【spark】示例:二次排序
我们有这样一个文件



首先我们的思路是把输入文件数据转化成键值对的形式进行比较不就好了嘛!
但是你要明白这一点,我们平时所使用的键值对是不具有比较意义的,也就说他们没法拿来直接比较。
我们可以通过sortByKey,sortBy(pair._2)来进行单列的排序,但是没法进行两列的同时排序。
那么我们该如何做呢?
我们可以自定义一个键值对的比较类来实现比较,
类似于JAVA中自定义类实现可比较性实现comparable接口。
我们需要继承Ordered和Serializable特质来实现自定义的比较类。
1.读取数据创建rdd

2.根据要求来定义比较类
任务要求,先根据key进行排序,相同再根据value进行排序。
我们可以把键值对当成一个数据有两个数字,先通过第一个数字比大小,再通过第二个数字比大小。
(1)我们定义两个Int参数的比较类
(2)继承Ordered 和 Serializable 接口 实现 compare 方法实现可以比较
class UDFSort (val first:Int,val second:Int) extends Ordered[UDFSort] with Serializable {
override def compare(that: UDFSort): Int = {
if(this.first - that.first != 0){//第一个值不相等的时候,直接返回大小
this.first - that.first //返回值
}
else {//第一个值相等的时候,比较第二个值
this.second - that.second
}
}
}
其实,懂java的人能看出来这个跟实现comparable很类似。
3.处理rdd
我们将原始数据按照每行拆分成一个含有两个数字的数组,然后传入我们自定义的比较类中
不是可以通过UDFSort就可以比较出结果了吗,
但是我们不能把结果给拆分掉,也就是说,我们只能排序,不能改数据。
我们这样改怎么办?
我们可以生成键值对的形式,key为UDFSort(line(0),line(1)),value为原始数据lines。
这样,我们通过sortByKey就能完成排序,然后通过取value就可以保持原始数据不变。
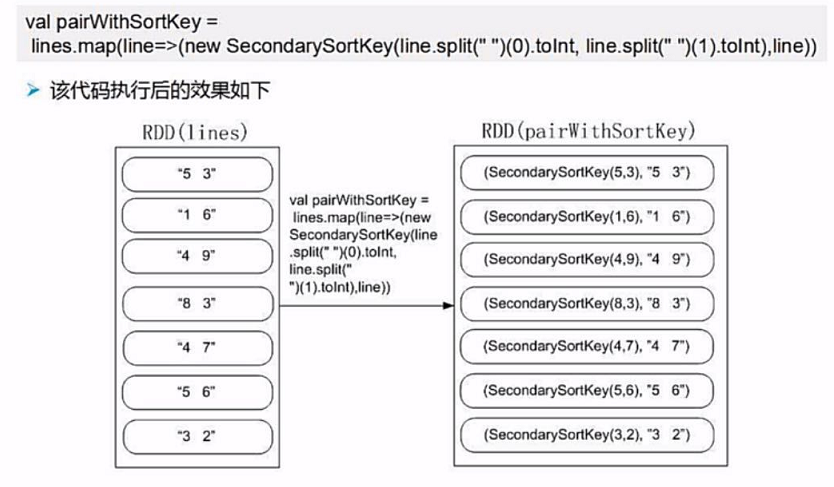
4.排序取结果

完整代码
package SparkDemo
import org.apache.spark.{SparkConf, SparkContext}
class UDFSort (val first:Int,val second:Int) extends Ordered[UDFSort] with Serializable {//自定义比较类
override def compare(that: UDFSort): Int = {
if(this.first - that.first != 0){//第一个值不相等的时候,直接返回大小
this.first - that.first //返回值
}
else {//第一个值相等的时候,比较第二个值
this.second - that.second
}
}
}
object Sort{
def main(args:Array[String]): Unit ={
//初始化配置:设置主机名和程序主类的名字
val conf = new SparkConf().setAppName("UdfSort");
//通过conf来创建sparkcontext
val sc = new SparkContext(conf);
val lines = sc.textFile("file:///...")
//转换为( udfsort( line(0),line(1) ),line ) 的形式
val pair = lines.map(line => (new UDFSort(line.split(" ")(0).toInt,line.split(" ")(1).toInt),line))
//对key进行排序,然后取value
val result = pair.sortByKey().map( x => x._2)
}
}
【spark】示例:二次排序的更多相关文章
- 分别使用Hadoop和Spark实现二次排序
零.序(注意本部分与标题无太大关系,可直接调至第一部分) 既然没用为啥会有序?原因不想再开一篇文章,来抒发点什么感想或者计划了,就在这里写点好了: 前些日子买了几本书,打算学习和研究大数据方面的知识, ...
- spark的二次排序
通过scala实现二次排序 package _core.SortAndTopN import org.apache.spark.{SparkConf, SparkContext} /** * Auth ...
- Spark实现二次排序
一.代码实现 package big.data.analyse.scala.secondsort import org.apache.log4j.{Level, Logger} import org. ...
- Spark基础排序+二次排序(java+scala)
1.基础排序算法 sc.textFile()).reduceByKey(_+_,).map(pair=>(pair._2,pair._1)).sortByKey(false).map(pair= ...
- spark函数sortByKey实现二次排序
最近在项目中遇到二次排序的需求,和平常开发spark的application一样,开始查看API,编码,调试,验证结果.由于之前对spark的API使用过,知道API中的sortByKey()可以自定 ...
- 详细讲解MapReduce二次排序过程
我在15年处理大数据的时候还都是使用MapReduce, 随着时间的推移, 计算工具的发展, 内存越来越便宜, 计算方式也有了极大的改变. 到现在再做大数据开发的好多同学都是直接使用spark, hi ...
- Spark(二)算子详解
目录 Spark(二)算子讲解 一.wordcountcount 二.编程模型 三.RDD数据集和算子的使用 Spark(二)算子讲解 @ 一.wordcountcount 基于上次的wordcoun ...
- MapReduce二次排序
默认情况下,Map 输出的结果会对 Key 进行默认的排序,但是有时候需要对 Key 排序的同时再对 Value 进行排序,这时候就要用到二次排序了.下面让我们来介绍一下什么是二次排序. 二次排序原理 ...
- Hadoop Mapreduce分区、分组、二次排序过程详解[转]
原文地址:Hadoop Mapreduce分区.分组.二次排序过程详解[转]作者: 徐海蛟 教学用途 1.MapReduce中数据流动 (1)最简单的过程: map - reduce (2) ...
- Hadoop.2.x_高级应用_二次排序及MapReduce端join
一.对于二次排序案例部分理解 1. 分析需求(首先对第一个字段排序,然后在对第二个字段排序) 杂乱的原始数据 排序完成的数据 a,1 a,1 b,1 a,2 a,2 [排序] a,100 b,6 == ...
随机推荐
- 面试常见的selenium问题
1.如何切换iframe 问题:如果你在一个default content中查找一个在iframe中的元素,那肯定是找不到的.反之你在一个iframe中查找另一个iframe元素或default co ...
- 缓存在中间件中的应用机制(Django)
缓存在中间件中的应用机制(Django) (右键图片:在新标签页中打开连接)
- mysql大数据查询优化
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索 ...
- rabbitmq channel参数详解【转】
1.Channel 1.1 channel.exchangeDeclare(): type:有direct.fanout.topic三种durable:true.false true:服务器重启会保留 ...
- ionic真机调试Android报错 - could not read ok from ADB Server * failed to start daemon * error: cannot connect to daemon
在使用真机调试Android程序时,报错如下: could not read ok from ADB Server * failed to start daemon error: cannot con ...
- Java集合(9):ConcurrentHashMap
一.ConcurrentHashMap介绍 我们可以在单线程时使用HashMap提高效率,而多线程时用Hashtable来保证安全.但是,HashMap中未进行同步考虑,而Hashtable则使用了s ...
- 60. Permutation Sequence(求全排列的第k个排列)
The set [1,2,3,…,n] contains a total of n! unique permutations. By listing and labeling all of the p ...
- 129. Sum Root to Leaf Numbers(从根节点加到叶子节点的和)
Given a binary tree containing digits from 0-9 only, each root-to-leaf path could represent a numb ...
- try-catch-finally的问题
参考: https://blog.csdn.net/chengzhezhijian/article/details/17264531 面试一家公司的面试题,注: 那个面试官对这个问题挺看重的(可是我回 ...
- AMBA总线基础知识简介
AMBA:Advanced Microcontroller Bus Architecture,是ARMA公司的片内互联总线协议. 1995 - AMBA1.0 APB外设总线及ASB系统总线发布. 1 ...