DQN(Deep Reiforcement Learning) 发展历程(三)
不基于模型(Model-free)的预测
- 无法事先了解状态转移的概率矩阵
蒙特卡罗方法
从开始状态开始,到终结状态,找到一条完整的状态序列,以求解每个状态的值。相比于在整个的状态空间搜索,是一种采样的方法。
- 对于某一状态在同一状态序列中重复出现的,有以下两种方法:
- 只选择第一个状态进行求解,忽略之后的所有相同状态
- 考虑所有的状态,求平均值
- 对于求解每个状态的值,使用平均值代表状态值,根据大数定理,状态数足够多的条件下,该平均值等于状态值。平均值求解有两种方法:
- 存储所有状态后求平均:消耗大量存储空间
- 每次迭代状态都更新当前平均值:
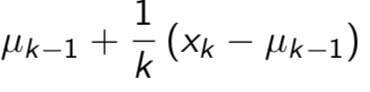
时序差分方法
- 蒙特卡罗方法需要获得从开始到终结的一条完整的状态序列,以求解每个状态的值,时序差分方法则不需要。根据贝尔曼不等式,只需要从当前状态到下一状态求解。
- 时序差分方法每步都更新状态值,而蒙特卡罗方法需要等到所有状态结束才更新。
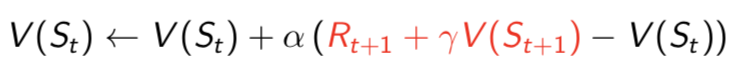
- 蒙特卡罗方法使用最后的目标来求解状态值,而时序差分使用下一状态的估计在每一步调整状态值。
- 蒙特卡罗方法是无偏估计方差较大,时序差分则是有篇估计但估计方差小。
多步的时序差分方法
- 时序差分方法使用当前状态值和下一状态值更新当前状态值,如果使用当前状态值和之后多步的状态值更新当前状态值,就是多步的时序差分方法。
- 当步数到最后的终结状态时,便是蒙特卡罗方法。
- 当步数到下一状态时,便是时序差分方法。
- 多步的时序差分方法,分为前向和后向的时序差分方法。
参考
david siver 课程
https://home.cnblogs.com/u/pinard/
DQN(Deep Reiforcement Learning) 发展历程(三)的更多相关文章
- DQN(Deep Reiforcement Learning) 发展历程(五)
目录 值函数的近似 DQN Nature DQN DDQN Prioritized Replay DQN Dueling DQN 参考 DQN发展历程(一) DQN发展历程(二) DQN发展历程(三) ...
- DQN(Deep Reiforcement Learning) 发展历程(四)
目录 不基于模型的控制 选取动作的方法 在策略上的学习(on-policy) 不在策略上的学习(off-policy) 参考 DQN发展历程(一) DQN发展历程(二) DQN发展历程(三) DQN发 ...
- DQN(Deep Reiforcement Learning) 发展历程(二)
目录 动态规划 使用条件 分类 求解方法 参考 DQN发展历程(一) DQN发展历程(二) DQN发展历程(三) DQN发展历程(四) DQN发展历程(五) 动态规划 动态规划给出了求解强化学习的一种 ...
- DQN(Deep Reiforcement Learning) 发展历程(一)
目录 马尔可夫理论 马尔可夫性质 马尔可夫过程(MP) 马尔可夫奖励过程(MRP) 值函数(value function) MRP求解 马尔可夫决策过程(MDP) 效用函数 优化的值函数 贝尔曼等式 ...
- Deep Reinforcement Learning 基础知识(DQN方面)
Introduction 深度增强学习Deep Reinforcement Learning是将深度学习与增强学习结合起来从而实现从Perception感知到Action动作的端对端学习的一种全新的算 ...
- [DQN] What is Deep Reinforcement Learning
已经成为DL中专门的一派,高大上的样子 Intro: MIT 6.S191 Lecture 6: Deep Reinforcement Learning Course: CS 294: Deep Re ...
- C#与C++的发展历程第三 - C#5.0异步编程巅峰
系列文章目录 1. C#与C++的发展历程第一 - 由C#3.0起 2. C#与C++的发展历程第二 - C#4.0再接再厉 3. C#与C++的发展历程第三 - C#5.0异步编程的巅峰 C#5.0 ...
- 论文笔记之:Dueling Network Architectures for Deep Reinforcement Learning
Dueling Network Architectures for Deep Reinforcement Learning ICML 2016 Best Paper 摘要:本文的贡献点主要是在 DQN ...
- Deep Reinforcement Learning: Pong from Pixels
这是一篇迟来很久的关于增强学习(Reinforcement Learning, RL)博文.增强学习最近非常火!你一定有所了解,现在的计算机能不但能够被全自动地训练去玩儿ATARI(译注:一种游戏机) ...
随机推荐
- Hadoop大数据初入门----haddop伪分布式安装
一.hadoop解决了什么问题 hdfs 解决了海量数据的分布式存储,高可靠,易扩展,高吞吐量mapreduce 解决了海量数据的分析处理,通用性强,易开发,健壮性 yarn 解决了资源管理调度 二. ...
- EasyUI 通过 Combobox 实现 AutoComplete 效果
朋友在做一个web程序,用的EasyUI框架,让我帮忙实现一个自动提示功能.由于之前我也没用过EasyUI框架,就想到了jQueryUI有 AutoComplete 插件,就想直接拿过来用. 但当我将 ...
- session与cookie的区别和用法
一.session 1.保存在服务器的,每个人存一份2.可以存储任何类型数据3.有一个默认过期时间注意:在所有使用session的页面最顶端要开启session---session_start();存 ...
- Nginx的日志剖析
1.访问日志(access.log) Nginx的访问日志就是一个文件,它存储着每个用户对网站的访问请求,这个功能是有ngx_http_log_module模块来负责的,这个文件存在的主要目的就是为了 ...
- React Native常用第三方组件汇总--史上最全 之一
React Native 项目常用第三方组件汇总: react-native-animatable 动画 react-native-carousel 轮播 react-native-countdown ...
- vm virtualBox下 centos7 Linux系统 与本地 window 系统 网络连接 配置
由于要模拟生产环境开发,所以要在自己的电脑上安装虚拟机,这里做一下记录. centos与本机网络连接 1. 环境 虚拟机 VirtualBox-5.2.0-118431-Win Linux镜像 Cen ...
- Python Django框架笔记(五):模型
#前言部分来自Django Book (一) 前言 大多数web应用本质上: 1. 每个页面都是将数据库的数据以HTML格式进行展现. 2. 向用户提供修改数据库数据的方法.(例如:注册.发表评 ...
- 团队项目个人进展——Day10
一.昨天工作总结 冲刺第十天,与小组成员任务合并,并解决结合后的一些问题. 二.遇到的问题 界面还是不太和谐 三.今日工作规划 对页面的布局.wxss做了一些修改
- selenium 校验文件下载成功
转自: http://www.seleniumeasy.com/selenium-tutorials/verify-file-after-downloading-using-webdriver-jav ...
- textbox只允许输入数字
private void txtUserId_KeyPress(object sender, KeyPressEventArgs e) { //如果输入的不是数字键,也不是回车键.Backspace键 ...