DQN(Deep Reiforcement Learning) 发展历程(一)
目录
马尔可夫理论
马尔可夫性质
- P[St+1 | St] = P[St+1 | S1,...,St]
- 给定当前状态 St ,过去的状态可以不用考虑
- 当前状态 St 可以代表过去的所有状态
- 给定当前状态的条件下,未来的状态和过去的状态相互独立。
马尔可夫过程(MP)
- 形式化地描述了强化学习的环境。
- 包括二元组(S,P)
- 根据给定的转移概率矩阵P,从当前状态St转移到下一状态St+1,
- 基于模型的(Model-based):事先给出了转移概率矩阵P
马尔可夫奖励过程(MRP)
- 和马尔可夫过程相比,加入了奖励r,加入了折扣因子gamma,gamma在0~1之间。
- 马尔可夫奖励过程是一个四元组⟨S, P, R, γ⟩
- 需要折扣因子的原因是
- 使未来累积奖励在数学上易于计算
- 由于可能经过某些重复状态,避免累积奖励的计算成死循环
- 用于表示未来的不确定性
- gamma越大表示越看中未来的奖励
值函数(value function)
- 引入了值函数(value function),给每一个状态一个值V,以从当前状态St到评估未来的目标G的累积折扣奖励的大小
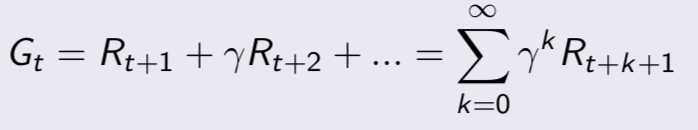
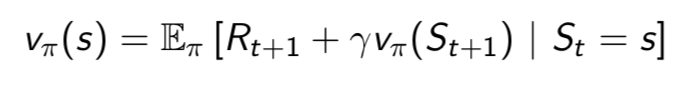
MRP求解
- v = R + γPv (矩阵形式)
- 直接解出上述方程时间复杂度O(n^3), 只适用于一些小规模问题
马尔可夫决策过程(MDP)
- 加入了一个动作因素a,用于每个状态的决策
- MDP是一个五元组⟨S, A, P, R, γ⟩
- 策略policy是从S到A的一个映射
效用函数
- 相比于值函数,加入了一个动作因素

优化的值函数
- 为了求最佳策略,在值函数求解时,选择一个最大的v来更新当前状态对应的v
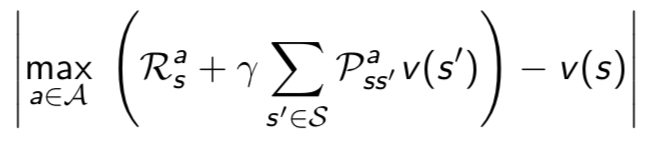
贝尔曼等式
- 和值函数的求解方法相比,不需要从当前状态到目标求解,只需要从当前状态到下一状态即可(根据递推公式)

参考
david siver 课程
https://home.cnblogs.com/u/pinard/
DQN(Deep Reiforcement Learning) 发展历程(一)的更多相关文章
- DQN(Deep Reiforcement Learning) 发展历程(五)
目录 值函数的近似 DQN Nature DQN DDQN Prioritized Replay DQN Dueling DQN 参考 DQN发展历程(一) DQN发展历程(二) DQN发展历程(三) ...
- DQN(Deep Reiforcement Learning) 发展历程(三)
目录 不基于模型(Model-free)的预测 蒙特卡罗方法 时序差分方法 多步的时序差分方法 参考 DQN发展历程(一) DQN发展历程(二) DQN发展历程(三) DQN发展历程(四) DQN发展 ...
- DQN(Deep Reiforcement Learning) 发展历程(四)
目录 不基于模型的控制 选取动作的方法 在策略上的学习(on-policy) 不在策略上的学习(off-policy) 参考 DQN发展历程(一) DQN发展历程(二) DQN发展历程(三) DQN发 ...
- DQN(Deep Reiforcement Learning) 发展历程(二)
目录 动态规划 使用条件 分类 求解方法 参考 DQN发展历程(一) DQN发展历程(二) DQN发展历程(三) DQN发展历程(四) DQN发展历程(五) 动态规划 动态规划给出了求解强化学习的一种 ...
- [DQN] What is Deep Reinforcement Learning
已经成为DL中专门的一派,高大上的样子 Intro: MIT 6.S191 Lecture 6: Deep Reinforcement Learning Course: CS 294: Deep Re ...
- Deep Reinforcement Learning 基础知识(DQN方面)
Introduction 深度增强学习Deep Reinforcement Learning是将深度学习与增强学习结合起来从而实现从Perception感知到Action动作的端对端学习的一种全新的算 ...
- 论文笔记之:Dueling Network Architectures for Deep Reinforcement Learning
Dueling Network Architectures for Deep Reinforcement Learning ICML 2016 Best Paper 摘要:本文的贡献点主要是在 DQN ...
- Deep Reinforcement Learning: Pong from Pixels
这是一篇迟来很久的关于增强学习(Reinforcement Learning, RL)博文.增强学习最近非常火!你一定有所了解,现在的计算机能不但能够被全自动地训练去玩儿ATARI(译注:一种游戏机) ...
- 论文笔记之:Human-level control through deep reinforcement learning
Human-level control through deep reinforcement learning Nature 2015 Google DeepMind Abstract RL 理论 在 ...
随机推荐
- mongodb与mysql区别(超详细)
MySQL是关系型数据库. 优势: 在不同的引擎上有不同 的存储方式. 查询语句是使用传统的sql语句,拥有较为成熟的体系,成熟度很高. 开源数据库的份额在不断增加,mysql的份额页在持续增长. 缺 ...
- SSL certificate problem: unable to get local issuer certificate 的解决方法
今天在进行微信开发获取微信Access_Token时,使用到了php的curl库, 在敲完代码后获取token失败,经过各种排查错误,到了下面这一步 SSL certificate problem: ...
- bower 和 npm 的区别详细介绍
摘要: 本文讲的是bower 和 npm 的区别详细介绍, 简单的说,npm是进行后端开发中,使用的模块安装工具,而bower,是前端的模块安装工具. 比如,在安装express,socket.io时 ...
- SQLServer 学习笔记之超详细基础SQL语句 Part 11
Sqlserver 学习笔记 by:授客 QQ:1033553122 -----------------------接Part 10------------------- DECLARE @myavg ...
- XQuery使用sum求和,提示char不能转换为money解决方法
select axml.value('sum(/root/pro/price)','money') 以上代码提示‘char不能转换为money’的错误,发现值为'0.0E0'.改为: select a ...
- 二叉搜索树(Binary Search Tree)实现及测试
转:http://blog.csdn.net/a19881029/article/details/24379339 实现代码: Node.java //节点类public class Node{ ...
- unity 获取水平FOV
unity中Camera的Field of View是指的垂直FOV,水平FOV可以经过计算得到. 创建脚本如下,把脚本挂载到摄像机上即可得到水平FOV: public class GetHorizo ...
- Git仓库初始化与推送到远端仓库
以下命令为Git仓库初始化,添加远端代码托管仓库,以及推送到远端仓库的命令. 以 "github.com"为远端仓库做示例 # Git 库初始化 git init # 将文件添加到 ...
- 想涨工资吗?那就学习Scala,Golang或Python吧
[编者按]据薪水调查机构 PayScale 提供的数据显示,掌握 Scala,Golang 和 Python 语言以及诸如 Apache Spark 之类的大数据技术,能带来最大的薪水提升.本文作者为 ...
- LeetCode题解之 Longest Common Prefix
1.题目描述 2.问题分析 直接使用循环解决问题 3.代码 string longestCommonPrefix(vector<string>& strs) { string re ...