设计模式:解释器(Interpreter)模式
设计模式:解释器(Interpreter)模式
一、前言
这是我们23个设计模式中最后一个设计模式了,大家或许也没想到吧,竟然是编译原理上的编译器,这样说可能不对,因为编译器分为几个部分组成呢,比如词法分析器、语法分析器、语义分析器、中间代码优化器以及最终的最终代码生成器。而这个解释器其实就是完成了对语法的解析,将一个个的词组解释成了一个个语法范畴,之后拿来使用而已。
为什么会有这个解释器模式呢,我想这是从编译原理中受到启发的,使用了这样的一个解释器可以在Java语言之上在定义一层语言,这种语言通过Java编写的解释器可以放到Java环境中去执行,这样如果用户的需求发生变化,比如打算做其他事情的时候,只用在自己定义的新的语言上进行修改,对于Java编写的代码不需要进行任何的修改就能在Java环境中运行,这是非常有用的。这就好像,虽然不管怎么编译,最终由中间代码生成最终代码(机器码)是依赖于相应的机器的。但是编译器却能理解高级语言和低级语言,无论高级语言的程序是怎么样编写的,编译器的代码是不用修改的,而解释器模式就是想做一个建立在Java和我们自定义语言之间的编译器。
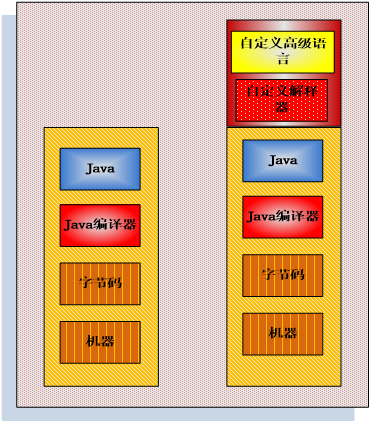
二、代码

本程序使用自顶向下文法来解析源程序:
首先是文法的定义:
1 <program> -> program <Command List>
2
3 <Command List> -> <Command>* end
4
5 <Command> -> <Repeat Command> | <Primitive Command>
6
7 <Repeat Command> -> repeat <number> <Command List>
8
9 <Primitive Command> -> go | right | left
由此可以生成一颗语法树。
然后使用自顶向下文法生成这样的语法树,自顶向下文法从根节点开始,不断的向下解析,遇到一个语法范畴就尝试着自己的定义去解析,直至解析到相应的程序,这里要注意二义性问题,不能尝试两种解析方式都能对源程序解析成功;在实现的时候将一个语法范畴定义为一个类,然后不断地递归的去解析,直至到了叶子节点,将所有的单词解析完毕。
Node抽象类:
package zyr.dp.interpreter;
public abstract class Node {
public abstract void parse(Context context) throws ParseException;
}
ProgramNode:起始节点 <program> -> program <Command List>
package zyr.dp.interpreter;
public class ProgramNode extends Node {
private Node commandListNode;
public void parse(Context context) throws ParseException {
context.skipToken("program");
commandListNode=new CommandListNode();
commandListNode.parse(context);
}
public String toString(){
return "[program "+commandListNode+"]";
}
}
CommandListNode类: <Command List> -> <Command>* end
package zyr.dp.interpreter;
import java.util.ArrayList;
public class CommandListNode extends Node {
private ArrayList list=new ArrayList();
public void parse(Context context) throws ParseException {
while(true){
if(context.getCurrentToken()==null){
throw new ParseException("错误!!!"+"当前字符为空");
}else if(context.getCurrentToken().equals("end")){
context.skipToken("end");
break;
}else{
Node commandNode=new CommandNode();
commandNode.parse(context);
list.add(commandNode);
}
}
}
public String toString(){
return list.toString();
}
}
CommandNode类: <Command> -> <Repeat Command> | <Primitive Command>
package zyr.dp.interpreter;
public class CommandNode extends Node {
private Node node;
public void parse(Context context) throws ParseException {
if(context.getCurrentToken().equals("repeat")){
node = new RepeatCommandNode();
node.parse(context);
}else{
node = new PrimitiveCommandNode();
node.parse(context);
}
}
public String toString(){
return node.toString();
}
}
RepeatCommandNode 类:<Repeat Command> -> repeat <number> <Command List>
package zyr.dp.interpreter;
public class RepeatCommandNode extends Node {
private int number;
private Node commandListNode;
public void parse(Context context) throws ParseException {
context.skipToken("repeat");
number=context.currentNumber();
context.nextToken();
commandListNode=new CommandListNode();
commandListNode.parse(context);
}
public String toString(){
return "[repeat "+number+" "+commandListNode+"]";
}
}
PrimitiveCommandNode类:<Primitive Command> -> go | right | left
package zyr.dp.interpreter;
public class PrimitiveCommandNode extends Node {
String name;
public void parse(Context context) throws ParseException {
name=context.getCurrentToken();
context.skipToken(name);
if(!name.equals("go") && !name.equals("left") && !name.equals("right") ){
throw new ParseException("错误!!!非法字符:"+name);
}
}
public String toString(){
return name;
}
}
ParseException类:
package zyr.dp.interpreter;
public class ParseException extends Exception {
private static final long serialVersionUID = 3996163326179443976L;
public ParseException(String word){
super(word);
}
}
Context 类,承载了词法分析的职责,为上面的语法树提供单词,遍历程序,当然没考虑到程序的注释等处理信息。
package zyr.dp.interpreter;
import java.util.StringTokenizer;
public class Context {
private StringTokenizer tokenizer ;
private String currentToken;
public Context(String token){
tokenizer=new StringTokenizer(token);
nextToken();
}
public String nextToken() {
if(tokenizer.hasMoreTokens()){
currentToken=tokenizer.nextToken();
}else{
currentToken=null;
}
return currentToken;
}
public String getCurrentToken(){
return currentToken;
}
public void skipToken(String token) throws ParseException{
if(!token.equals(currentToken)){
throw new ParseException("错误!!!"+"期待"+currentToken+"但是却得到"+token);
}
nextToken();
}
public int currentNumber() throws ParseException{
int num=0;
try{
num=Integer.parseInt(currentToken);
}catch(NumberFormatException e){
throw new ParseException(e.toString());
}
return num;
}
}
Main类,读取用户编写的程序并且执行词法分析和语法分析。这里的词法分析就是简单的遍历程序,语法分析采用的自顶向下的语法分析,对于上下文无关文法可以检测到语法错误,并且能生成语法范畴,但是这些语法范畴是我们能看到的,不是及其最终可以拿来去处理的,真正要编写编译系统,最好使用,自下而上的算符优先文法等方式来分析。
package zyr.dp.text; import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException; import zyr.dp.interpreter.*; public class Main { public static void main(String[] args) { try {
BufferedReader reader = new BufferedReader(new FileReader("program.txt"));
String line=null;
while((line=reader.readLine())!=null){
System.out.println("源程序为:"+line);
System.out.println("自顶向下解析为:");
Node node=new ProgramNode();
node.parse(new Context(line));
System.out.println(node);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
} } }
运行结果:
源程序:
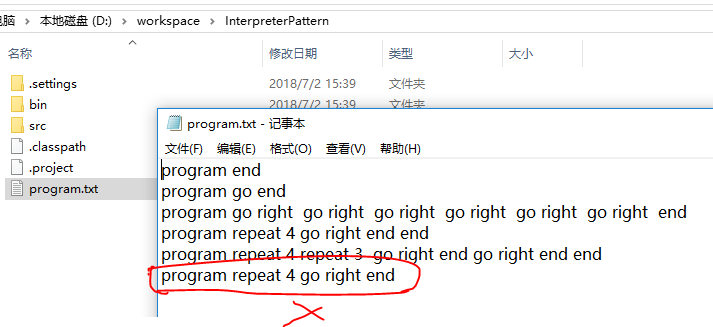
在这里我专门写错了一个源程序:
program end
program go end
program go right go right go right go right go right go right end
program repeat 4 go right end end
program repeat 4 repeat 3 go right end go right end end
6 program repeat 4 go right end

可以看到编译器检测到了语法错误,对于语法正确的,也形式化的生成了自己的分析结果,使用[ ]括起来的就是语法范畴了,形成层次递归嵌套结构。
三、总结
最后的设计模式是解释器模式,在Java这种高级语言之上再次定义一种语言的编译器,然后在不改动这个编译器的条件下,也就是不改变Java代码就能够随意的书写更高级的代码,然后执行。在这种模式之下java程序都不用修改,只用修改上面的文本文件就可以了,非常的方便,适合于结构已经固定,但是可以随意修改功能的场合。
设计模式:解释器(Interpreter)模式的更多相关文章
- python 设计模式之解释器(Interpreter)模式
#写在前面 关于解释器模式,我在网上转了两三圈,心中有了那么一点概念 ,也不知道自己理解的是对还是错. 其实关于每一种设计模式,我总想找出一个答案,那就是为什么要用这种设计模式, 如果不用会怎么样,会 ...
- [设计模式]解释器(Interpreter)之大胆向MM示爱吧
为方便读者,本文已添加至索引: 设计模式 学习笔记索引 写在前面 “我刚写了个小程序,需要你来参与下.”我把MM叫到我的电脑旁,“来把下面这条命令打进去,这是个练习打(Pian)符(ni)号(de)的 ...
- 设计模式:interpreter模式
理解:可以广义的理解为创造一种语言,实现该语言的解释器,然后用创造的语言编写程序 对比:如xml就是一种语言,解析xml的代码就是解释器 例子: //目标:定义4中几种命令,使用C++解析 //如下: ...
- Java设计模式(17)解释器模式(Interpreter模式)
Interpreter定义:定义语言的文法,并且建立一个解释器来解释该语言中的句子. Interpreter似乎使用面不是很广,它描述了一个语言解释器是如何构成的,在实际应用中,我们可能很少去构造一个 ...
- 面向对象设计模式之Interpreter解释器模式(行为型)
动机:在软件构建过程中 ,如果某一特定领域的问题比较复杂,类似的模式不断重复出现,如果使用普通的编程方式来实现将面临非常频繁的变化.在这种情况下,将特定领域的问题表达为某种语法规则的句子,然后构建一个 ...
- 设计模式---领域规则模式之解析器模式(Interpreter)
前提:领域规则模式 在特定领域内,某些变化虽然频繁,但可以抽象为某种规则.这时候,结合特定领域,将问题抽象为语法规则,从而给出该领域下的一般性解决方案. 典型模式 解析器模式:Interpreter ...
- Java设计模式----解释器模式
计算器中,我们输入“20 + 10 - 5”,计算器会得出结果25并返回给我们.可你有没有想过计算器是怎样完成四则运算的?或者说,计算器是怎样识别你输入的这串字符串信息,并加以解析,然后执行之,得出结 ...
- 设计模式(二十三)Interpreter模式
在Interpreter模式中,程序要解决的问题会被用非常简单的“迷你语言”表述出来,即用“迷你语言”编写的“迷你程序”把具体的问题表述出来.迷你程序是无法单独工作的,还需要用java语言编写一个负责 ...
- Java设计模式-享元模式(Flyweight)
享元模式的主要目的是实现对象的共享,即共享池,当系统中对象多的时候可以减少内存的开销,通常与工厂模式一起使用. FlyWeightFactory负责创建和管理享元单元,当一个客户端请求时,工厂需要检查 ...
- C#设计模式总结 C#设计模式(22)——访问者模式(Vistor Pattern) C#设计模式总结 .NET Core launch.json 简介 利用Bootstrap Paginator插件和knockout.js完成分页功能 图片在线裁剪和图片上传总结 循序渐进学.Net Core Web Api开发系列【2】:利用Swagger调试WebApi
C#设计模式总结 一. 设计原则 使用设计模式的根本原因是适应变化,提高代码复用率,使软件更具有可维护性和可扩展性.并且,在进行设计的时候,也需要遵循以下几个原则:单一职责原则.开放封闭原则.里氏代替 ...
随机推荐
- Js正则Replace方法
JS正则的创建有两种方式: new RegExp() 和 直接字面量. //使用RegExp对象创建 var regObj = new RegExp("(^\s+)|(\s+$)" ...
- oracle dump的使用心得
使用DS开发的时候,有的时候会遇到一个问题:数据库层面定义的空格与DS自已定义的空格概念不一致,导致生成的数据会有一定的问题. 举例来说: 在数据库里面定义CHAR(20),如果插入的字符不足20的时 ...
- LinuxShell脚本编程7-for和while
1.for的使用 #! /bin/bash ` do echo $a done 表示:a初始值为1,然后a=a+2的操作,一直到a<=10为止 for((i=1;i<=10;i=i+2)) ...
- 【Javascript】Javascript原型与继承
一切都是对象! 以下的四种(undefined, number, string, boolean)属于简单的值类型,不是对象.剩下的几种情况——函数.数组.对象.null.new Number(10) ...
- unity Socket TCP连接案例(一)
非常清晰的demo 服务端 using System; using System.Collections; using System.Collections.Generic; using System ...
- JS中的事件冒泡和事件捕获
事件捕获阶段:事件从最上一级标签开始往下查找,直到捕获到事件目标(target). 事件冒泡阶段:事件从事件目标(target)开始,往上冒泡直到页面的最上一级标签. 用图示表示如下: 1.冒泡事件: ...
- 数据结构与算法(C++)大纲
1.栈 栈的核心是LIFO(Last In First Out),即后进先出 出栈和入栈只会对栈顶进行操作,栈底永远为0 1.1概念 栈底(bottom):栈结构的首部 栈顶(top):栈结构的尾部 ...
- [java源码解析]对HashMap源码的分析(二)
上文我们讲了HashMap那骚骚的逻辑结构,这一篇我们来吹吹它的实现思想,也就是算法层面.有兴趣看下或者回顾上一篇HashMap逻辑层面的,可以看下HashMap源码解析(一).使用了哈希表得“拉链法 ...
- bitbucket 源代码托管
5个人以下可以免费使用,不限制仓库的数量; 国外的注册需要开启蓝灯FQ; 1.注册账号 maanshancss w1-g1@qq.com;创建仓库; 然后拷贝现有项目 然后提交 然后push; 2.写 ...
- 解决 Java 调用 Azure SDK 证书错误 javax.net.ssl.SSLHandshakeException
Azure 作为微软的公有云平台,提供了非常丰富的 SDK 和 API 让开发人员可以非常方便的调用的各项服务,目前除了自家的 .NET.Java.Python. nodeJS.Ruby,PHP 等语 ...