用scrapy爬取京东的数据
本文目的是使用scrapy爬取京东上所有的手机数据,并将数据保存到MongoDB中。
一、项目介绍
主要目标
1、使用scrapy爬取京东上所有的手机数据
2、将爬取的数据存储到MongoDB
环境
win7、python2、pycharm
技术
1、数据采集:scrapy
2、数据存储:MongoDB
难点分析
和其他的电商网站相比,京东的搜索类爬取主要有以下几个难点:
1、搜索一个商品时,一开始显示的商品数量为30个,当下拉这一页 时,又会出现30个商品,这就是60个商品了,前30个可以直接 从原网页上拿到,后30个却在另一个隐藏链接中,要访问这两个 链接,才能拿到一页的所有数据。
2、隐藏链接的构造,发现最后的那个show_items字段其实是前30 个商品的id。
3、直接反问隐藏链接被拒绝访问,京东的服务器会检查链接的来源, 只有来自当前页的链接他才会允许访问。
4、前30个商品的那一页的链接page字段的自增是1、3、5。。。这 样的,而后30个的自增是2、4、6。。。这样的。
下面看具体的分析。
二、网页分析
首先打开京东的首页搜索“手机”:
一开始他的地址是这样的:
转到第2页,会看到,他的地址变成这样子了:

后面的字段全变了,那么第2页的url明显更容易看出信息,主要修改的字段其实就是keyword,page,其实还有一个wq字段,这个得值和keyword是一样的。
那么我们就可以使用第二页的url来抓取数据,可以看出第2页的url中page字段为3。
但是查看原网页的时候却只有30条数据,还有30条数据隐藏在一个网页中:

从这里面可以看到他的Request url。
再看一下他的response:

里面正好就是我们需要的信息。
看一下他的参数请求:
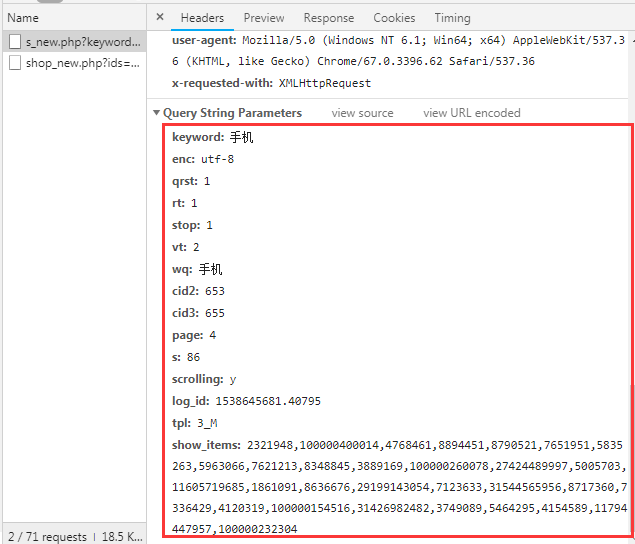
这些参数不难以构造,一些未知的参数可以删掉,而那个show_items参数,其实就是前30个商品的id:
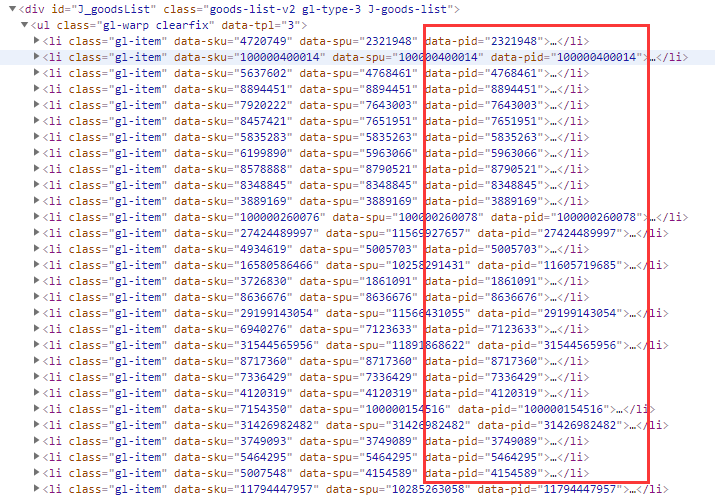
准确来说是data-pid
此时如果我们直接在浏览器上访问这个Request url,他会跳转到https://www.jd.com/?se=deny页面,并没有我们需要的信息,其实这个主要是请求头中的referer参数
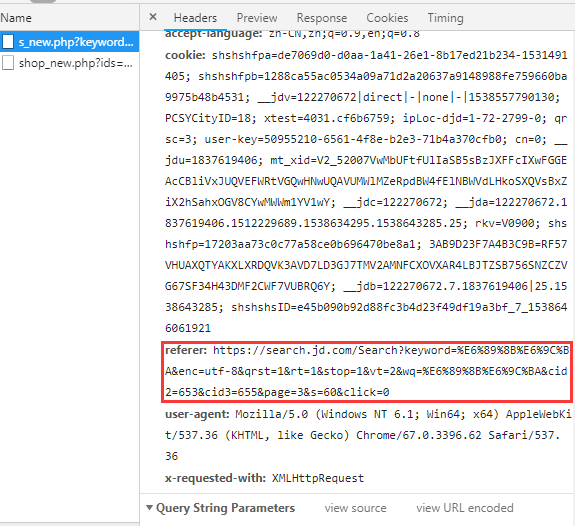
这个参数就是在地址栏上的那个url,当然在爬取的时候我们还可以加个user-agent,那么分析完毕,我们开始敲代码。
三、爬取
创建一个scrapy爬虫项目:
scrapy startproject jdphone
生成一个爬虫:
scrapy genspider jd jd.com
文件结构:
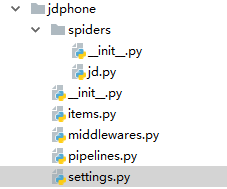
items: items.py
# -*- coding: utf-8 -*-
import scrapy class JdphoneItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field() # 标题 price = scrapy.Field() # 价格 comment_num = scrapy.Field() # 评价条数 url = scrapy.Field() # 商品链接 info = scrapy.Field() # 详细信息
spiders: jd.py
# -*- coding: utf-8 -*-
import scrapy
from ..items import JdphoneItem
import sys reload(sys)
sys.setdefaultencoding("utf-8") class JdSpider(scrapy.Spider):
name = 'jd'
allowed_domains = ['jd.com'] # 有的时候写个www.jd.com会导致search.jd.com无法爬取
keyword = "手机"
page = 1
url = 'https://search.jd.com/Search?keyword=%s&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%s&cid2=653&cid3=655&page=%d&click=0'
next_url = 'https://search.jd.com/s_new.php?keyword=%s&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%s&cid2=653&cid3=655&page=%d&scrolling=y&show_items=%s' def start_requests(self):
yield scrapy.Request(self.url % (self.keyword, self.keyword, self.page), callback=self.parse) def parse(self, response):
"""
爬取每页的前三十个商品,数据直接展示在原网页中
:param response:
:return:
"""
ids = []
for li in response.xpath('//*[@id="J_goodsList"]/ul/li'):
item = JdphoneItem() title = li.xpath('div/div/a/em/text()').extract() # 标题
price = li.xpath('div/div/strong/i/text()').extract() # 价格
comment_num = li.xpath('div/div/strong/a/text()').extract() # 评价条数
id = li.xpath('@data-pid').extract() # id
ids.append(''.join(id)) url = li.xpath('div/div[@class="p-name p-name-type-2"]/a/@href').extract() # 需要跟进的链接 item['title'] = ''.join(title)
item['price'] = ''.join(price)
item['comment_num'] = ''.join(comment_num)
item['url'] = ''.join(url) if item['url'].startswith('//'):
item['url'] = 'https:' + item['url']
elif not item['url'].startswith('https:'):
item['info'] = None
yield item
continue yield scrapy.Request(item['url'], callback=self.info_parse, meta={"item": item}) headers = {'referer': response.url}
# 后三十页的链接访问会检查referer,referer是就是本页的实际链接
# referer错误会跳转到:https://www.jd.com/?se=deny
self.page += 1
yield scrapy.Request(self.next_url % (self.keyword, self.keyword, self.page, ','.join(ids)),
callback=self.next_parse, headers=headers) def next_parse(self, response):
"""
爬取每页的后三十个商品,数据展示在一个特殊链接中:url+id(这个id是前三十个商品的id)
:param response:
:return:
"""
for li in response.xpath('//li[@class="gl-item"]'):
item = JdphoneItem()
title = li.xpath('div/div/a/em/text()').extract() # 标题
price = li.xpath('div/div/strong/i/text()').extract() # 价格
comment_num = li.xpath('div/div/strong/a/text()').extract() # 评价条数
url = li.xpath('div/div[@class="p-name p-name-type-2"]/a/@href').extract() # 需要跟进的链接 item['title'] = ''.join(title)
item['price'] = ''.join(price)
item['comment_num'] = ''.join(comment_num)
item['url'] = ''.join(url) if item['url'].startswith('//'):
item['url'] = 'https:' + item['url']
elif not item['url'].startswith('https:'):
item['info'] = None
yield item
continue yield scrapy.Request(item['url'], callback=self.info_parse, meta={"item": item}) if self.page < 200:
self.page += 1
yield scrapy.Request(self.url % (self.keyword, self.keyword, self.page), callback=self.parse) def info_parse(self, response):
"""
链接跟进,爬取每件商品的详细信息,所有的信息都保存在item的一个子字段info中
:param response:
:return:
"""
item = response.meta['item']
item['info'] = {}
type = response.xpath('//div[@class="inner border"]/div[@class="head"]/a/text()').extract()
name = response.xpath('//div[@class="item ellipsis"]/text()').extract()
item['info']['type'] = ''.join(type)
item['info']['name'] = ''.join(name) for div in response.xpath('//div[@class="Ptable"]/div[@class="Ptable-item"]'):
h3 = ''.join(div.xpath('h3/text()').extract())
if h3 == '':
h3 = "未知"
dt = div.xpath('dl/dt/text()').extract()
dd = div.xpath('dl/dd[not(@class)]/text()').extract()
item['info'][h3] = {}
for t, d in zip(dt, dd):
item['info'][h3][t] = d
yield item
item pipeline: pipelines.py
# -*- coding: utf-8 -*-
from scrapy.conf import settings
from pymongo import MongoClient class JdphonePipeline(object):
def __init__(self):
# 获取setting中主机名,端口号和集合名
host = settings['MONGODB_HOST']
port = settings['MONGODB_PORT']
dbname = settings['MONGODB_DBNAME']
col = settings['MONGODB_COL'] # 创建一个mongo实例
client = MongoClient(host=host,port=port) # 访问数据库
db = client[dbname] # 访问集合
self.col = db[col] def process_item(self, item, spider):
data = dict(item)
self.col.insert(data)
return item
setting: setting.py
# -*- coding: utf-8 -*-
BOT_NAME = 'jdphone' SPIDER_MODULES = ['jdphone.spiders']
NEWSPIDER_MODULE = 'jdphone.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36' # Obey robots.txt rules
ROBOTSTXT_OBEY = True # 主机环回地址
MONGODB_HOST = '127.0.0.1'
# 端口号,默认27017
MONGODB_POST = 27017
# 设置数据库名称
MONGODB_DBNAME = 'JingDong'
# 设置集合名称
MONGODB_COL = 'JingDongPhone' ITEM_PIPELINES = {
'jdphone.pipelines.JdphonePipeline': 300,
}
其他的文件都不做改变。
运行爬虫:
scrapy crawl jd
等待几分钟后,数据都存储到了MongoDB中了,现在来看一看MongoDB中的数据。
四、检查数据
在命令行中开启mongo:
看一下数据库:
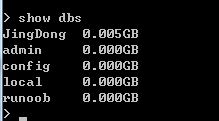
发现JingDong中有5M数据。
看一下具体状态:
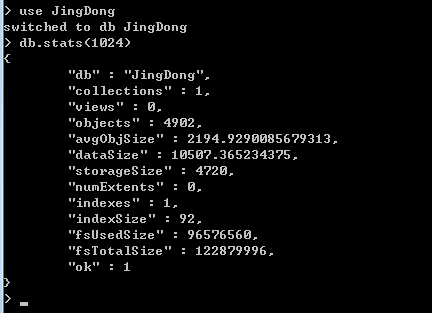
硬盘上的数据大小为4720KB,共4902条数据
最后来看一下数据:

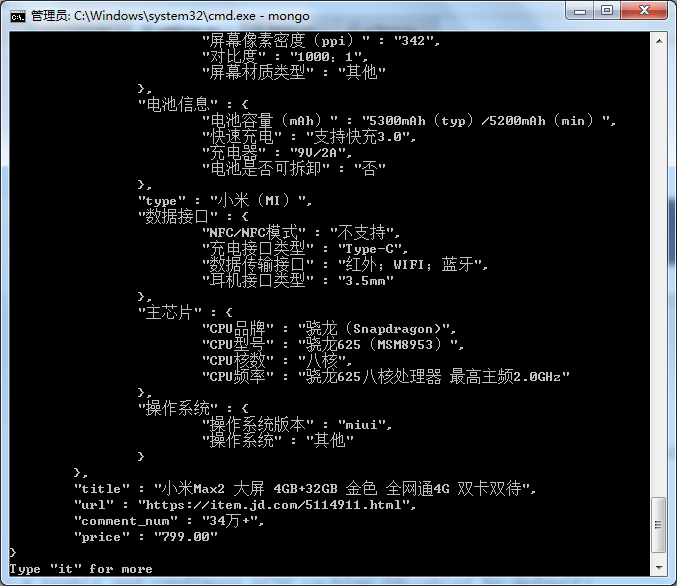
数据保存成功!
用scrapy爬取京东的数据的更多相关文章
- Java实现爬取京东手机数据
Java实现爬取京东手机数据 最近看了某马的Java爬虫视频,看完后自己上手操作了下,基本达到了爬数据的要求,HTML页面源码也刚好复习了下,之前发布两篇关于简单爬虫的文章,也刚好用得上.项目没什么太 ...
- webMagic+RabbitMQ+ES爬取京东建材数据
本次爬虫所要爬取的数据为京东建材数据,在爬取京东的过程中,发现京东并没有做反爬虫动作,所以爬取的过程还是比较顺利的. 为什么要用WebMagic: WebMagic作为一款轻量级的Java爬虫框架,可 ...
- scrapy爬取京东iPhone11评论(一)
咨询行业中经常接触到文本类信息,无论是分词做词云图,还是整理编码分析用,都非常具有价值. 本文将记录使用scrapy框架爬取京东IPhone11评论的过程,由于一边学习一边实践,更新稍慢请见谅. 1. ...
- 爬虫(十七):Scrapy框架(四) 对接selenium爬取京东商品数据
1. Scrapy对接Selenium Scrapy抓取页面的方式和requests库类似,都是直接模拟HTTP请求,而Scrapy也不能抓取JavaScript动态谊染的页面.在前面的博客中抓取Ja ...
- Scrapy爬取豆瓣图书数据并写入MySQL
项目地址 BookSpider 介绍 本篇涉及的内容主要是获取分类下的所有图书数据,并写入MySQL 准备 Python3.6.Scrapy.Twisted.MySQLdb等 演示 代码 一.创建项目 ...
- 用scrapy爬取京东商城的商品信息
软件环境: gevent (1.2.2) greenlet (0.4.12) lxml (4.1.1) pymongo (3.6.0) pyOpenSSL (17.5.0) requests (2.1 ...
- C#爬取京东手机数据+PowerBI数据可视化展示
此系列博文链接 C#爬虫基本知识 Html Agility Pack解析html TODO: EF6中基本认识. EF6操作mysql MySQL乱码问题 C#爬虫 在开头贴一下github仓库地址, ...
- Scrapy爬取到的中文数据乱码问题处理
Scrapy爬取到中文数据默认是 Unicode编码的,于是显示是这样的: "country": ["\u56fd\u4ea7\u6c7d\u8f66\u6807\u5f ...
- scrapy爬取booking酒店评论数据
# scrapy爬取酒店评论数据 -- 代码 here:github地址:https://github.com/760730895/scrapy_Booking-- 采用scrapy爬取酒店评论数据 ...
随机推荐
- ueditor的上传文件漏洞(c#)
项目中使用了ueditor,安全测试发现一个漏洞,涉及漏洞的文件名字为UploadHandler.cs,其中有一个方法: private bool CheckFileType(string filen ...
- div+css感悟
div+css感觉很简单,可是真正做起来一些小细节把握不好,这个网页的布局也是完成不了的.今天学习了一些技巧方法现在分享下: 即一个原则,网页由一个个的大盒子组成,一个个的大盒子里面装着一个个的小盒子 ...
- JVM调优命令-jps
JVM Process Status Tool,显示指定系统内所有的HotSpot虚拟机进程. 命令格式 1 jps [options] [hostid] options参数-l : 输出主类全名或j ...
- hdu 6166 Senior Pan
http://acm.hdu.edu.cn/showproblem.php?pid=6166 题意: 给出一张无向图,给定k个特殊点 求这k个特殊点两两之间的最短路 二进制分组 枚举一位二进制位 这一 ...
- crontab定时任务2_net
2017年2月25日, 星期六 crontab定时任务2_net 1.先来一个小小的例子 查看当前路径: [root@root test]# pwd /home/admin/test [root@ro ...
- HDU 4608 I-number 2013 Multi-University Training Contest 1 1009题
题目大意:输入一个数x,求一个对应的y,这个y满足以下条件,第一,y>x,第二,y 的各位数之和能被10整除,第三,求满足前两个条件的最小的y. 解题报告:一个模拟题,比赛的时候确没过,感觉这题 ...
- 洛谷 P1006 传纸条 多维DP
传纸条详解: 蒟蒻最近接到了练习DP的通知,于是跑来试炼场看看:发现有点难(毕竟是蒟蒻吗)便去翻了翻题解,可怎么都看不懂.为什么呢?蒟蒻发现题解里都非常详细的讲了转移方程,讲了降维优化,但这题新颖之处 ...
- 转载 为什么print在Python 3中变成了函数?
转载自编程派http://codingpy.com/article/why-print-became-a-function-in-python-3/ 原作者:Brett Cannon 原文链接:htt ...
- elasticsearch安装ik分词器(非极速版)
1.下载下载地址为: https://github.com/medcl/elasticsearch-analysis-ik 2.解压把下载的 elasticsearch-analysis-ik.zip ...
- oracle日期、转换函数
转换函数 日期类型转换成字符类型 select to_char(sysdate) s1, --14-3月 -16 to_char(sysdate, 'yyyy-mm-dd') s2, - ...