【spark】示例:二次排序
我们有这样一个文件



首先我们的思路是把输入文件数据转化成键值对的形式进行比较不就好了嘛!
但是你要明白这一点,我们平时所使用的键值对是不具有比较意义的,也就说他们没法拿来直接比较。
我们可以通过sortByKey,sortBy(pair._2)来进行单列的排序,但是没法进行两列的同时排序。
那么我们该如何做呢?
我们可以自定义一个键值对的比较类来实现比较,
类似于JAVA中自定义类实现可比较性实现comparable接口。
我们需要继承Ordered和Serializable特质来实现自定义的比较类。
1.读取数据创建rdd

2.根据要求来定义比较类
任务要求,先根据key进行排序,相同再根据value进行排序。
我们可以把键值对当成一个数据有两个数字,先通过第一个数字比大小,再通过第二个数字比大小。
(1)我们定义两个Int参数的比较类
(2)继承Ordered 和 Serializable 接口 实现 compare 方法实现可以比较
class UDFSort (val first:Int,val second:Int) extends Ordered[UDFSort] with Serializable {
override def compare(that: UDFSort): Int = {
if(this.first - that.first != 0){//第一个值不相等的时候,直接返回大小
this.first - that.first //返回值
}
else {//第一个值相等的时候,比较第二个值
this.second - that.second
}
}
}
其实,懂java的人能看出来这个跟实现comparable很类似。
3.处理rdd
我们将原始数据按照每行拆分成一个含有两个数字的数组,然后传入我们自定义的比较类中
不是可以通过UDFSort就可以比较出结果了吗,
但是我们不能把结果给拆分掉,也就是说,我们只能排序,不能改数据。
我们这样改怎么办?
我们可以生成键值对的形式,key为UDFSort(line(0),line(1)),value为原始数据lines。
这样,我们通过sortByKey就能完成排序,然后通过取value就可以保持原始数据不变。
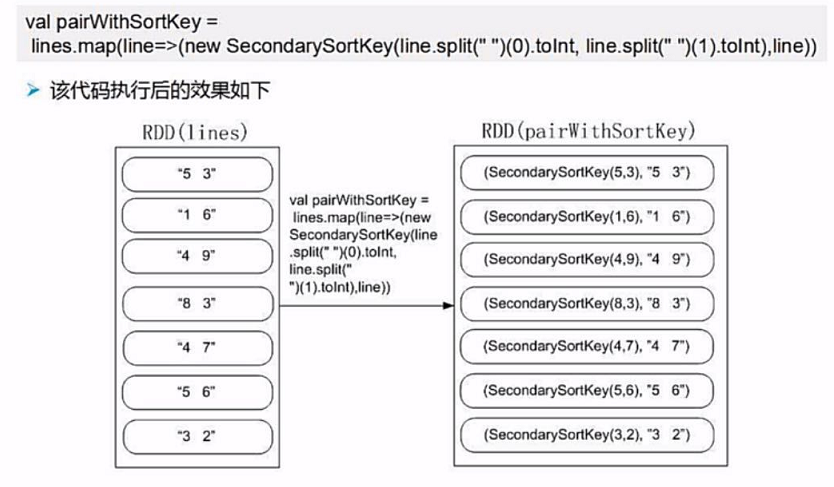
4.排序取结果

完整代码
package SparkDemo
import org.apache.spark.{SparkConf, SparkContext}
class UDFSort (val first:Int,val second:Int) extends Ordered[UDFSort] with Serializable {//自定义比较类
override def compare(that: UDFSort): Int = {
if(this.first - that.first != 0){//第一个值不相等的时候,直接返回大小
this.first - that.first //返回值
}
else {//第一个值相等的时候,比较第二个值
this.second - that.second
}
}
}
object Sort{
def main(args:Array[String]): Unit ={
//初始化配置:设置主机名和程序主类的名字
val conf = new SparkConf().setAppName("UdfSort");
//通过conf来创建sparkcontext
val sc = new SparkContext(conf);
val lines = sc.textFile("file:///...")
//转换为( udfsort( line(0),line(1) ),line ) 的形式
val pair = lines.map(line => (new UDFSort(line.split(" ")(0).toInt,line.split(" ")(1).toInt),line))
//对key进行排序,然后取value
val result = pair.sortByKey().map( x => x._2)
}
}
【spark】示例:二次排序的更多相关文章
- 分别使用Hadoop和Spark实现二次排序
零.序(注意本部分与标题无太大关系,可直接调至第一部分) 既然没用为啥会有序?原因不想再开一篇文章,来抒发点什么感想或者计划了,就在这里写点好了: 前些日子买了几本书,打算学习和研究大数据方面的知识, ...
- spark的二次排序
通过scala实现二次排序 package _core.SortAndTopN import org.apache.spark.{SparkConf, SparkContext} /** * Auth ...
- Spark实现二次排序
一.代码实现 package big.data.analyse.scala.secondsort import org.apache.log4j.{Level, Logger} import org. ...
- Spark基础排序+二次排序(java+scala)
1.基础排序算法 sc.textFile()).reduceByKey(_+_,).map(pair=>(pair._2,pair._1)).sortByKey(false).map(pair= ...
- spark函数sortByKey实现二次排序
最近在项目中遇到二次排序的需求,和平常开发spark的application一样,开始查看API,编码,调试,验证结果.由于之前对spark的API使用过,知道API中的sortByKey()可以自定 ...
- 详细讲解MapReduce二次排序过程
我在15年处理大数据的时候还都是使用MapReduce, 随着时间的推移, 计算工具的发展, 内存越来越便宜, 计算方式也有了极大的改变. 到现在再做大数据开发的好多同学都是直接使用spark, hi ...
- Spark(二)算子详解
目录 Spark(二)算子讲解 一.wordcountcount 二.编程模型 三.RDD数据集和算子的使用 Spark(二)算子讲解 @ 一.wordcountcount 基于上次的wordcoun ...
- MapReduce二次排序
默认情况下,Map 输出的结果会对 Key 进行默认的排序,但是有时候需要对 Key 排序的同时再对 Value 进行排序,这时候就要用到二次排序了.下面让我们来介绍一下什么是二次排序. 二次排序原理 ...
- Hadoop Mapreduce分区、分组、二次排序过程详解[转]
原文地址:Hadoop Mapreduce分区.分组.二次排序过程详解[转]作者: 徐海蛟 教学用途 1.MapReduce中数据流动 (1)最简单的过程: map - reduce (2) ...
- Hadoop.2.x_高级应用_二次排序及MapReduce端join
一.对于二次排序案例部分理解 1. 分析需求(首先对第一个字段排序,然后在对第二个字段排序) 杂乱的原始数据 排序完成的数据 a,1 a,1 b,1 a,2 a,2 [排序] a,100 b,6 == ...
随机推荐
- django之单表操作
1.查询方法: <1> all(): 查询所有结果 <2> filter(**kwargs): 它包含了与所给筛选条件相匹配的对象 <3> get(**kwargs ...
- (转)Android工程出现 java.lang.NoClassDefFoundError错误解决方法
在Eclipse中,导入Android工程,工程没有报错,运行时,出现 java.lang.NoClassDefFoundError类没有找到的错误.从问题上可以看出是导入包出错的原因.遂百度加谷歌. ...
- 初级dba学习之路参考
今天周一拖着疲惫的身躯 11点才离开公司,回到家估计写完这篇博客就要17号了. 一个人走在回家的路上,很黑,突然很多感触,一个人在北京拼搏,不敢停止学习的脚步,因为只要停下来就会感觉到孤独. 回顾一下 ...
- 关于java.lang.NoSuchMethodError: org.slf4j.spi.LocationAwareLogger.log
配置JFinal环境时,jar包已导入,web.xml已配置,Config也已经配置好,测试服务器时不停地出现 Exception in thread "main" java.la ...
- php foreach函数的用法
php foreach函数用法举例. Foreach 函数(PHP4/PHP5) foreach 语法结构提供了遍历数组的简单方式. foreach 仅能够应用于数组和对象,如果尝试应用于其他数据类 ...
- LifecycleProcessor not initialized - call 'refresh' before invoking lifecycle methods via the context: --异常记录
升级了JDK之后,启动应用,直接抛出此异常.网上搜罗半天,没有正确的解决方案. 然后想到了是“升级了JDK”,重新检查所有JDK相关的配置的地方,在Debug Configurations里找到启动时 ...
- (转)Nginx反向代理设置 从80端口转向其他端口
from :http://www.cnblogs.com/wuyou/p/3455381.html Nginx反向代理设置 从80端口转向其他端口 反向代理(Reverse Proxy)方式是指以 ...
- 《Spring Boot 实战》随记
第一部分 Spring 4.x 1. Spring基础 略过 2. Spring常用配置 2.1 Bean的scope 使用@Scope注解配置scope.默认signleton,原型模式protot ...
- PAT 天梯赛 L1-008. 求整数段和 【水】
题目链接 https://www.patest.cn/contests/gplt/L1-008 AC代码 #include <iostream> #include <cstdio&g ...
- addEventListener和attachEvent介绍, 原生js和jquery的兼容性写法
也许很多同仁一听到事件监听,第一想到的就是原生js的 addEventListener()事件,的确如此,当然如果只是适用于现代浏览器(IE9.10.11 | ff, chorme, safari, ...