ELMO及前期工作 and Transformer及相关论文
论文1
https://arxiv.org/pdf/1705.00108.pdf
Semi-supervised sequence tagging with bidirectional language models
理解序列标注中,如何使用动态embedding向量(bilstm)
1、上下文敏感 2、泛化能力增强
论文2
https://arxiv.org/pdf/1802.05365.pdf
Deep contextualized word representations
我感觉第一篇文章就是这篇文章的特例,上篇是将BILM的两个双向隐层去和task rnn的隐层组合,但是这篇文章的BILM是多层的,通过加权的方式把不同隐层的token表示和task rnn组合。
**BiLM在pre-train的时候,如何调整参数呢?-- LM的目标都是最大化概率预测下一个词,P(t1,t2,。。tk)=。。,所以在这样的目标下更新LM的参数
对LM的理解真的非常重要,感觉现在才真正弄懂了--
语言模型的评价目标:语言模型的计算的概率分布能够与真实的理想模型的概率分布可以相接近
常用的几个指标:交叉熵,困惑度
困惑度:其基本思想是给测试集的句子赋予较高概率值的语言模型较好,当语言模型训练完之后,测试集中的句子都是正常的句子,那么训练好的模型就是在测试集上的概率越高越好
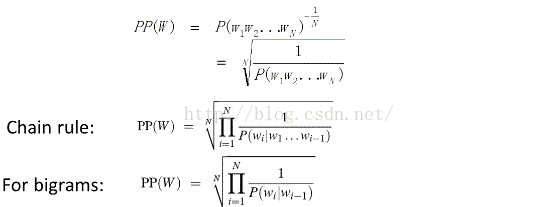
task rnn的训练的时候,BILM是fiexed,但是参数伽马和sj是需要不断调整的
名词解释:
context-independent : glove这些就是context independent的,但是经过rnn后就是上下文敏感的
We tie the parameters for both the token representation (Θx) and Softmax layer (Θs) in the forward and backward direction while maintaining separate parameters for the LSTMs in each direction. Overall, this formulation is similar to the approach of Peters et al. (2017), with the exception that we share some weights between directions instead of using completely independent parameters.
论文3
https://yq.aliyun.com/articles/601452
NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE
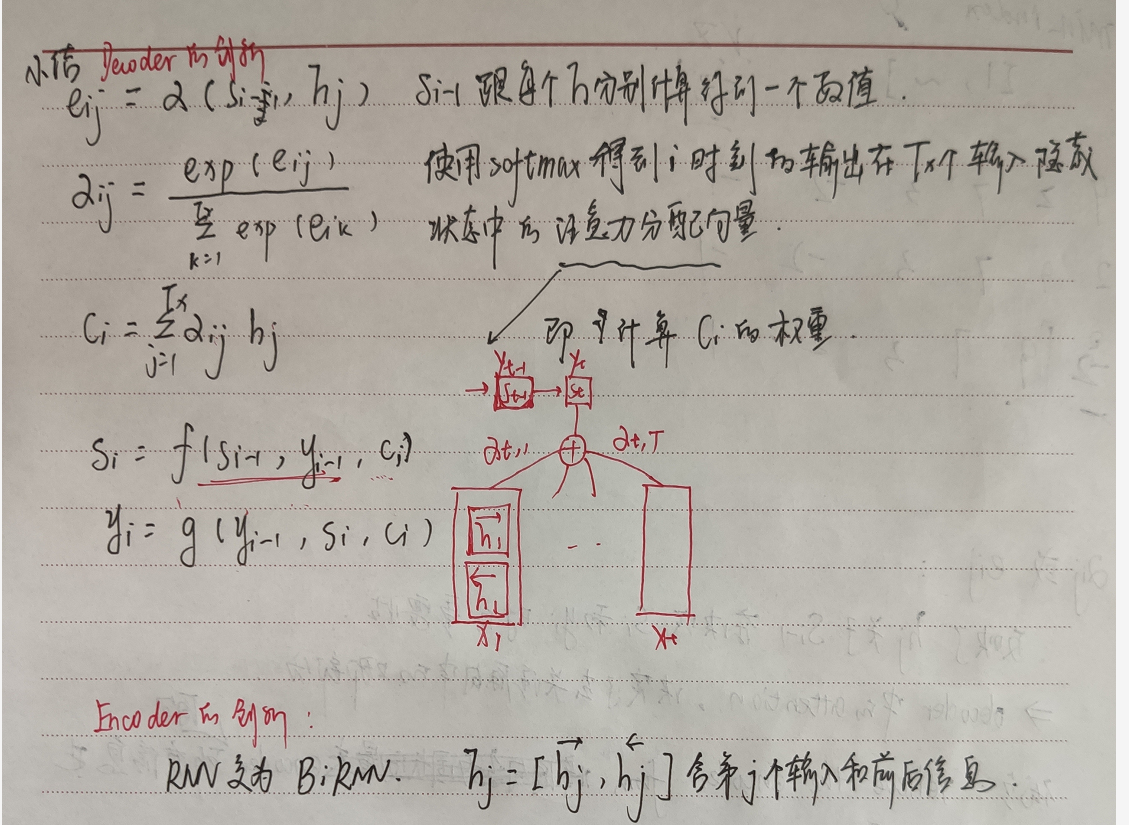
Instead, the alignment model directly computes a soft alignment, which allows the gradient of the cost function to be backpropagated through. This gradient can be used to train the alignment model as well as the whole translation model jointly


论文4
https://arxiv.org/pdf/1706.03762.pdf
Attention Is All You Need
主要介绍了transformer模型——
Transformer, a model architecture eschewing避开 recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output



2 background
sequential computation:the number of operations required to relate signals from two arbitrary input or output positions grows in the distance between positions,但是transformer可以将这种操作降低在常数级
end to end memory : are based on a recurrent attention mechanism instead of sequencealigned recurrence
transduction models
重点理解:
*multihead由8个part组成,得到concate的z后再去乘以W0,使得输出的维度和embedding相同 ;再去add andnormalize
*<转>将一个词的vector切分成h个维度,求attention相似度时每个h维度计算。由于单词映射在高维空间作为向量形式,每一维空间都可以学到不同的特征,相邻空间所学结果更相似,相较于全体空间放到一起对应更加合理。比如对于vector-size=512的词向量,取h=8,每64个空间做一个attention,学到结果更细化。
--我理解的是:上面的意思只是一个特例,h即head的个数不是固定的,但是Wk、Wq、Wv的作用可以让embedding的维度分成几个部分来分别看,这也就是不同的head所做的事情
*encoder会重复6次,也就是上个encoder的输出作为下一个encoder的输入,这时候就是可以把输出的z看作第一次的embedding,那么同样要去乘以新的Wk,Wq,Wv,得到这个encoder的k、q、v
*encoder的输出z,会经过新的K、V矩阵得到k、v,decoder自身的输出可能也会经过新的Q得到q,作为decoder的第三个sub-layer,是对encoder的输入进行attention计算
*残差层意思是说,x+经过multihead后的z
ELMO及前期工作 and Transformer及相关论文的更多相关文章
- 《基于Node.js实现简易聊天室系列之项目前期工作》
前期工作主要包括:项目的创建,web服务器的创建和数据库的连接. 项目创建 网上关于Node.js项目的创建的教程有很多,这里不必赘述.Demo所使用的Node.js的框架是express,版本为4. ...
- Kintinuous 相关论文 Volume Fusion 详解
近几个月研读了不少RGBD-SLAM的相关论文,Whelan的Volume Fusion系列文章的效果确实不错,而且开源代码Kintinuous结构清晰,易于编译和运行,故把一些学习时自己的理解和经验 ...
- sketch 相关论文
sketch 相关论文 Sketch Simplification We present a novel technique to simplify sketch drawings based on ...
- 图像识别的前期工作——使用pillow进行图像处理
pillow是个很好用的python图像处理库,可以到官方网站下载最新的文件.如果官网的任何PIL版本都不能与自己的python版本对应,或安装成功后发现运行出错,可以尝试从一个非官方的whl网站下载 ...
- Li的前期工作Level_Set_Evolution_Without_Re-initialization_A_New_Variational_Formulation
注意:因为页面显示原因.里头的公式没能做到完美显示,有须要的朋友请到我的资源中下载 无需进行又一次初始化的水平集演化:一个新的变分公式 Chunming Li , Chenyang Xu , Chan ...
- 硬杠后端(后端坑系列)——Django前期工作
Django是一个开放源代码的Web应用框架,由Python写成,采用了MVC的框架模式. MVC MVC是一种软件设计典范,用一种业务逻辑.数据.界面显示分离的方法组织代码,将业务逻辑聚集到一个部件 ...
- NODE 开发 2-3年工作经验 掌握的相关知识
文章 部分答案 内存
- YII配置rabbitMQ时前期工作各种坑
背景如下: 项目需要做一个订阅/发布的功能,然后一大堆讨论不做说明,确认使用rabbitMQ来做: okay,既然 要这个来做,我们下载这个东西吧!在官网上下载就okay了,不做说明,下载安装的时候会 ...
- haml scss转换编写html css的前期工作
http://www.w3cplus.com/sassguide/install.html 先下载ruby $ gem sources $ gem sources --remove https://r ...
随机推荐
- CSS 实现居中 + 清除浮动
一.水平居中 1.行内元素:text-align:center; 2.块级元素:margin:0 auto; 3.绝对定位和移动:absolute + transform 4.绝对定位和负边距:abs ...
- TimeUtil 工具类
/** * TODO * * @auther xh * @date 6/11/19 3:32 PM */ public class TimeUtil { public static final Str ...
- 9.SpringMVC注解式开发-处理器的请求映射规则的定义
1.对请求URI的命名空间的定义 @RequestMapping的value属性用于定义所匹配请求的URI.但对于注解在方法上和注解在类上, 其value 属性 所指定的URI,意义是不同的 一个@C ...
- go语言中regexp包中的函数和方法
// regexp.go ------------------------------------------------------------ // 判断在 b 中能否找到正则表达式 patter ...
- web开发:css总结与应用
一.常用标签的使用 二.边界圆角 三.背景样式 四.精灵图 五.盒模型布局细节 六.盒模型案例 七.w3c主页 一.常用标签的使用 <!DOCTYPE html> <html> ...
- Django_05_模板
模板 如何向请求者返回一个漂亮的页面呢?肯定需要用到html.css,如果想要更炫的效果还要加入js,问题来了,这么一堆字段串全都写到视图中,作为HttpResponse()的参数吗?这样定义就太麻烦 ...
- linux-2.6.38 input子系统(用输入子系统实现按键操作)
一.设备驱动程序 在上一篇随笔中已经分析,linux输入子系统分为设备驱动层.核心层和事件层.要利用linux内核中自带的输入子系统实现一个某个设备的操作,我们一般只需要完成驱动层的程序即可,核心层和 ...
- Spark学习(4)----ScalaTest
一.例子: 1.一个简单例子:https://www.jianshu.com/p/ceabf3437dd7 2.Funsuite例子:https://www.programcreek.com/scal ...
- vim 插件安装
一.pathogen简介 通常情况下安装vim插件,通常是将所有的插件和相关的doc文件都安装在中一文件夹中,如将插件全部安装在/usr/share/vim/vim73/plugin/目录下,将帮助文 ...
- 并发编程入门(一): POSIX 使用互斥量和条件变量实现生产者/消费者问题
boost的mutex,condition_variable非常好用.但是在Linux上,boost实际上做的是对pthread_mutex_t和pthread_cond_t的一系列的封装.因此通过对 ...