Hive--关联表(join)
在hive中,关联有4种方式:
- 内关联:join on
- 左外关联:left join on
- 右外关联:right join on
- 全外关联:full join on
另外还有一种可实现hive笛卡儿积的效果(hive不支持笛卡儿积): 在on后面接为true的表达式,如on 1=1(需先设置非严格模式:set hive.mapred.mode=nonstrict);
详细操作和结果如下:
如我有两个表:join1和join2,如下
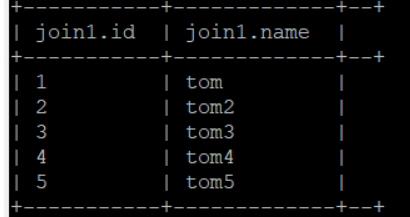
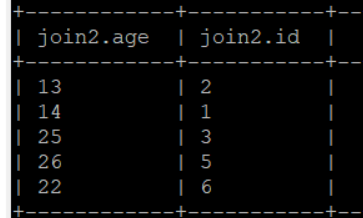
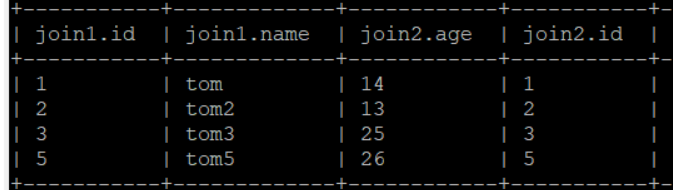
内关联:select * from jion1 join join2 on jion1.id = jion2.id;
- 作用:将表1和表2的字段id相同的内容 关联到一个表里。
- 效果如下:
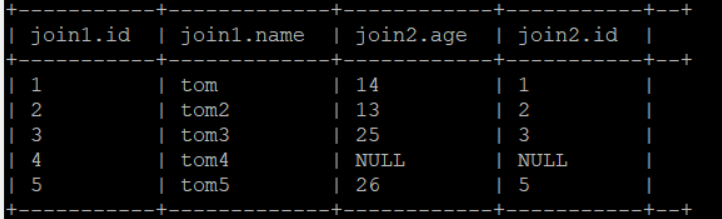
左外连接:select * from jion1 left join join2 on jion1.id = jion2.id;
- 作用:以join左边的表为标准进行连接(即保留左边表的字段值,右边表不符合on条件的用null表示)。
- 效果如下:
右外连接:select * from jion1 right join join2 on jion1.id = jion2.id;
- 作用:以join右边的表为标准进行连接(即保留右边表的字段值,左边表不符合on条件的用null表示)。
- 效果如下:
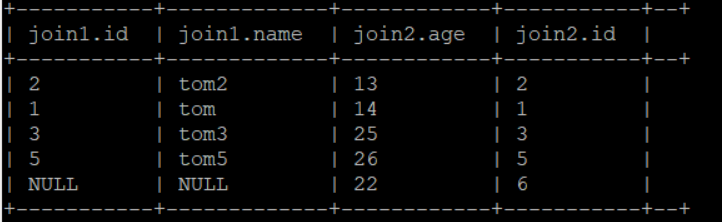
全外连接:select * from jion1 full join join2 on jion1.id = jion2.id;
- 作用:两个表连接,表留所有字段的值,不符合on条件的用null表示。
- 效果如下:

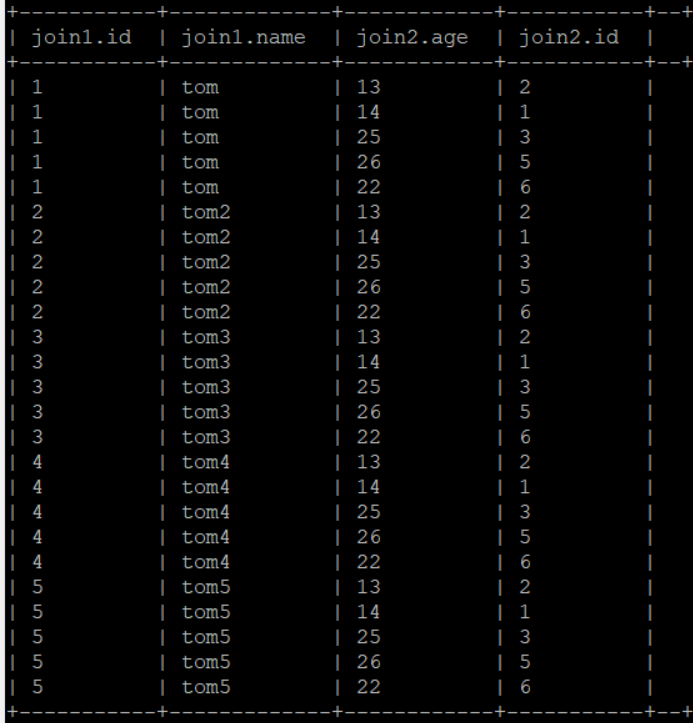
hive的”笛卡儿积“:select * from join1 join join2 on 1=1;
Hive--关联表(join)的更多相关文章
- hive中大表join
排序存储数据至BUCKETS,这样可以顺序进行join
- Hive中小表与大表关联(join)的性能分析【转】
Hive中小表与大表关联(join)的性能分析 [转自:http://blog.sina.com.cn/s/blog_6ff05a2c01016j7n.html] 经常看到一些Hive优化的建议中说当 ...
- hive中与hbase外部表join时内存溢出(hive处理mapjoin的优化器机制)
与hbase外部表(wizad_mdm_main)进行join出现问题: CREATE TABLE wizad_mdm_dev_lmj_edition_result as select * from ...
- hadoop系列 第二坑: hive hbase关联表问题
关键词: hive创建表卡住了 创建hive和hbase关联表卡住了 其实针对这一问题在info级别的日志下是看出哪里有问题的(为什么只能在debug下才能看见呢,不太理解开发者的想法). 以调试模式 ...
- 大数据开发实战:Hive优化实战3-大表join大表优化
5.大表join大表优化 如果Hive优化实战2中mapjoin中小表dim_seller很大呢?比如超过了1GB大小?这种就是大表join大表的问题.首先引入一个具体的问题场景,然后基于此介绍各自优 ...
- 大数据开发实战:Hive优化实战2-大表join小表优化
4.大表join小表优化 和join相关的优化主要分为mapjoin可以解决的优化(即大表join小表)和mapjoin无法解决的优化(即大表join大表),前者相对容易解决,后者较难,比较麻烦. 首 ...
- springboot中使用JOIN实现关联表查询
* 首先要确保你的表和想要关联的表有外键连接 repository中添加接口JpaSpecificationExecutor<?>,就可以使用springboot jpa 提供的API了. ...
- Hive优化-大表join大表优化
Hive优化-大表join大表优化 5.大表join大表优化 如果Hive优化实战2中mapjoin中小表dim_seller很大呢?比如超过了1GB大小?这种就是大表join大表的问题.首先引入一个 ...
- hive join 优化 --小表join大表
1.小.大表 join 在小表和大表进行join时,将小表放在前边,效率会高.hive会将小表进行缓存. 2.mapjoin 使用mapjoin将小表放入内存,在map端和大表逐一匹配.从而省去red ...
- mysql 中LIKE 与FIND_IN_SET 与关联表left join 速度效率比较
有一张表Table有IDStr字段,如下只显示二个字段还有很多其他字段 方式一 字段逗号分割,直接用UserIDStr字段,里面存多个ID用逗号分割 UUID UserIDStr 1111 1,2,3 ...
随机推荐
- 如何解决 Linux 虚拟机磁盘设备名不一致的问题
问题描述 在 Linux 虚拟机内,将附加的多块数据磁盘以设备名(/dev/sdxx)的方式创建文件系统,并将之写入 /etc/fstab 文件中实现启动自动挂载功能.但是在虚拟机重启之后,会随机出现 ...
- pt-heartbeat(percona toolkit)
pt-heartbeat是用来监控主从延迟的一款percona工具,现在我们大部分的MySQL架构还是基于主从复制,例如MHA,MMM,keepalived等解决方案.而主从环境的话,我们很关心的就是 ...
- js判断客户浏览器类型,版本
在JS中判断浏览器的 类型,估计是每个编辑过页面的开发人员都遇到过的问题.在众多的浏览器产品中,IE.Firefox.Opera.Safari........众多品牌 却标准不一,因此时常需要根据不同 ...
- 教你如何封装异步网络连接NSURLConnection实现带有百分比的下载
教你如何封装异步网络连接NSURLConnection实现带有百分比的下载 注:本教程需要你对block有着较为深刻的理解,且对如何封装对象有着一些经验. 也许你已经用惯了AFNetworking2. ...
- 通过CXF,开发rest协议接口
1. 引入cxf的jar包 pom文件里面直接增加依赖 < dependency> <groupId > junit</ groupId> <artifact ...
- Pinball Save Earth 正式上线
有问题或者建议大家可以联系我的QQ 914287516 或者qq邮箱 官方qq群 325631077:
- 更新UI的几种方式
在学习Handler的过程中牵涉到UI的更新,在这里就总结一下更新UI的四种方式吧,用法都比较简单,直接看代码就可以了. 一.使用Handler的post方法 新建项目,修改MainActivity代 ...
- how to design Programs 学习笔记
how to design Programs 学习笔记 */--> how to design Programs 学习笔记 目录 1. 前言 1.1. 系统化程序设计 1.2. 输入和输出 2. ...
- yolo2 anchor选择校招总结
使用kmeans的聚类算法选择数据集最可能的anchor size和ratio.K-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大. ...
- 记一次关于SSM框架的使用错误
今天遇到一个十分操蛋的问题,最后发现是因为忘记在对应的Service上加上@AutoWired. 难怪单元测试没问题,因为单元测试中用到的Service,其实现类通过DAO自动装配了.也就是在对应的s ...