cuda中threadIdx、blockIdx、blockDim和gridDim的使用
threadIdx是一个uint3类型,表示一个线程的索引。
blockIdx是一个uint3类型,表示一个线程块的索引,一个线程块中通常有多个线程。
blockDim是一个dim3类型,表示线程块的大小。
gridDim是一个dim3类型,表示网格的大小,一个网格中通常有多个线程块。
下面这张图比较清晰的表示的几个概念的关系:
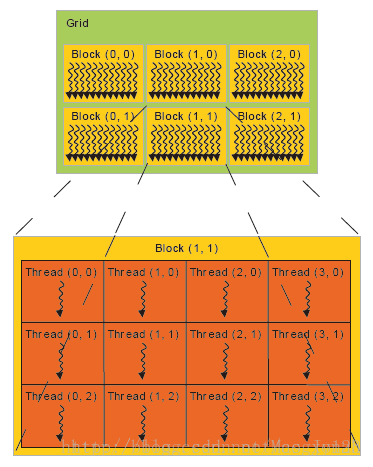
cuda 通过<<< >>>符号来分配索引线程的方式,我知道的一共有15种索引方式。
下面程序展示了这15种索引方式:
#include "cuda_runtime.h"
#include "device_launch_parameters.h" #include <stdio.h>
#include <stdlib.h>
#include <iostream> using namespace std; //thread 1D
__global__ void testThread1(int *c, const int *a, const int *b)
{
int i = threadIdx.x;
c[i] = b[i] - a[i];
} //thread 2D
__global__ void testThread2(int *c, const int *a, const int *b)
{
int i = threadIdx.x + threadIdx.y*blockDim.x;
c[i] = b[i] - a[i];
} //thread 3D
__global__ void testThread3(int *c, const int *a, const int *b)
{
int i = threadIdx.x + threadIdx.y*blockDim.x + threadIdx.z*blockDim.x*blockDim.y;
c[i] = b[i] - a[i];
} //block 1D
__global__ void testBlock1(int *c, const int *a, const int *b)
{
int i = blockIdx.x;
c[i] = b[i] - a[i];
} //block 2D
__global__ void testBlock2(int *c, const int *a, const int *b)
{
int i = blockIdx.x + blockIdx.y*gridDim.x;
c[i] = b[i] - a[i];
} //block 3D
__global__ void testBlock3(int *c, const int *a, const int *b)
{
int i = blockIdx.x + blockIdx.y*gridDim.x + blockIdx.z*gridDim.x*gridDim.y;
c[i] = b[i] - a[i];
} //block-thread 1D-1D
__global__ void testBlockThread1(int *c, const int *a, const int *b)
{
int i = threadIdx.x + blockDim.x*blockIdx.x;
c[i] = b[i] - a[i];
} //block-thread 1D-2D
__global__ void testBlockThread2(int *c, const int *a, const int *b)
{
int threadId_2D = threadIdx.x + threadIdx.y*blockDim.x;
int i = threadId_2D+ (blockDim.x*blockDim.y)*blockIdx.x;
c[i] = b[i] - a[i];
} //block-thread 1D-3D
__global__ void testBlockThread3(int *c, const int *a, const int *b)
{
int threadId_3D = threadIdx.x + threadIdx.y*blockDim.x + threadIdx.z*blockDim.x*blockDim.y;
int i = threadId_3D + (blockDim.x*blockDim.y*blockDim.z)*blockIdx.x;
c[i] = b[i] - a[i];
} //block-thread 2D-1D
__global__ void testBlockThread4(int *c, const int *a, const int *b)
{
int blockId_2D = blockIdx.x + blockIdx.y*gridDim.x;
int i = threadIdx.x + blockDim.x*blockId_2D;
c[i] = b[i] - a[i];
} //block-thread 3D-1D
__global__ void testBlockThread5(int *c, const int *a, const int *b)
{
int blockId_3D = blockIdx.x + blockIdx.y*gridDim.x + blockIdx.z*gridDim.x*gridDim.y;
int i = threadIdx.x + blockDim.x*blockId_3D;
c[i] = b[i] - a[i];
} //block-thread 2D-2D
__global__ void testBlockThread6(int *c, const int *a, const int *b)
{
int threadId_2D = threadIdx.x + threadIdx.y*blockDim.x;
int blockId_2D = blockIdx.x + blockIdx.y*gridDim.x;
int i = threadId_2D + (blockDim.x*blockDim.y)*blockId_2D;
c[i] = b[i] - a[i];
} //block-thread 2D-3D
__global__ void testBlockThread7(int *c, const int *a, const int *b)
{
int threadId_3D = threadIdx.x + threadIdx.y*blockDim.x + threadIdx.z*blockDim.x*blockDim.y;
int blockId_2D = blockIdx.x + blockIdx.y*gridDim.x;
int i = threadId_3D + (blockDim.x*blockDim.y*blockDim.z)*blockId_2D;
c[i] = b[i] - a[i];
} //block-thread 3D-2D
__global__ void testBlockThread8(int *c, const int *a, const int *b)
{
int threadId_2D = threadIdx.x + threadIdx.y*blockDim.x;
int blockId_3D = blockIdx.x + blockIdx.y*gridDim.x + blockIdx.z*gridDim.x*gridDim.y;
int i = threadId_2D + (blockDim.x*blockDim.y)*blockId_3D;
c[i] = b[i] - a[i];
} //block-thread 3D-3D
__global__ void testBlockThread9(int *c, const int *a, const int *b)
{
int threadId_3D = threadIdx.x + threadIdx.y*blockDim.x + threadIdx.z*blockDim.x*blockDim.y;
int blockId_3D = blockIdx.x + blockIdx.y*gridDim.x + blockIdx.z*gridDim.x*gridDim.y;
int i = threadId_3D + (blockDim.x*blockDim.y*blockDim.z)*blockId_3D;
c[i] = b[i] - a[i];
} void addWithCuda(int *c, const int *a, const int *b, unsigned int size)
{
int *dev_a = ;
int *dev_b = ;
int *dev_c = ; cudaSetDevice(); cudaMalloc((void**)&dev_c, size * sizeof(int));
cudaMalloc((void**)&dev_a, size * sizeof(int));
cudaMalloc((void**)&dev_b, size * sizeof(int)); cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice); //testThread1<<<1, size>>>(dev_c, dev_a, dev_b); //uint3 s;s.x = size/5;s.y = 5;s.z = 1;
//testThread2 <<<1,s>>>(dev_c, dev_a, dev_b); //uint3 s; s.x = size / 10; s.y = 5; s.z = 2;
//testThread3<<<1, s >>>(dev_c, dev_a, dev_b); //testBlock1<<<size,1 >>>(dev_c, dev_a, dev_b); //uint3 s; s.x = size / 5; s.y = 5; s.z = 1;
//testBlock2<<<s, 1 >>>(dev_c, dev_a, dev_b); //uint3 s; s.x = size / 10; s.y = 5; s.z = 2;
//testBlock3<<<s, 1 >>>(dev_c, dev_a, dev_b); //testBlockThread1<<<size/10, 10>>>(dev_c, dev_a, dev_b); //uint3 s1; s1.x = size / 100; s1.y = 1; s1.z = 1;
//uint3 s2; s2.x = 10; s2.y = 10; s2.z = 1;
//testBlockThread2 << <s1, s2 >> >(dev_c, dev_a, dev_b); //uint3 s1; s1.x = size / 100; s1.y = 1; s1.z = 1;
//uint3 s2; s2.x = 10; s2.y = 5; s2.z = 2;
//testBlockThread3 << <s1, s2 >> >(dev_c, dev_a, dev_b); //uint3 s1; s1.x = 10; s1.y = 10; s1.z = 1;
//uint3 s2; s2.x = size / 100; s2.y = 1; s2.z = 1;
//testBlockThread4 << <s1, s2 >> >(dev_c, dev_a, dev_b); //uint3 s1; s1.x = 10; s1.y = 5; s1.z = 2;
//uint3 s2; s2.x = size / 100; s2.y = 1; s2.z = 1;
//testBlockThread5 << <s1, s2 >> >(dev_c, dev_a, dev_b); //uint3 s1; s1.x = size / 100; s1.y = 10; s1.z = 1;
//uint3 s2; s2.x = 5; s2.y = 2; s2.z = 1;
//testBlockThread6 << <s1, s2 >> >(dev_c, dev_a, dev_b); //uint3 s1; s1.x = size / 100; s1.y = 5; s1.z = 1;
//uint3 s2; s2.x = 5; s2.y = 2; s2.z = 2;
//testBlockThread7 << <s1, s2 >> >(dev_c, dev_a, dev_b); //uint3 s1; s1.x = 5; s1.y = 2; s1.z = 2;
//uint3 s2; s2.x = size / 100; s2.y = 5; s2.z = 1;
//testBlockThread8 <<<s1, s2 >>>(dev_c, dev_a, dev_b); uint3 s1; s1.x = ; s1.y = ; s1.z = ;
uint3 s2; s2.x = size / ; s2.y = ; s2.z = ;
testBlockThread9<<<s1, s2 >>>(dev_c, dev_a, dev_b); cudaMemcpy(c, dev_c, size*sizeof(int), cudaMemcpyDeviceToHost); cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c); cudaGetLastError();
} int main()
{
const int n = ; int *a = new int[n];
int *b = new int[n];
int *c = new int[n];
int *cc = new int[n]; for (int i = ; i < n; i++)
{
a[i] = rand() % ;
b[i] = rand() % ;
c[i] = b[i] - a[i];
} addWithCuda(cc, a, b, n); FILE *fp = fopen("out.txt", "w");
for (int i = ; i < n; i++)
fprintf(fp, "%d %d\n", c[i], cc[i]);
fclose(fp); bool flag = true;
for (int i = ; i < n; i++)
{
if (c[i] != cc[i])
{
flag = false;
break;
}
} if (flag == false)
printf("no pass");
else
printf("pass"); cudaDeviceReset(); delete[] a;
delete[] b;
delete[] c;
delete[] cc; getchar();
return ;
}
这里只保留了3D-3D方式,注释了其余14种方式,所有索引方式均测试通过。
还是能看出一些规律的:)
cuda中threadIdx、blockIdx、blockDim和gridDim的使用的更多相关文章
- GPU CUDA编程中threadIdx, blockIdx, blockDim, gridDim之间的区别与联系
前期写代码的时候都会困惑这个实际的threadIdx(tid,实际的线程id)到底是多少,自己写出来的对不对,今天经过自己一些小例子的推敲,以及找到官网的相关介绍,总算自己弄清楚了. 在启动kerne ...
- CUDA中的常量内存__constant__
GPU包含数百个数学计算单元,具有强大的处理运算能力,可以强大到计算速率高于输入数据的速率,即充分利用带宽,满负荷向GPU传输数据还不够它计算的.CUDA C除全局内存和共享内存外,还支持常量内存,常 ...
- CUDA中关于C++特性的限制
CUDA中关于C++特性的限制 CUDA官方文档中对C++语言的支持和限制,懒得每次看英文文档,自己尝试翻译一下(没有放lambda表达式的相关内容,太过于复杂,我选择不用).官方文档https:// ...
- CUDA中并行规约(Parallel Reduction)的优化
转自: http://hackecho.com/2013/04/cuda-parallel-reduction/ Parallel Reduction是NVIDIA-CUDA自带的例子,也几乎是所有C ...
- OpenCV二维Mat数组(二级指针)在CUDA中的使用
CUDA用于并行计算非常方便,但是GPU与CPU之间的交互,比如传递参数等相对麻烦一些.在写CUDA核函数的时候形参往往会有很多个,动辄达到10-20个,如果能够在CPU中提前把数据组织好,比如使用二 ...
- cuda中当数组数大于线程数的处理方法
参考stackoverflow一篇帖子的处理方法:https://stackoverflow.com/questions/26913683/different-way-to-index-threads ...
- CUDA中多维数组以及多维纹理内存的使用
纹理存储器(texture memory)是一种只读存储器,由GPU用于纹理渲染的图形专用单元发展而来,因此也提供了一些特殊功能.纹理存储器中的数据位于显存,但可以通过纹理缓存加速读取.在纹理存储器中 ...
- cuda中当元素个数超过线程个数时的处理案例
项目打包下载 当向量元素超过线程个数时的情况 向量元素个数为(33 * 1024)/(128 * 128)=2.x倍 /* * Copyright 1993-2010 NVIDIA Corporati ...
- CUDA中使用多维数组
今天想起一个问题,看到的绝大多数CUDA代码都是使用的一维数组,是否可以在CUDA中使用一维数组,这是一个问题,想了各种问题,各种被77的错误状态码和段错误折磨,最后发现有一个cudaMallocMa ...
随机推荐
- tensorflow进阶篇-4(损失函数3)
Softmax交叉熵损失函数(Softmax cross-entropy loss)是作用于非归一化的输出结果只针对单个目标分类的计算损失.通过softmax函数将输出结果转化成概率分布,然后计算真值 ...
- JNI 简单例子
原文:http://www.cnblogs.com/youxilua/archive/2011/09/16/2178554.html 1,先把c语言的编译环境搭建好,windows下这里使用mingw ...
- Struts2+AJAX+JQuery 实现用户登入与注册功能。
要求 必备知识 JAVA/Struts2,JS/JQuery,HTML/CSS基础语法. 开发环境 MyEclipse 10 演示地址 演示地址 预览截图(抬抬你的鼠标就可以看到演示地址哦): 关于U ...
- 自制“低奢内”CSS3登入表单,包含JS验证,请别嫌弃哦。
要求 必备知识 基本了解CSS语法,初步了解CSS3语法知识.和JS/JQuery基本语法. 开发环境 Adobe Dreamweaver CS6 演示地址 演示地址 预览截图(抬抬你的鼠标就可以看到 ...
- Docker环境的持续部署优化实践
最近两周优化了我们持续部署的程序,收效显著,记录下来分享给大家 背景介绍 那年公司快速成长,频繁上线新项目,每上线一个项目,就需要新申请一批机器,初始化,部署依赖的服务环境,一个脚本行天下 那年项目发 ...
- Conditional特性用法
说明:根据预处理标识符执行方法.Conditional 特性是 ConditionalAttribute 的别名,可应用于方法或属性类.相对于#if和#endif,更灵活更简洁和不易出错. 例如: # ...
- Java Web 项目简单配置 Spring MVC进行访问
所需要的 jar 包下载地址: https://download.csdn.net/download/qq_35318576/10275163 配置一: 新建 springmvc.xml 并编辑如下内 ...
- nodejs的__dirname,__filename,process.cwd()区别
假定我们有这样一个mynode的node项目在User/leinov/porject/文件夹下,cli是一个可执行文件 |-- mynode |-- bin |-- cli.js |-- src |- ...
- SQL SERVER中LIKE使用变量类型输出结果不同
前言:Sql Server中LIKE里面使用不同的变量类型导致查询结果不一致的问题,其实看似有点让人不解的现象背后实质跟数据类型的实现有关. 一.我们先来创建示例演示具体操作 CREATE TABLE ...
- JVM调优命令-jmap
jmap JVM Memory Map命令用于生成heap dump文件,如果不使用这个命令,还可以使用-XX:+HeapDumpOnOutOfMemoryError参数来让虚拟机出现OOM的时候自动 ...