scrapy中XMLFeedSpider
爬取案例:
目标网站:
url = 'http://www.chinanews.com/rss/scroll-news.xml'
页面特点:

先创建爬虫项目:

也可以查看爬虫类:
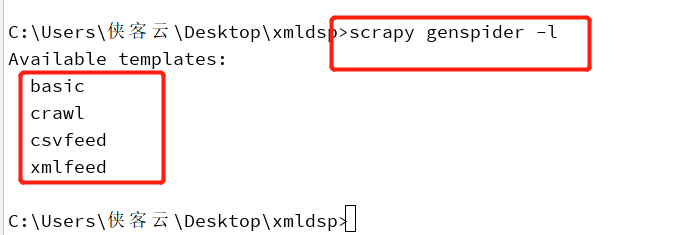
创建xmlFeed 爬虫可以用:
scrapy genspider -t xmlfeed cnew chinanews.com

2. 或可以先创建普通爬虫,再将普通的scrapy爬虫类改为XMLFeedSpider 爬虫类

该爬虫代码:
# -*- coding: utf-8 -*-
import scrapy
from scrapy.spiders import XMLFeedSpider
from ..items import FeedItem
class NewsSpider(XMLFeedSpider):
name = 'news'
#allowed_domains = ['www.chinanews.com']
start_urls = ['http://www.chinanews.com/rss/scroll-news.xml']
#iterator = 'itetnodes'
#itertag = 'item' def parse_node(self, response, node): # item = FeedItem()
item ={}
item['title'] = node.xpath('title/text()').extract_first()
item['link'] = node.xpath('link/text()').extract_first()
item['desc'] =node.xpath('description/text()').extract_first()
item['pub_date'] = node.xpath('pubDate/text()').extract_first() print(item) yield item
3. 将settings中的配置
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
4. 启动爬虫
scrapy crawl news --nolog
5.爬取效果

scrapy中XMLFeedSpider的更多相关文章
- Scrapy中使用Django的Model访问数据库
Scrapy中使用Django的Model进行数据库访问 当已存在Django项目的时候,直接引入Django的Model来使用比较简单 # 使用以下语句添加Django项目的目录到path impo ...
- scrapy中的下载器中间件
scrapy中的下载器中间件 下载中间件 下载器中间件是介于Scrapy的request/response处理的钩子框架. 是用于全局修改Scrapy request和response的一个轻量.底层 ...
- Scrapy中使用cookie免于验证登录和模拟登录
Scrapy中使用cookie免于验证登录和模拟登录 引言 python爬虫我认为最困难的问题一个是ip代理,另外一个就是模拟登录了,更操蛋的就是模拟登录了之后还有验证码,真的是不让人省心,不过既然有 ...
- scrapy 中日志的使用
我在后台调试 在后台调试scrapy spider的时候,总是觉得后台命令窗口 打印的东西太多了不便于观察日志,因此需要一个日志文件记录信息,这样以后会 方便查找问题. 分两种方法吧. 1.简单粗暴. ...
- scrapy中response.body 与 response.text区别
scrapy中response.body 与 response.text区别 body http响应正文, byte类型 text 文本形式的http正文,str类型,它是response.body经 ...
- scrapy中的request
scrapy中的request 初始化参数 class scrapy.http.Request( url [ , callback, method='GET', headers, body, cook ...
- [转]scrapy中的logging
logging模块是Python提供的自己的程序日志记录模块. 在大型软件使用过程中,出现的错误有时候很难进行重现,因此需要通过分析日志来确认错误位置,这也是写程序时要使用日志的最重要的原因. scr ...
- 论Scrapy中的数据持久化
引入 Scrapy的数据持久化,主要包括存储到数据库.文件以及内置数据存储. 那我们今天就来讲讲如何把Scrapy中的数据存储到数据库和文件当中. 终端指令存储 保证爬虫文件的parse方法中有可迭代 ...
- selenium在scrapy中的使用、UA池、IP池的构建
selenium在scrapy中的使用流程 重写爬虫文件的构造方法__init__,在该方法中使用selenium实例化一个浏览器对象(因为浏览器对象只需要被实例化一次). 重写爬虫文件的closed ...
随机推荐
- kafka7 探索生产者同步or异步发送消息
1.生产者:在发送完消息后,收到回执确认. 主要是在SimpleProducer.java中修改了发送消息的2行代码,用到了回调函数,修改如下: //发送消息 ProducerRecord<St ...
- [js]函数的上级作用域,他的上级作用域就是谁,跟函数在哪执行的没什么关系.
函数的上级作用域,他的上级作用域就是谁,跟函数在哪执行的没什么关系. <script> //如何查找上级作用域? //看函数在哪个作用域下定义的,他的上级作用域就是谁. 跟函数在哪执行的没 ...
- (转)Golang--使用iota(常量计数器)
iota是golang语言的常量计数器,只能在常量的表达式中使用. iota在const关键字出现时将被重置为0(const内部的第一行之前),const中每新增一行常量声明将使iota计数一次(io ...
- python+requests+excel+unittest+ddt接口自动化数据驱动并生成html报告
1.环境准备: python3.6 requests xlrd openpyxl HTMLTestRunner_api 2.目前实现的功能: 封装requests请求方法 在excel填写接口请求参数 ...
- Spring框架第二天
## Spring框架第二天 ## ---------- **课程回顾:Spring框架第一天** 1. 概述 * IOC和AOP 2. 框架的IOC的入门 * 创建applicationContex ...
- 如何通过代码审计挖掘REDos漏洞
写这篇文章的目的一是由于目前网上关于java代码审计的资料实在是太少了,本人作为一个java代码审计的新手,深知学习java代码审计的难受之处,所以将自己学习过程中挖掘的一些漏洞写成博客发出来希望可以 ...
- Oracle 24角色管理
了解什么是角色 Oracle角色(role)就是一组权限(或者说是权限的集合). 用户可以给角色赋予指定的权限,然后将角色赋给相应的用户. 三种标准的角色 connect(连接角色) 拥有connec ...
- Docker 推送镜像到hub.docker
1.Docker镜像文件:lails.server.demo:1.0, 2.登录Docker:docker login[根据提示输入用户名/密码] 3.执行:docker push lails.ser ...
- python3内置的tkinter参数释疑
最近涉及到需要实现一个桌面UI的小游戏,所以就翻看了一些文档. 当然有介绍使用pyQT5的,但是本机安装的是python3.4,不想卸载掉这个版本,暂时还不能使用pyQT5. pyQT5需要pytho ...
- cookie session 讲解
cookie: cookie的定义: cookie 是由web服务器保存在用户浏览器(客户端)上的小文本文件,它可以包含有关用户的信息,并且在每次请求时会携带保存的数据去访问服务器,所以cookie有 ...