:
sudo yum install percona-toolkit
验证安装:
pt-query-digest --version
3、基本用法
语法:
pt-query-digest [选项] [日志文件]
示例:
pt-query-digest /var/log/mysql/slow.log
该命令会解析慢查询日志文件,并生成一个详细的性能分析报告
4、常用选项
pt-query-digest 提供了丰富的选项,用于控制输出的内容和格式。以下是一些常用选项:

5、使用示例
示例 1:分析慢查询日志并生成报告
pt-query-digest /var/log/mysql/slow.log
示例 2:按总执行时间排序,输出最慢的 10 条查询
pt-query-digest --limit=10 --order-by=Query_time:sum /var/log/mysql/slow.log
示例 3:将分析结果存储到数据库中
pt-query-digest --review h=localhost,D=slow_query_log,t=query_review /var/log/mysql/slow.log
该命令会将分析结果插入到 slow_query_log.query_review 表中
示例 4:分析 general log
pt-query-digest --type genlog /var/log/mysql/general.log
示例 5:分析 binary log
pt-query-digest --type binlog /var/log/mysql/mysql-bin.000001
示例 6:输出 JSON 格式的报告
pt-query-digest --output=json /var/log/mysql/slow.log
6、输出内容解读
pt-query-digest 的输出通常包括以下部分:
a、总体统计信息
日志文件的总大小
解析的查询总数
唯一查询的数量
总执行时间、锁定时间、返回行数等
b、查询摘要
每个查询的指纹(抽象化后的 SQL 模板)
执行次数、总时间、平均时间、最大时间等
查询的分布情况(如 95% 的查询执行时间)
c、详细查询信息
每个查询的详细执行情况
查询的示例(具体的 SQL 语句)
查询的执行计划(如果启用了 EXPLAIN)
7、示例
执行工具pt-query-digest
./pt-query-digest /usr/local/src/slowsqlExample/slow0312.log
结果分析
[root@iZ2zebthf35ejlps5v87ksZ bin]# ./pt-query-digest /usr/local/src/slowsqlExample/slow0312.log
第一部分
该工具执行日志分析的用户时间,系统时间,物理内存占用大小,虚拟内存占用大小
# 360ms user time, 10ms system time, 22.56M rss, 187.09M vsz
工具执行时间
# Current date: Fri Mar 20 22:54:14 2020
运行分析工具的主机名
# Hostname: iZ2zebthf35ejlps5v87ksZ
被分析的文件名
# Files: /usr/local/src/slowsqlExample/slow0312.log
语句总数量,唯一的语句数量,QPS,并发数
# Overall: 906 total, 21 unique, 0.02 QPS, 0.07x concurrency _____________
日志记录的时间范围
# Time range: 2020-03-11 12:22:13 to 2020-03-12 00:16:57
# Attribute total min max avg 95% stddev median
# ============ ======= ======= ======= ======= ======= ======= =======
语句执行时间
# Exec time 2991s 2s 10s 3s 5s 1s 3s
锁占用时间
# Lock time 552ms 24us 371ms 609us 103us 12ms 57us
发送到客户端的行数
# Rows sent 167.53k 0 17.99k 189.35 487.09 1.22k 0
select语句扫描行数
# Rows examine 980.73M 238 1.96M 1.08M 1.95M 757.80k 753.18k
查询的字符数
# Query size 258.71k 17 1.77k 292.41 463.90 202.02 329.68
第二部分
# Profile
Rank:所有语句的排名,默认按查询时间降序排列,通过--order-by指定
Query ID:语句的ID,(去掉多余空格和文本字符,计算hash值)
Response:总的响应时间
time:该查询在本次分析中总的时间占比
calls:执行次数,即本次分析总共有多少条这种类型的查询语句
R/Call:平均每次执行的响应时间
V/M:响应时间Variance-to-mean的比率
Item:查询对象
# Rank Query ID Response time Calls R/Call V/M
# ==== =============================== =============== ===== ====== =====
# 1 0xABD1DCCCCD5AA5128E10C27B34... 1246.6948 41.7% 283 4.4053 0.04 UPDATE ziweidashi_deviceinfo
# 2 0x6914B81AAD1785E50708ABD113... 877.6900 29.3% 339 2.5891 0.09 SELECT birthDay_notify
# 3 0x44D9474C6D5C58DD07B5FEEA0D... 299.4193 10.0% 71 4.2172 0.05 SELECT tmall_product_orders
# 4 0xA9BE84CBE3DAA9B1CDD9B5A9EC... 127.0137 4.2% 46 2.7612 0.04 SELECT daily_user_action_log
# 5 0xCF0E12117C971C3013142E3717... 118.3138 4.0% 49 2.4146 0.05 SELECT tmall_user_take_coupon_record
# 6 0x94263184D24186330B13193534... 97.0805 3.2% 35 2.7737 0.56 SELECT tgg_users
# 7 0xC51165F1287A2ECDA221AC1F54... 52.5870 1.8% 22 2.3903 0.04 SELECT util_user_task_log
# 8 0xB8004D6D8A7A7967E04CD81E26... 43.7895 1.5% 16 2.7368 0.08 SELECT daily_user_action_log
# 9 0x910E19224F33DAA6391927B8E8... 41.3720 1.4% 15 2.7581 1.17 SELECT qifugong_tianbi_record
# MISC 0xMISC 86.7871 2.9% 30 2.8929 0.0 <12 ITEMS>
第三及后续部分,第一条查询语句 query id:0xABD1DCCCCD5AA5128E10C27B34BC04E7
# Query 1: 0.01 QPS, 0.03x concurrency, ID 0xABD1DCCCCD5AA5128E10C27B34BC04E7 at byte 355748
# Scores: V/M = 0.04
# Time range: 2020-03-11 12:24:03 to 2020-03-12 00:16:13
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
# Count 31 283
# Exec time 41 1247s 4s 8s 4s 5s 437ms 4s
# Lock time 69 386ms 24us 371ms 1ms 93us 21ms 44us
# Rows sent 0 0 0 0 0 0 0 0
# Rows examine 18 180.00M 651.14k 651.45k 651.29k 650.62k 0 650.62k
# Query size 10 27.64k 100 100 100 100 0 100
# String:
数据库名
# Databases taxen_ziweidashi
执行主机
# Hosts 118.190.93.166
执行用户
# Users devAccount
查询时间占比
# Query_time distribution
# 1us
# 10us
# 100us
# 1ms
# 10ms
# 100ms
# 1s ################################################################
# 10s+
# Tables
# SHOW TABLE STATUS FROM `taxen_ziweidashi` LIKE 'ziweidashi_deviceinfo'\G
# SHOW CREATE TABLE `taxen_ziweidashi`.`ziweidashi_deviceinfo`\G
UPDATE ziweidashi_deviceinfo
SET expired = 1
WHERE createTime <= 1583942580685\G
# Converted for EXPLAIN
# EXPLAIN /*!50100 PARTITIONS*/
select expired = 1 from ziweidashi_deviceinfo where createTime <= 1583942580685\G
# Query 2: 0.03 QPS, 0.07x concurrency, ID 0x6914B81AAD1785E50708ABD11319E02E at byte 13829
# Scores: V/M = 0.09
# Time range: 2020-03-11 12:22:13 to 16:05:47
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
# Count 37 339
# Exec time 29 878s 2s 4s 3s 4s 472ms 2s
# Lock time 5 29ms 31us 4ms 86us 98us 229us 66us
# Rows sent 0 24 0 2 0.07 0 0.32 0
# Rows examine 67 665.20M 1.96M 1.96M 1.96M 1.96M 0 1.96M
# Query size 59 154.47k 462 467 466.60 463.90 2.07 463.90
# String:
# Hosts 10.66.186.115
# Users root
# Query_time distribution
# 1us
# 10us
# 100us
# 1ms
# 10ms
# 100ms
# 1s ################################################################
# 10s+
# Tables
# SHOW TABLE STATUS LIKE 'birthDay_notify'\G
# SHOW CREATE TABLE `birthDay_notify`\G
# EXPLAIN /*!50100 PARTITIONS*/
select birthdayno0_.id as id1_1_, birthdayno0_.index_card_show_date as index_ca2_1_, birthdayno0_.userId as userId3_1_, birthdayno0_.push_content as push_con4_1_, birthdayno0_.card_content as card_con5_1_, birthdayno0_.birthday_userId as birthday6_1_, birthdayno0_.birthday_contactId as birthday7_1_, birthdayno0_.need_push as need_pus8_1_ from birthDay_notify birthdayno0_ where birthdayno0_.userId=1304747 and birthdayno0_.index_card_show_date='2020-03-11 00:00:00'\G
8、注意事项
a、日志文件格式:
确保日志文件的格式是标准的 MySQL 日志格式
如果日志格式不匹配,pt-query-digest 可能无法正确解析
b、日志文件大小:
- 如果日志文件非常大,解析可能会消耗较多时间和资源
c、权限问题:
- 确保运行 pt-query-digest 的用户有权限读取日志文件
d、存储分析结果:
- 如果使用 --review 或 --history 选项,确保目标数据库的表结构正确
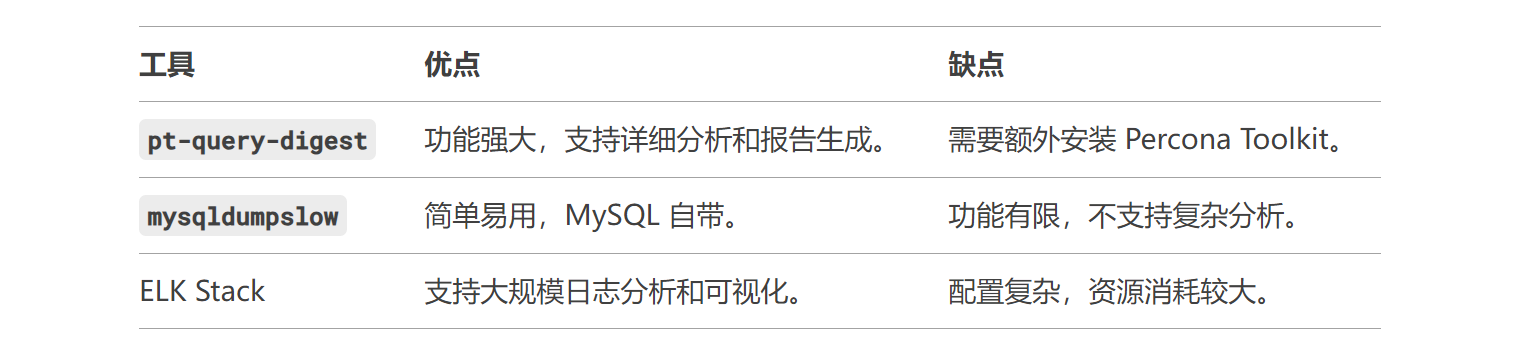
五、与其他工具的比较
快速定位MySQL 8.0中的慢查询语句详细步骤的更多相关文章
- 牛逼!MySQL 8.0 中的索引可以隐藏了…
MySQL 8.0 虽然发布很久了,但可能大家都停留在 5.7.x,甚至更老,其实 MySQL 8.0 新增了许多重磅新特性,比如栈长今天要介绍的 "隐藏索引" 或者 " ...
- MySQL 8.0 中统计信息直方图的尝试
直方图是表上某个字段在按照一定百分比和规律采样后的数据分布的一种描述,最重要的作用之一就是根据查询条件,预估符合条件的数据量,为sql执行计划的生成提供重要的依据在MySQL 8.0之前的版本中,My ...
- MySQL 并行复制演进及 MySQL 8.0 中基于 WriteSet 的优化
MySQL 8.0 可以说是MySQL发展历史上里程碑式的一个版本,包括了多个重大更新,目前 Generally Available 版本已经已经发布,正式版本即将发布,在此将介绍8.0版本中引入的一 ...
- Mysql编辑工具中使用(Navicat查询结果显示行号)
Mysql编辑工具中使用(Navicat查询结果显示行号) as rownum,a.roleId ) t where a.roleId='admin';
- mysql第四篇--SQL逻辑查询语句执行顺序
mysql第四篇--SQL逻辑查询语句执行顺序 一.SQL语句定义顺序 SELECT DISTINCT <select_list> FROM <left_table> < ...
- 对于Oracle中分页排序查询语句执行效率的比较分析
转自:http://bbs.csdn.net/topics/370033478 对于Oracle中分页排序查询语句执行效率的比较分析 作者:lzgame 在工作中我们经常遇到需要在Oracle中进行分 ...
- unity3d开发的android应用中增加AD系统的详细步骤
unity3d开发的android应用中增加AD系统的详细步骤 博客分类: Unity3d unity3d Unity3d已经支持android,怎样在程序里增加admob? 试了一下,确实能够, ...
- Odoo14 ir.rule 中的domain查询语句
# ir.rule 中的domain查询语句 # 当你的字段是many2one.many2many.one2many的时候domain都会强制加上过滤域 # tree显示的时候也会过滤 # m.mod ...
- 关联与下钻:快速定位MySQL性能瓶颈的制胜手段
本文根据DBAplus社群[2018年1月6日北京开源与架构技术沙龙]现场演讲内容整理而成. 讲师介绍 李季鹏 新炬网络数据库专家 专注于MySQL数据库性能管理及相关解决方案,目前主要从事MySQL ...
- 快速了解C# 8.0中“可空引用类型(Nullable reference type)”语言特性
Visual C# 8.0中引入了可空引用类型(Nullable reference type),通过编译器提供的强大功能,帮助开发人员尽可能地规避由空引用带来的代码问题.这里我大致介绍一下可空引用类 ...
随机推荐
- mxGraph绘制机构图
简单介绍一下使用的依赖: JGraphX package JGraphX is a Java Swing diagramming (graph visualisation) library lic ...
- 在阿里云ECS上一键部署DeepSeek-R1
DeepSeek-R1 是一款开源模型,也提供了 API(接口)调用方式.据 DeepSeek介绍,DeepSeek-R1 后训练阶段大规模使用了强化学习技术,在只有极少标注数据的情况下提升了模型推理 ...
- 【ABP】项目示例(1)——项目搭建前置准备
项目介绍 本项目使用.NET8+ABP+MySql搭建,基于DDD的设计思想,创建分层Web应用程序. 相关文档 .NET开发文档 Entity Framework Core开发文档 ABP开发文档 ...
- .NET周刊【2月第2期 2025-02-09】
国内文章 开箱即用的.NET MAUI组件库 V-Control 发布了! https://www.cnblogs.com/jevonsflash/p/18701494 文章介绍了V-Control, ...
- 不到24小时,AOne让全员用上DeepSeek的秘诀是……
DeepSeek引发新一轮AI浪潮,面对企业数字化智能升级与数据安全红线的急迫需求,IT负责人的压力山大!如何在24小时内实现全员AI落地,同时为后续安全部署铺平道路? Step1:一键开启全员智能时 ...
- vue - [04] 配置
关闭ESLint. 001 || ESLint (1)定义 ESLint是一个插件化的JavaScript代码检查工具.在vue项目中,它可以检查.vue文件中的JavaScript代码(包括脚本 ...
- DataX - [02] 安装部署
操作系统:Alibaba Cloud Linux release 3 (Soaring Falcon) Java:1.8.0_372 Python:3.6.8 => 2.7.1 一.安装部署 ( ...
- RedHat8密码复杂度策略配置
1.密码复杂度策略概念 在Linux系统中,确保用户密码的复杂度是提高系统安全性的重要措施之一.通过配置密码策略,可以强制用户使用强密码,从而降低被破解的风险.本文将详细介绍如何在 Linux 系统中 ...
- HTTP协议与RESTful API实战手册(终章):构建企业级API的九大秘籍 🔐
title: HTTP协议与RESTful API实战手册(终章):构建企业级API的九大秘籍 date: 2025/2/28 updated: 2025/2/28 author: cmdragon ...
- python基础-函数(lambda表达式、函数作参数、内置函数、推导式)和pip
函数进阶 今日概要: 函数名就是一个变量(扩展) 匿名函数(lambda表达式) 重点内置函数--python内置函数 推导式(一行代码生成数据) 1. 函数名就是变量 def func(): pas ...