RocketMQ读书笔记5——消息队列的核心机制
【Broker简述】
Broker是RocketMQ的核心,大部分“重量级”的工作都是由Broker完成的,包括:
1.接受Producer发过来的消息;
2.处理Consumer的消费信息请求;
3.消息的持久化存储;
4.消息的HA机制;
5.服务端的过滤功能。
【消息存储】
分布式消息队列因为有高可靠性的要求,所以数据要通过磁盘进行持久化存储。
RocketMQ的消息是存储到磁盘上的,这样既可以保证断电后恢复,也可以不受内存大小的限制。
[ 磁盘存储的“快”——顺序写 ]
磁盘存储,使用得当,磁盘的速度完全可以匹配上网络的数据传输速度,目前的高性能磁盘,顺序写速度可以达到600MB/s,超过了一般网卡的传输速度。
[ 磁盘存储的“慢”——随机写 ]
磁盘的随机写的速度只有100KB/s,和顺序写的性能差了好几个数量级。
【消息的存储结构】
RocketMQ的存储是由ConsumeQueue和CommitLog配合完成的。

RocketMQ的存储结构图
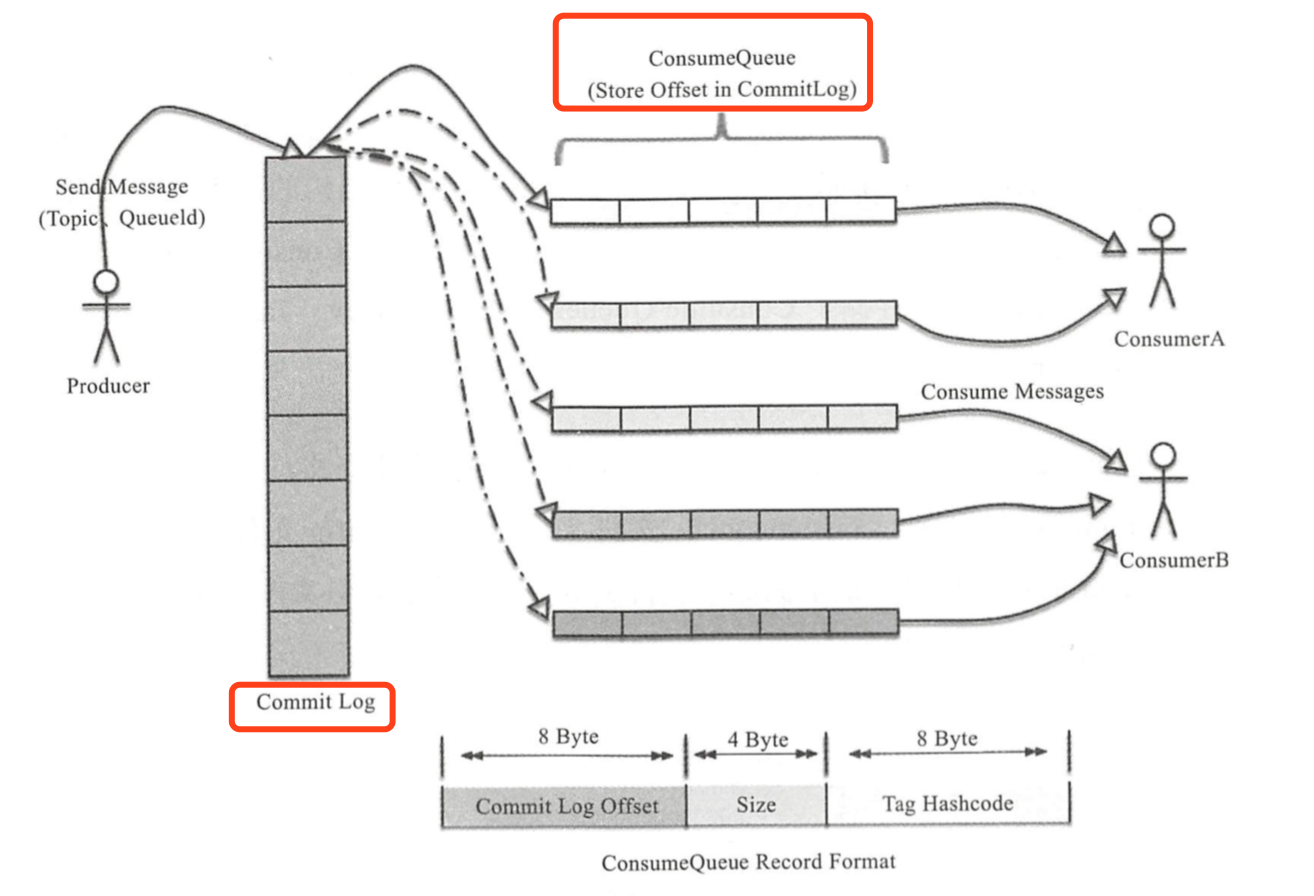
CommitLog以物理文件的方式存放,每台Broker上的CommitLog被本机器所有ConsumeQueue共享。
在CommitLog,一个消息的存储长度是不固定的,RocketMQ采用了一些机制,尽量向CommitLog中顺序写,但是随即读。
[ 存储机制这样设计的好处——顺序写,随机读 ]
1.CommitLog顺序写,可以大大提高写入的效率;
2.虽然是随机读,但是利用package机制,可以批量地从磁盘读取,作为cache存到内存中,加速后续的读取速度。
3.为了保证完全的顺序写,需要ConsumeQueue这个中间结构,因为ConsumeQueue里只存储偏移量信息,所以尺寸是有限的。在实际情况中,大部分ConsumeQueue能够被全部读入内存,所以这个中间结构的操作速度很快,可以认为是内存读取的速度。
[ 如何保证CommitLog和ConsumeQueue的一致性? ]
CommitLog里存储了Consume Queues、Message Queue、Tag等所有信息,即使ConsumeQueue丢失,也可以通过commitLog完全恢复出来。
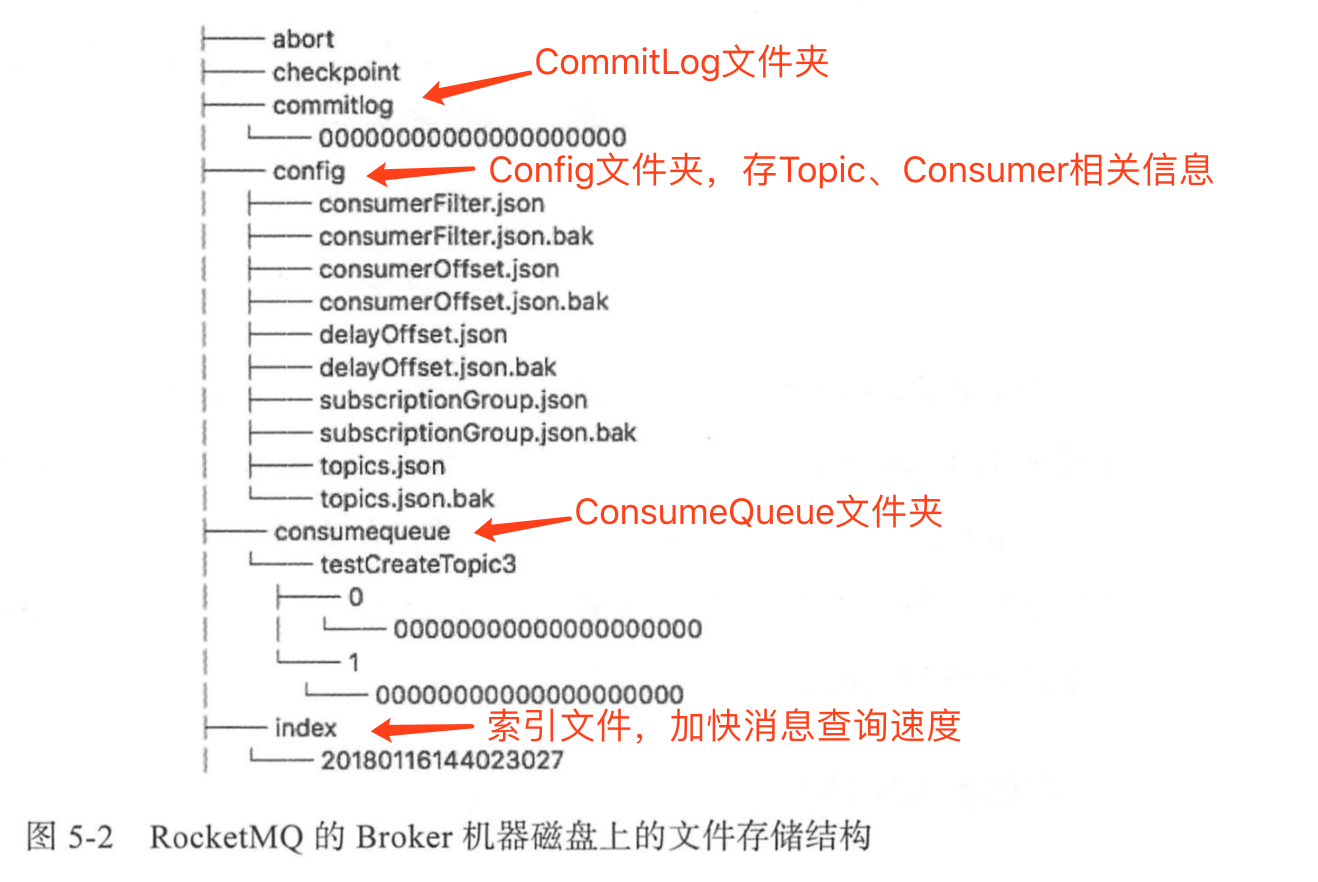
[ RocketMQ的Broker机器磁盘上的文件存储结构 ]
【高可用机制】
RocketMQ分布式集群通过Master和Slave机制达到高可用性。
[ 配置中如何区分Master和Slave? ]
在Broker的配置文件中
Master配置:
brokerId=
brokerRole=SYNC_MASTER
Slave配置:
brokerId= #slave的brokerId>0
brokerRole=SLAVE
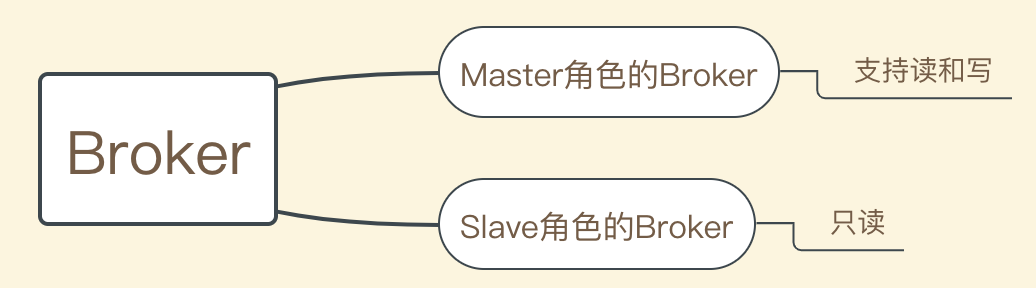
Producer只能向Master角色的Broker写消息。
Consumer可以从Master和Slave角色的Broker读消息。
[ 如何提高Producer和Consumer的高可用性? ]
1.Consumer端的高可用
在Consumer配置文件中,不需要设置是从Master还是Slave读,当Master不可用或者繁忙时,Consumer会被自动切换到从Slave读。
有了自动切换Consumer的机制,当一个Master角色的Broker出现故障,Consumer依然可以从Slave读取消息,不影响Consumer程序。
2.Producer端的高可用性
创建Topic的时候,把Topic的多个MessageQueue创建在多个Broker组上(Broker组:相同的Broker名称,不同的BrokerId组成一个Broker组。),这样当一个Broker组的Master不可用时,其他组的Master依然可用,Producer依然可以发消息。
[ RocketMQ是否支持把Slave自动转成Master? ]
目前不支持,如果机器资源不足,需要把Slave转成Master,则要手动停止Slave角色的Broker,更改配置文件,用新的配置文件启动Broker。
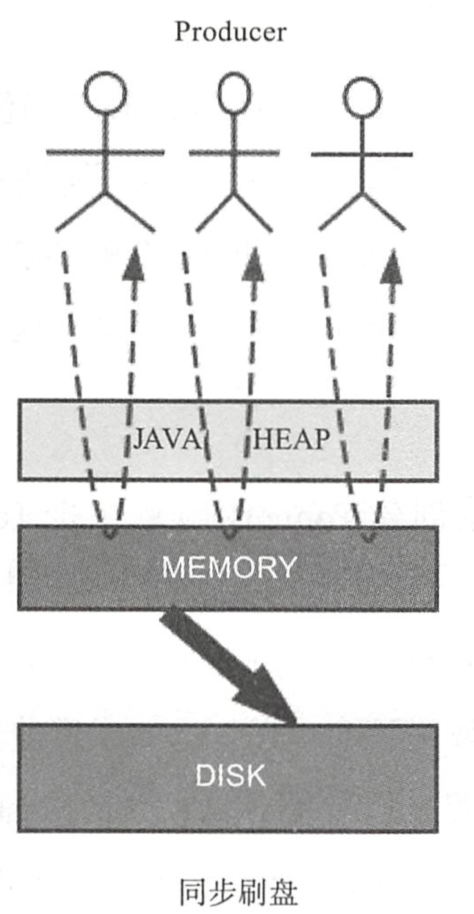
【重点:同步刷盘和异步刷盘】
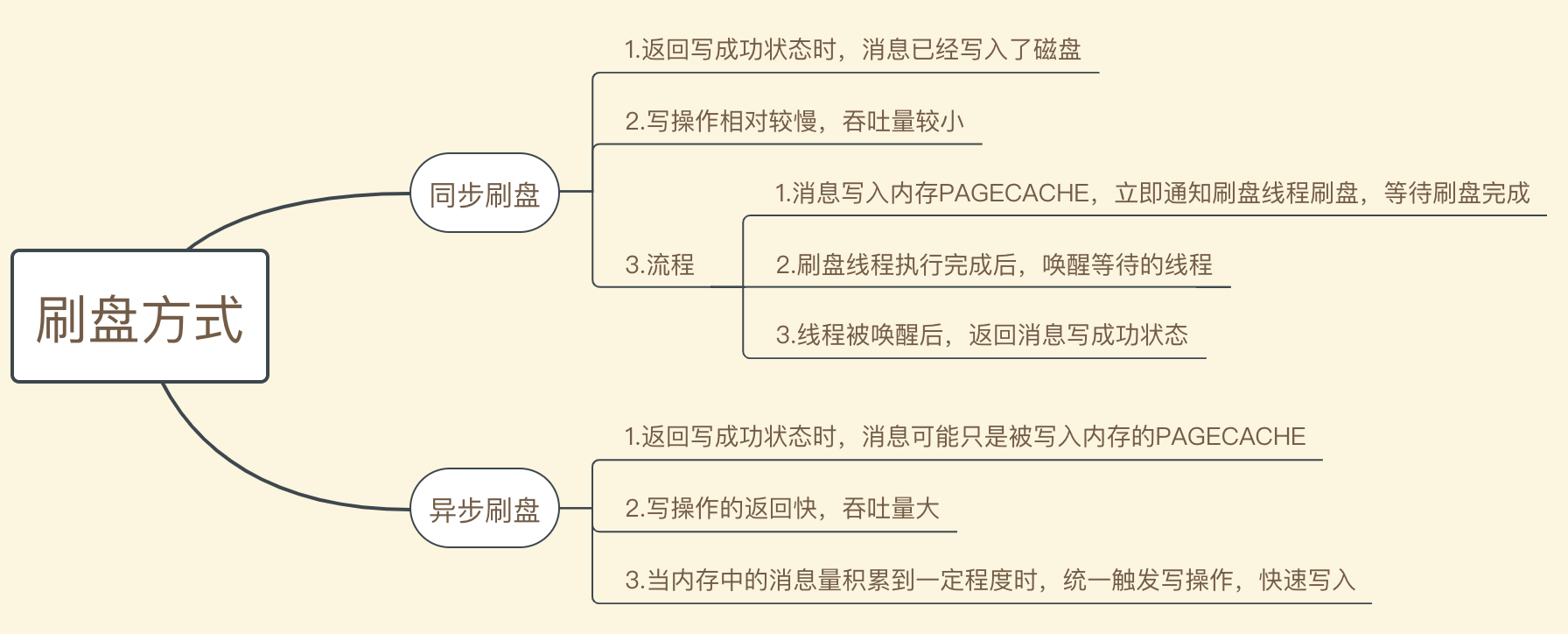
[ 同步刷盘 ]
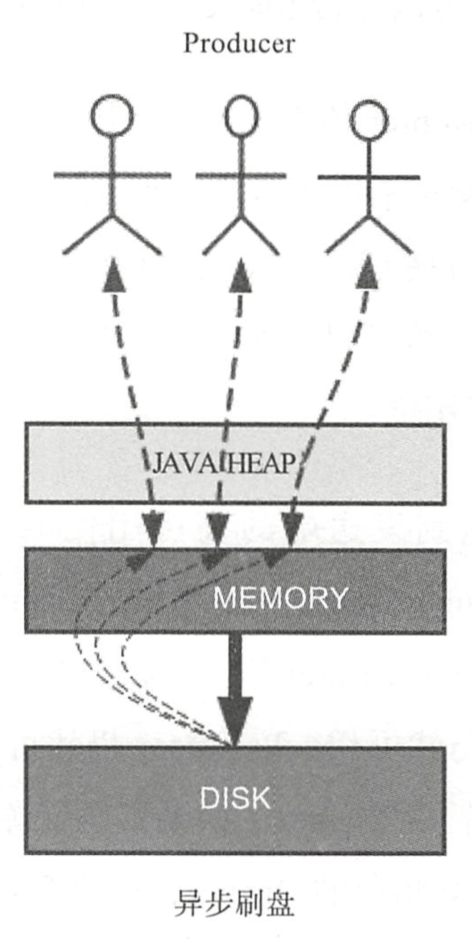
[ 异步刷盘 ]
[ 同步刷盘或异步刷盘的配置方式 ]
通过Broker配置文件中的flushDiskType参数设置。
flushDiskType=SYNC_FLUSH #同步刷盘
flushDiskType=ASYNC_FLUSH #异步刷盘
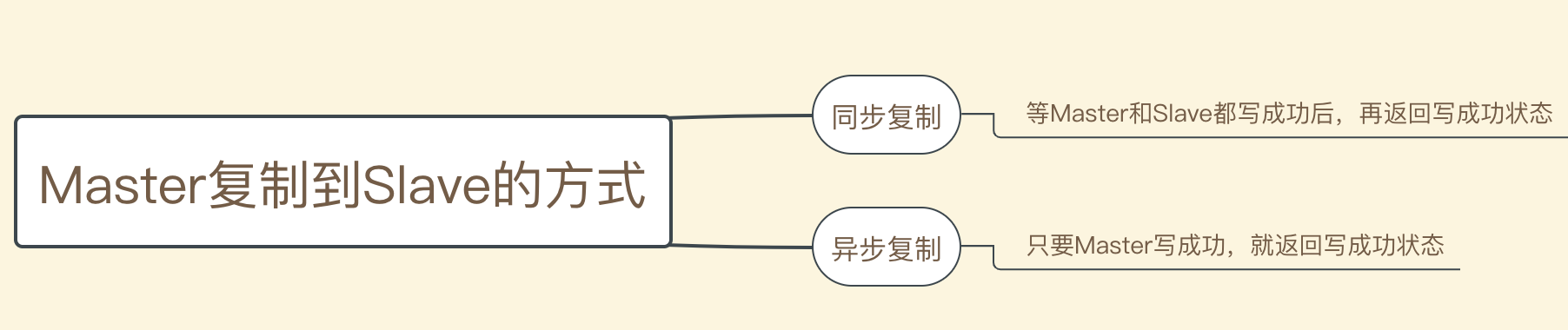
【 重点:同步复制和异步复制 】
如果一个Broker组有Master和Slave,消息需要从Master复制到Slave,有同步复制和异步复制两种方式。
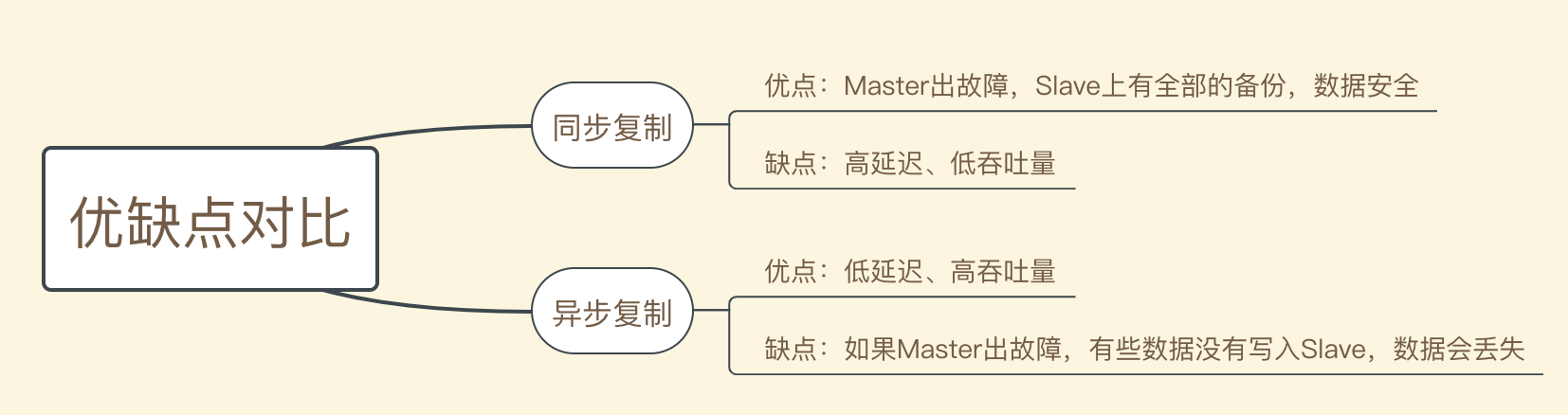
[ 同步、异步复制的优缺点对比 ]
[ 同步异步的配置方式 ]
在Broker的配置文件中的brokerRole参数进行配置:
brokerRole=ASYNC_MASTER #异步复制
brokerRole=SYNC_MASTER #同步复制
brokerRole=SALVE #对于Slave,只有一个参数可选
【小结:推荐的配置方式】
实际业务场景中,要合理设置刷盘方式和主从复制方式。
特别是刷盘方式中的SYNC_FLUSH方式,如果业务频繁地触发写操作,会明显降低性能。
通常情况下,会把Master和Slave的Broker均配置成ASYNC_FLUSH异步刷盘方式。
主从之间配置成SYNC_MASTER同步复制方式。
即:异步刷盘+同步复制
RocketMQ读书笔记5——消息队列的核心机制的更多相关文章
- 【mq读书笔记】消息队列负载与重新分配(分配 新队列pullRequest入队)
回顾PullMessageService#run: 如果队列总没有PullRequest对象,线程将阻塞. 围绕PullRequest有2个问题: 1.PullRequest对象在什么时候创建并加入p ...
- 高性能消息队列 CKafka 核心原理介绍(上)
欢迎大家前往腾讯云技术社区,获取更多腾讯海量技术实践干货哦~ 作者:闫燕飞 1.背景 Ckafka是基础架构部开发的高性能.高可用消息中间件,其主要用于消息传输.网站活动追踪.运营监控.日志聚合.流式 ...
- Linux进程间通信IPC学习笔记之消息队列(SVR4)
Linux进程间通信IPC学习笔记之消息队列(SVR4)
- 【mq读书笔记】消息确认(失败消息,定时队列重新消费)
接上文的集群模式,监听器返回RECONSUME_LATER,需要将将这些消息发送给Broker延迟消息.如果发送ack消息失败,将延迟5s后提交线程池进行消费. 入口:ConsumeMessageCo ...
- 【mq读书笔记】消息消费队列和索引文件的更新
ConsumeQueue,IndexFile需要及时更新,否则无法及时被消费,根据消息属性查找消息也会出现较大延迟. mq通过开启一个线程ReputMessageService来准时转发commitL ...
- RocketMQ读书笔记3——消费者
[不同类型的消费者] DefaultMQPushConsumer 由系统控制读取操作,收到消息后自动调用传入的处理方法来处理. DefaultMQPullConsumer 读取操作中的大部分功能由使用 ...
- 【mq读书笔记】消息拉取长轮训机制(Broker端)
RocketMQ并没有真正实现推模式,而是消费者主动想消息服务器拉取消息,推模式是循环向消息服务端发送消息拉取请求. 如果消息消费者向RocketMQ发送消息拉取时,消息未到达消费队列: 如果不启用长 ...
- 消息队列MQ核心原理全面总结(11大必会原理)
消息队列已经逐渐成为分布式应用场景.内部通信.以及秒杀等高并发业务场景的核心手段,它具有低耦合.可靠投递.广播.流量控制.最终一致性 等一系列功能. 无论是 RabbitMQ.RocketMQ.Act ...
- RocketMQ读书笔记4——NameServer(MQ的协调者)
[NameServer简述] 对于一个消息队列集群来说,系统由很多机器组成,每个机器的角色.IP地址都不相同,而且这些信息是变动的(如在某些情况下,会有新的Producer或Consumer加入). ...
随机推荐
- 6. Javscript学习笔记——BOM
6. BOM 6.1 widow对象 全局作用域: window是浏览器的一个实例 window对象同时扮演着ECMAScript中的Global对象的角色,因此所有在全局作用域中声明的变量.函数都会 ...
- centeros7安装docker
一.官方安装 https://docs.docker.com/install/linux/docker-ce/centos/#upgrade-docker-after-using-the-conven ...
- jmeter安装部署、maven路径配置
jmeter下载地址: https://jmeter.apache.org/download_jmeter.cgi 解压文件 配置jmeter环境变量 (1)设置jmeter解压目录的JMETER_H ...
- python+Selenium之操作滚动条
当我们做测试的时候,如果页面过长,就会定位元素失败,这时可以使用move_to_element方法跳到该元素的位置再操作: from selenium.webdriver.common.action_ ...
- Java_break与continue区别
使用场合不同 break:可以在switch case中使用,也可以在循环中使用 continue:只能在循环中使用,除了switch case 作用不同 break:表示中断,当在switch ...
- select for update和select for update wait和select for update nowait的区别
CREATE TABLE "TEST6" ( "ID" ), "NAME" ), "AGE" ,), "SEX ...
- Ubuntu 下常用的命令 简略记录
# 动态显示 NVIDIA watch -n 1 nvidia-smi #查看某一目录下文件的总数(不包含子目录) ls -l | wc -l #挂载硬盘或者U盘 mount /dev/sdb1 /m ...
- Ubuntu apache
Linux系统为Ubuntu 1. 启动apache服务 # /etc/init.d/apache2 start 2. 重启apache服务 # /etc/init.d/apache2 restart ...
- win10中VirtualBox联网设置
<分享>关于win10操作系统中VirtualBox无法桥接的解决方法 版权声明:本文为博主原创文章,未经博主允许不得转载. 升级win10,本来是一件很好的事,想好好体验一下新版本的感觉 ...
- java并发编程(2)线程池的使用
一.任务和执行策略之间的隐性耦合 Executor可以将任务的提交和任务的执行策略解耦 只有任务是同类型的且执行时间差别不大,才能发挥最大性能,否则,如将一些耗时长的任务和耗时短的任务放在一个线程池, ...