DQN(Deep Reiforcement Learning) 发展历程(三)
不基于模型(Model-free)的预测
- 无法事先了解状态转移的概率矩阵
蒙特卡罗方法
从开始状态开始,到终结状态,找到一条完整的状态序列,以求解每个状态的值。相比于在整个的状态空间搜索,是一种采样的方法。
- 对于某一状态在同一状态序列中重复出现的,有以下两种方法:
- 只选择第一个状态进行求解,忽略之后的所有相同状态
- 考虑所有的状态,求平均值
- 对于求解每个状态的值,使用平均值代表状态值,根据大数定理,状态数足够多的条件下,该平均值等于状态值。平均值求解有两种方法:
- 存储所有状态后求平均:消耗大量存储空间
- 每次迭代状态都更新当前平均值:
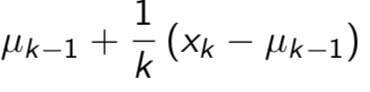
时序差分方法
- 蒙特卡罗方法需要获得从开始到终结的一条完整的状态序列,以求解每个状态的值,时序差分方法则不需要。根据贝尔曼不等式,只需要从当前状态到下一状态求解。
- 时序差分方法每步都更新状态值,而蒙特卡罗方法需要等到所有状态结束才更新。
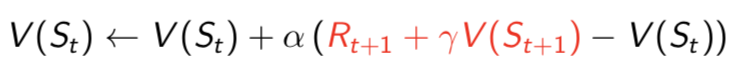
- 蒙特卡罗方法使用最后的目标来求解状态值,而时序差分使用下一状态的估计在每一步调整状态值。
- 蒙特卡罗方法是无偏估计方差较大,时序差分则是有篇估计但估计方差小。
多步的时序差分方法
- 时序差分方法使用当前状态值和下一状态值更新当前状态值,如果使用当前状态值和之后多步的状态值更新当前状态值,就是多步的时序差分方法。
- 当步数到最后的终结状态时,便是蒙特卡罗方法。
- 当步数到下一状态时,便是时序差分方法。
- 多步的时序差分方法,分为前向和后向的时序差分方法。
参考
david siver 课程
https://home.cnblogs.com/u/pinard/
DQN(Deep Reiforcement Learning) 发展历程(三)的更多相关文章
- DQN(Deep Reiforcement Learning) 发展历程(五)
目录 值函数的近似 DQN Nature DQN DDQN Prioritized Replay DQN Dueling DQN 参考 DQN发展历程(一) DQN发展历程(二) DQN发展历程(三) ...
- DQN(Deep Reiforcement Learning) 发展历程(四)
目录 不基于模型的控制 选取动作的方法 在策略上的学习(on-policy) 不在策略上的学习(off-policy) 参考 DQN发展历程(一) DQN发展历程(二) DQN发展历程(三) DQN发 ...
- DQN(Deep Reiforcement Learning) 发展历程(二)
目录 动态规划 使用条件 分类 求解方法 参考 DQN发展历程(一) DQN发展历程(二) DQN发展历程(三) DQN发展历程(四) DQN发展历程(五) 动态规划 动态规划给出了求解强化学习的一种 ...
- DQN(Deep Reiforcement Learning) 发展历程(一)
目录 马尔可夫理论 马尔可夫性质 马尔可夫过程(MP) 马尔可夫奖励过程(MRP) 值函数(value function) MRP求解 马尔可夫决策过程(MDP) 效用函数 优化的值函数 贝尔曼等式 ...
- Deep Reinforcement Learning 基础知识(DQN方面)
Introduction 深度增强学习Deep Reinforcement Learning是将深度学习与增强学习结合起来从而实现从Perception感知到Action动作的端对端学习的一种全新的算 ...
- [DQN] What is Deep Reinforcement Learning
已经成为DL中专门的一派,高大上的样子 Intro: MIT 6.S191 Lecture 6: Deep Reinforcement Learning Course: CS 294: Deep Re ...
- C#与C++的发展历程第三 - C#5.0异步编程巅峰
系列文章目录 1. C#与C++的发展历程第一 - 由C#3.0起 2. C#与C++的发展历程第二 - C#4.0再接再厉 3. C#与C++的发展历程第三 - C#5.0异步编程的巅峰 C#5.0 ...
- 论文笔记之:Dueling Network Architectures for Deep Reinforcement Learning
Dueling Network Architectures for Deep Reinforcement Learning ICML 2016 Best Paper 摘要:本文的贡献点主要是在 DQN ...
- Deep Reinforcement Learning: Pong from Pixels
这是一篇迟来很久的关于增强学习(Reinforcement Learning, RL)博文.增强学习最近非常火!你一定有所了解,现在的计算机能不但能够被全自动地训练去玩儿ATARI(译注:一种游戏机) ...
随机推荐
- 【学习笔记】--- 老男孩学Python,day4 编码,数据类型,字符串方法
今日主要内容 1. 编码 1. 最早的计算机编码是ASCII. 美国人创建的. 包含了英文字母(大写字母, 小写字母). 数字, 标点等特殊字符!@#$% 128个码位 2**7 在此基础上加了一位 ...
- 1.String、StringBuffer与StringBuilder之间区别
1.三者在执行速度方面的比较:StringBuilder > StringBuffer > String 2.String <(StringBuffer,StringBuild ...
- css实现3D立方体旋转特效
先来看运行后出来的效果 它是在不停运行的一个立方体 先来看html部分的代码 <div class="rect-wrap"> <!--舞台元素,设置perspec ...
- Android - Android Studio 解决访问被墙的问题
socks代理配置 项目代理:根目录下的gradle.properties文件 org.gradle.jvmargs=-DsocksProxyHost= 2.全局代理:用户根目录下的.gradle\g ...
- openCV 扩图
1.扩图 import cv2 import numpy as np img=cv2.imread('Test2.jpg',1) width=img.shape[0] height=img.shape ...
- rdlc里面的textbox怎么赋值
通过传递参数来实现 当前在rdlc页面,ctrl+alt+d,打开report data侧边栏 点击report data的Parameters文件夹,右键,添加新的参数,命名.定义类型,譬如命名为R ...
- 如何用 Python 实现 Web 抓取?
[编者按]本文作者为 Blog Bowl 联合创始人 Shaumik Daityari,主要介绍 Web 抓取技术的基本实现原理和方法.文章系国内 ITOM 管理平台 OneAPM 编译呈现,以下为正 ...
- CSS样式----CSS样式表的继承性和层叠性(图文详解)
本文最初于2017-07-29发表于博客园,并在GitHub上持续更新前端的系列文章.欢迎在GitHub上关注我,一起入门和进阶前端. 以下是正文. 本文重点 CSS的继承性 CSS的层叠性 计算权重 ...
- 有关于《Linux C编程一站式学习》(备份)
Linux C编程一站式学习 -- PDF版本,共37章: Linux C编程一站式学习 -- 在线版,来自灰狐: Linux C编程一站式学习 -- 在线版,来自亚嵌教育: Linux C一站式学习 ...
- M5加密字符串
private string GetMD5str(string oldStr) { //将输入转换为ASCII 字符编码 ASCIIEncoding enc = new ASCIIEncoding() ...